






2023年4月7日,阿里云首次开启了通义千问的旅程,四个月前,阿里首次发布Qwen-7B大型语言模型(LLM),正式开启了开源之旅。今天,我们介绍Qwen开源家族,更全面的展示我们的工作和目标。下面是开源项目和社区的重要链接。
内测地址回复【阿里】即可体验max和plus版本
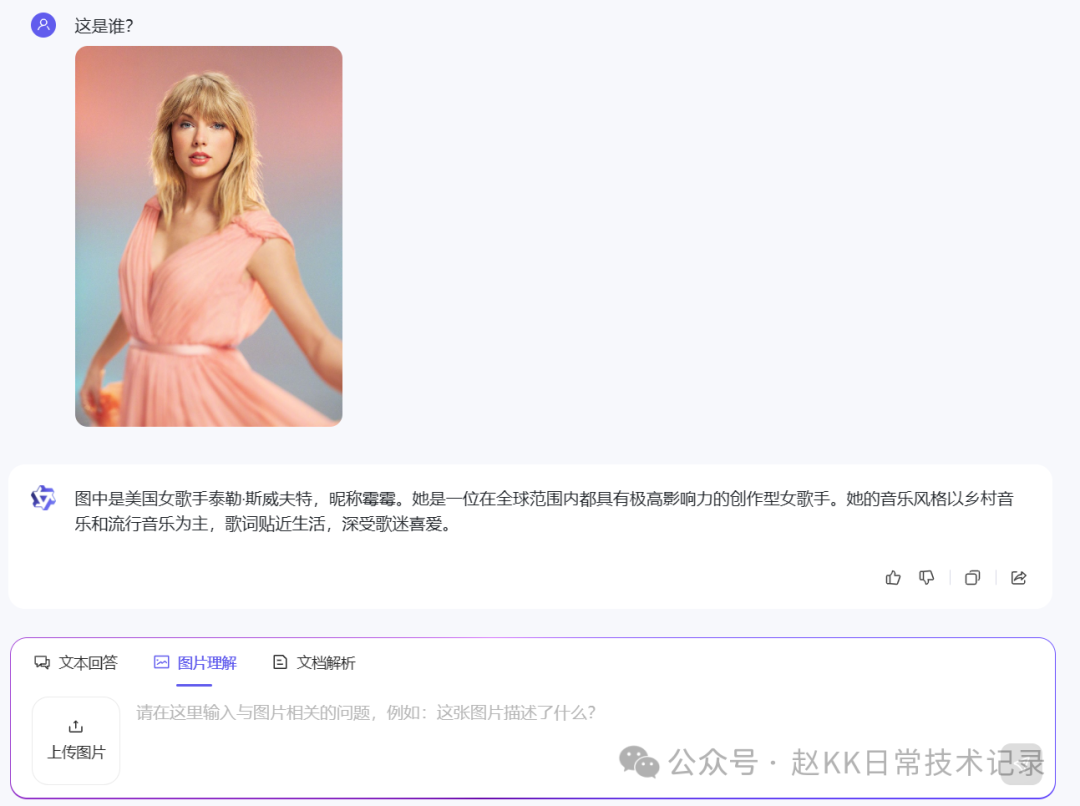
升级版模型能够准确描述和识别图片信息,并且根据图片进行信息推理、扩展创作;
具备视觉定位能力,还可针对画面指定区域进行问答。
Qwen-VL-Plus和Qwen-VL-Max可以理解流程图等复杂形式图片,可以分析复杂图标,看图做题、看图作文、看图写代码。
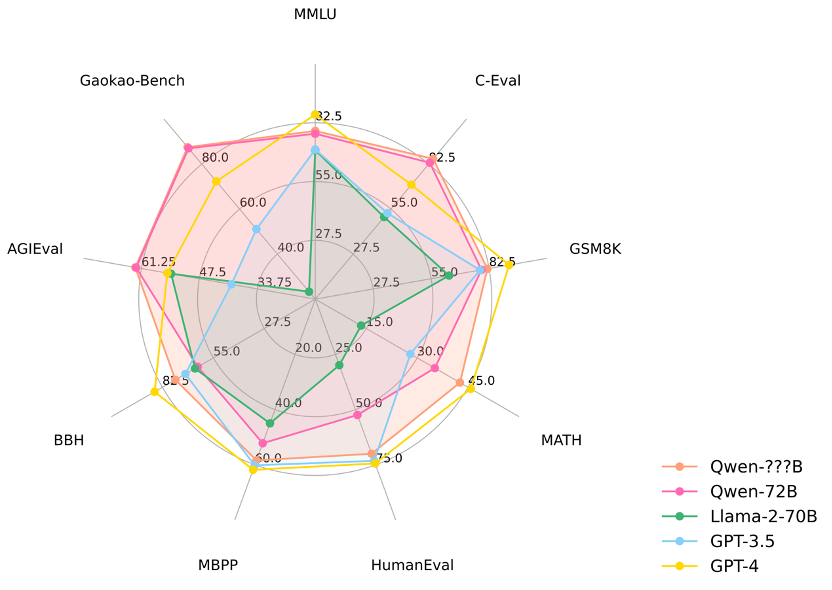
综合能力超越了世面上已经问世的先进大模型,GPT-4和Gemini等

