







 本文详细介绍了XGBoost的优化目标函数、如何学习每一棵树、通过泰勒公式展开推导过程,以及防止过拟合的策略。通过实例演示和高频面试题,帮助读者深入理解XGBoost的工作原理。
本文详细介绍了XGBoost的优化目标函数、如何学习每一棵树、通过泰勒公式展开推导过程,以及防止过拟合的策略。通过实例演示和高频面试题,帮助读者深入理解XGBoost的工作原理。
作者:wuli小萌哥
来源:算法研习社
XGBoost超详细推导,
终于有人讲明白了!
- XGB中树结点分裂的依据是什么?
- 如何计算树节点的权值?
- 为防止过拟合,XGB做了哪些改进?
相信看到这篇文章的各位对XGBoost都不陌生,的确,XGBoost不仅是各大数据科学比赛的必杀武器,在实际工作中,XGBoost也在被各大公司广泛地使用。
如今算法岗竞争日益激烈,面试难度之大各位有目共睹,面试前背过几个常见面试题已经远远不够了,面试官通常会“刨根问底“,重点考察候选人对模型的掌握深度。因此,对于XGBoost,你不仅需要知其然,而且还要知其所以然。
本文重点介绍XGBoost的推导过程,文末会抛出10道面试题考验一下各位,最后准备了一份“XGB推导攻略图”,帮助你更好的掌握整个推导过程。
本文结构
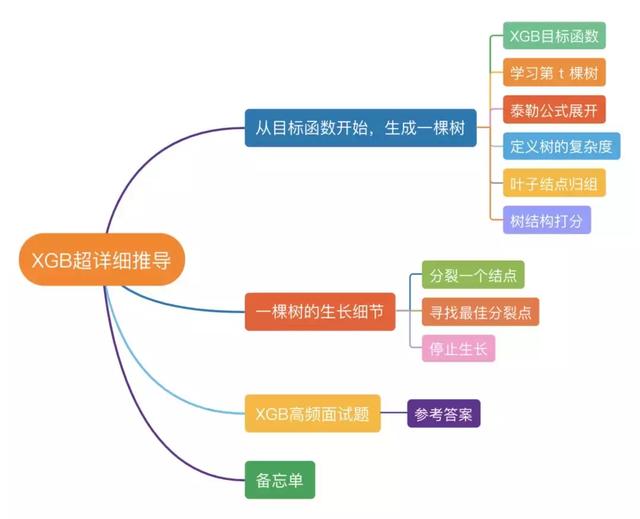
01
从“目标函数”开始,生成一棵树
1. XGB目标函数
XGBoost的目标函数由训练损失和正则化项两部分组成,目标函数定义如下:

变量解释:
(1)l 代表损失函数,常见的损失函数有:
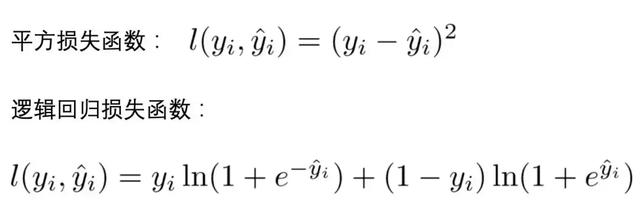
(2)yi'是第 i 个样本 xi 的预测值。由于XGBoost是一个加法模型,因此,预测得分是每棵树打分的累加之和。
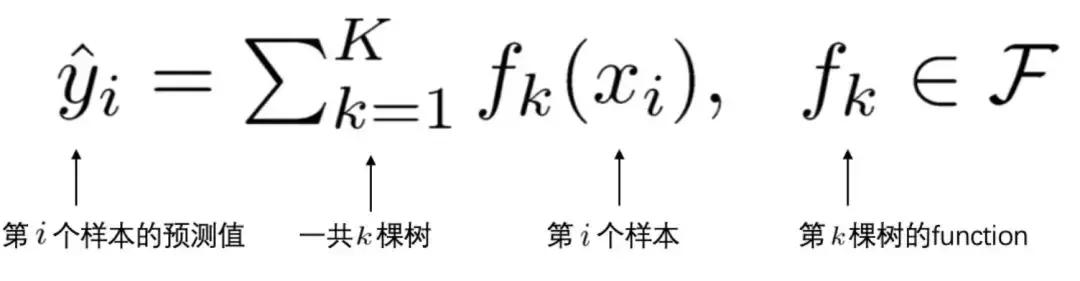
(3)将全部k棵树的复杂度进行求和,添加到目标函数中作为正则化项,用于防止模型过度拟合。
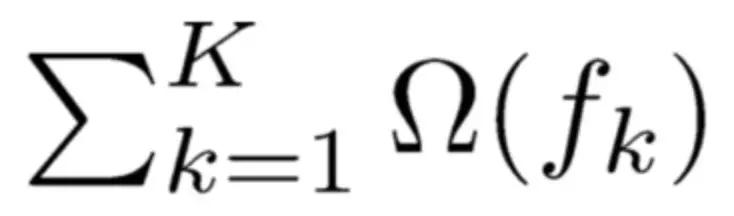
2. 学习第t棵树
在【1】中提到,XGBoost 是一个加法模型,假设我们第t次迭代要训练的树模型是 ft(),则有:

将上式带入【1】中的目标函数 Obj ,可以得到:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