连续发布Qwen和Qwen-VL,Qwen不仅仅是一个语言模型,而是一个致力于实现通用人工智能(AGI)的项目,目前包含了大型语言模型(LLM)和大型多模态模型(LMM)

总结:Qwen项目是一个多模态AI项目,包括Qwen-Chat、Code-Qwen、Math-Qwen、Qwen-VL和Qwen-Audio。该项目使用了Qwen语言模型的预训练、SFT和RLHF方法,并正在探索扩展模型和数据的新路径。

LLM压缩了人类的世界知识,我们将视觉编码器与LLM对齐,使得Qwen-VL能够展现出视觉理解和推理的能力。
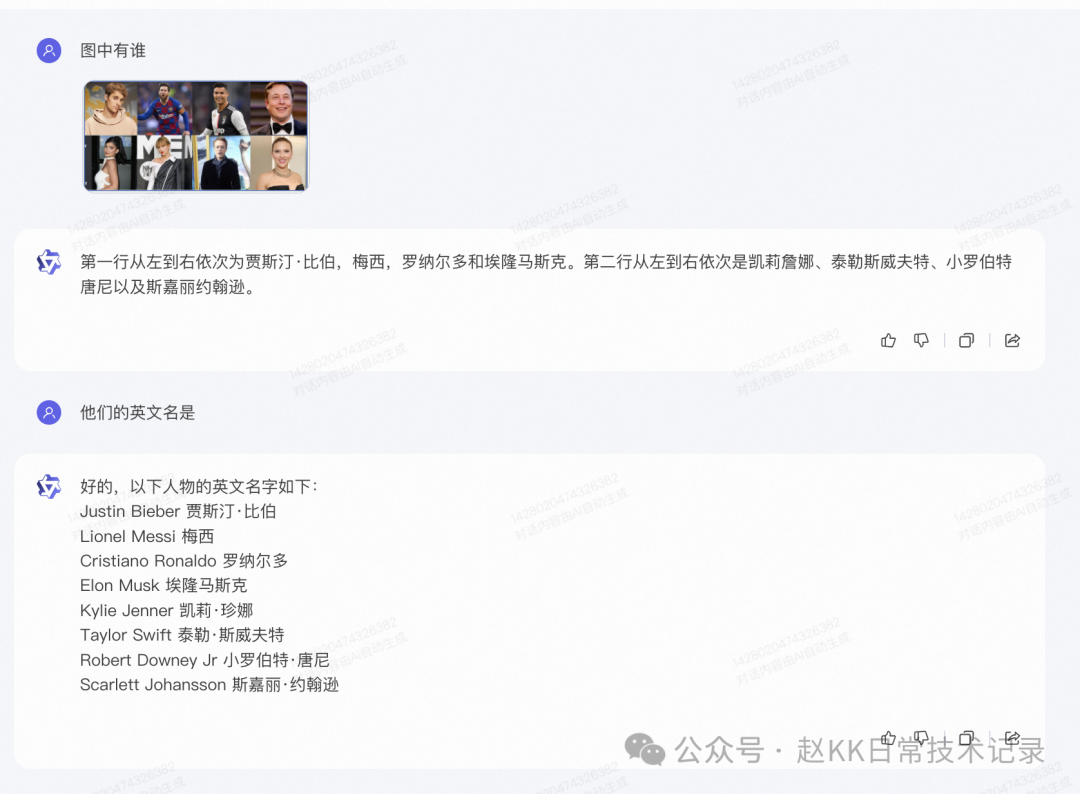
其一是对齐视觉与语言表达空间。将视觉编码器和预训练LLM在大量图像文本数据上的表示对齐,使模型学习关联视觉与语言知识。这为模型提供强大视觉理解能力基础。
Qwen-VL-Plus具备视觉agent能力和定位能力:

其二是整合下游视觉任务能力。在对齐基础上继续训练,让模型掌握视觉问答、图像描述、OCR等任务,真正具备视觉语言推理思维。
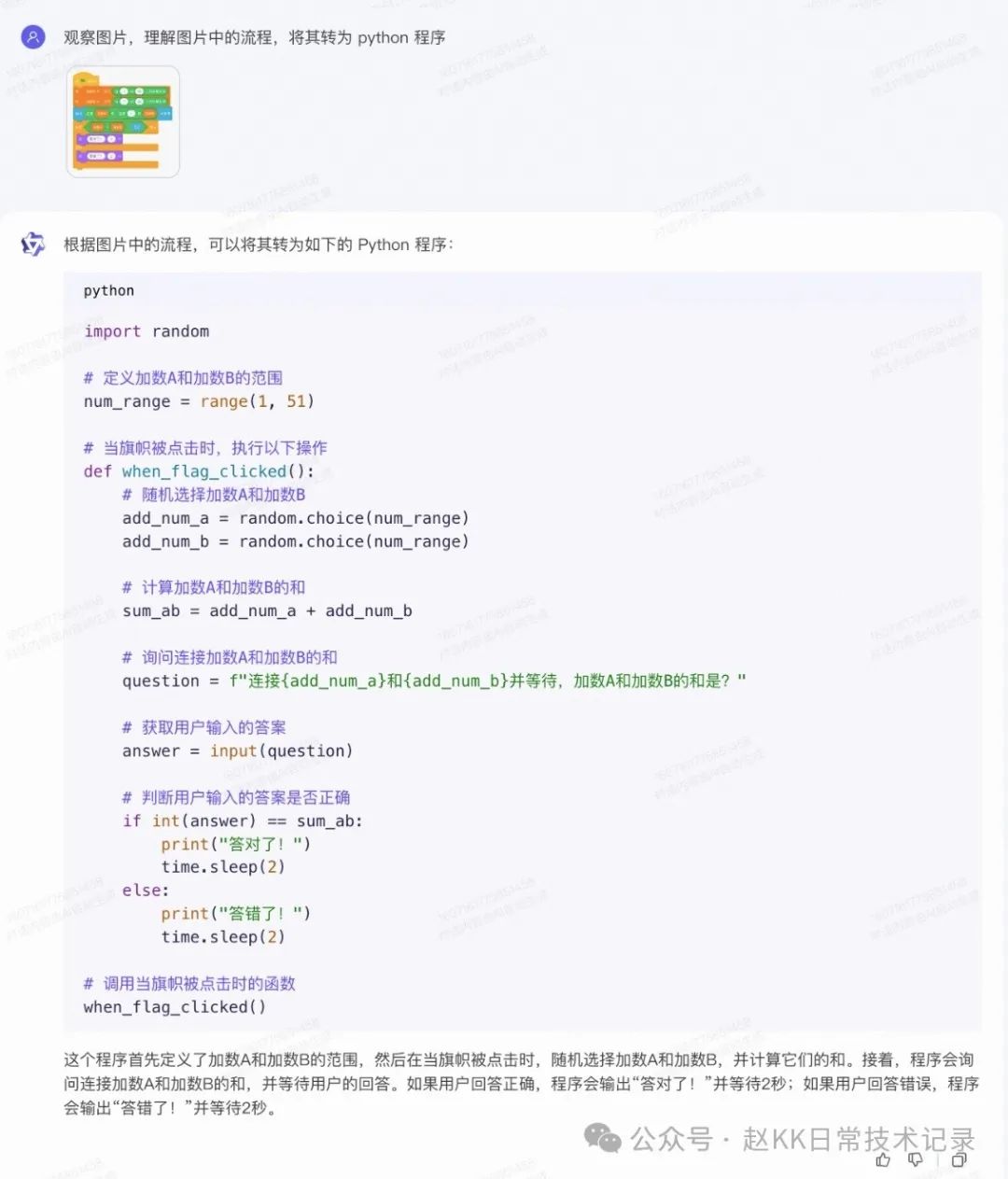
第三是加强视觉表达功能。训练模型提取图像细节,理解复杂图片如流程图,可用于自动驾驶等应用。它也能精准识别各类文字,高效提取图片信息。

最后,研究人员将视觉模型与LLM进行深度融合,实现强大可复用的视觉语言助手。它不仅可以查询及对话,更能分析视觉输入,为用户提供视觉决策支持,这将极大提升LLM在真实场景中的应用潜力。随着技术不断优化,LLM将真正像人类那样具备视觉智能。
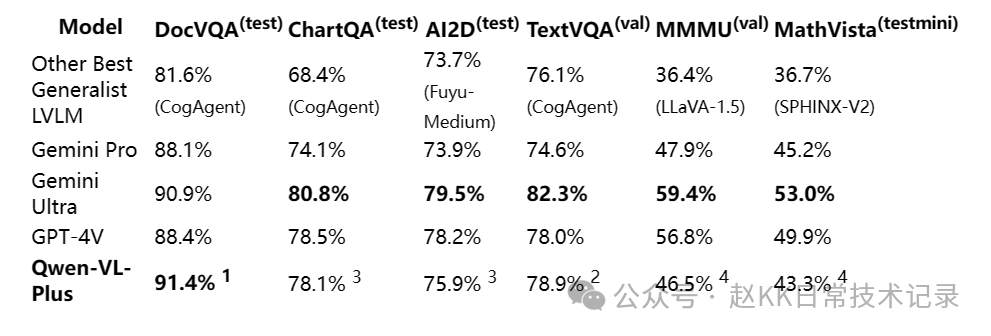
通义千问视觉理解模型Qwen-VL再次升级,推出Max版本,拥有更强的视觉推理和中文理解能力,在多个权威测评中获得佳绩,整体性能堪比GPT-4V和Gemini Ultra。

看图说话
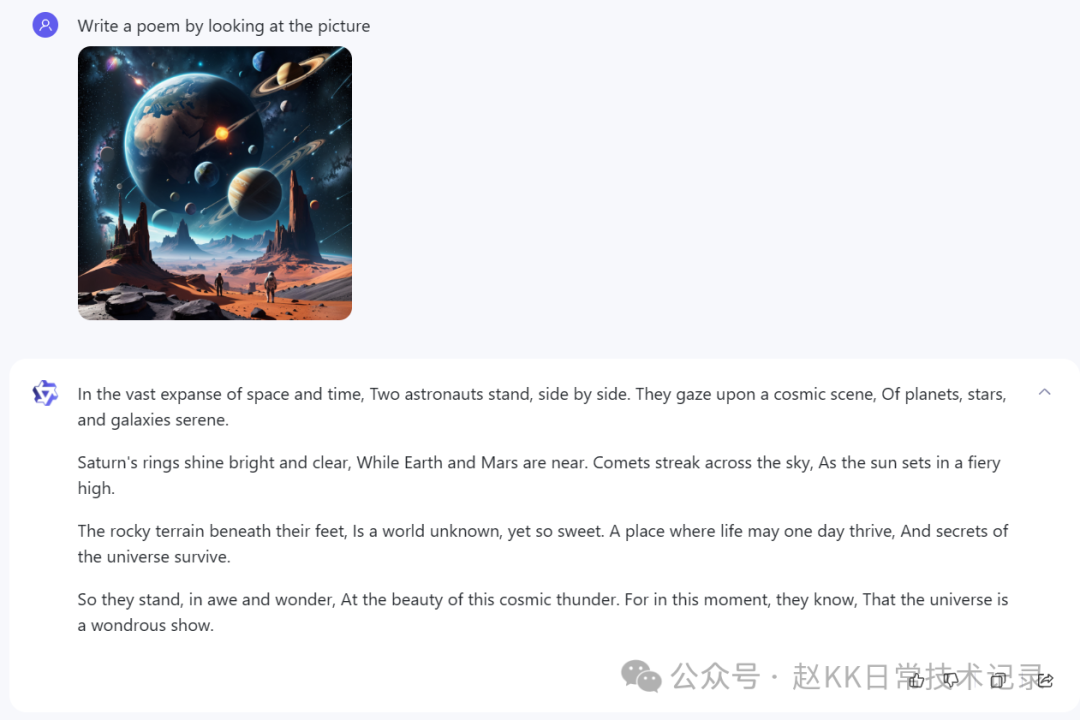
看图写诗
参考文档
Paper: https://arxiv.org/abs/2309.16609GitHub: https://github.com/QwenLMHugging Face: https://huggingface.co/QwenModelScope: https://modelscope.cn/organization/qwenDiscord: https://discord.gg/z3GAxXZ9C
领取comfyui工作流合集
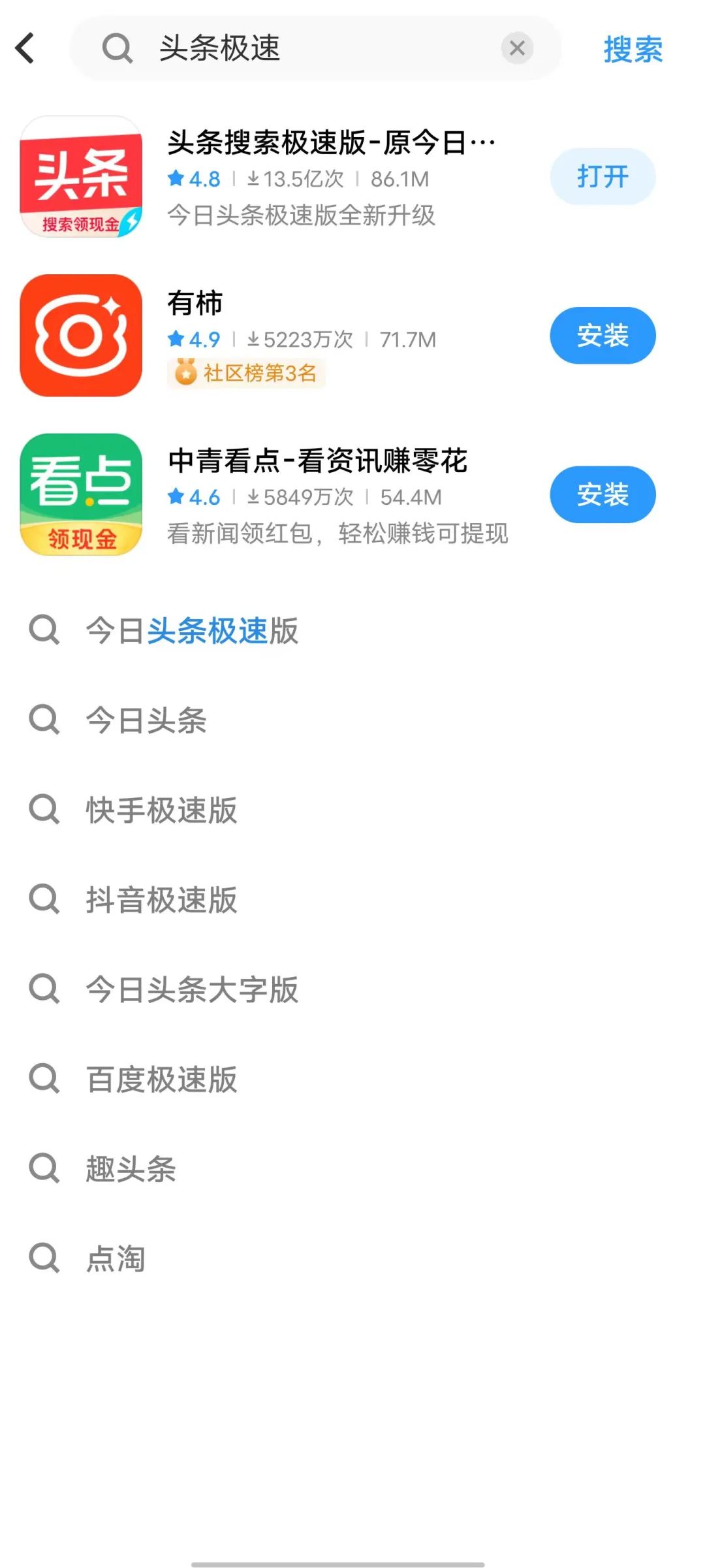
应用商店搜索头条极速版

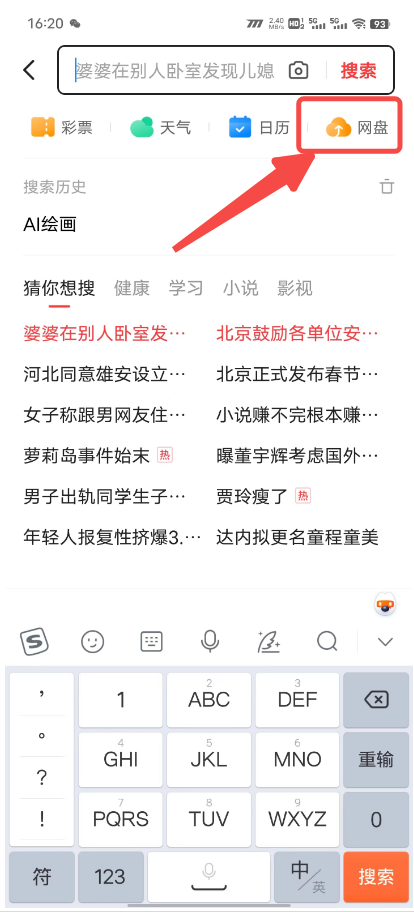
点击搜索框

点击网盘
搜索AI绘画KK
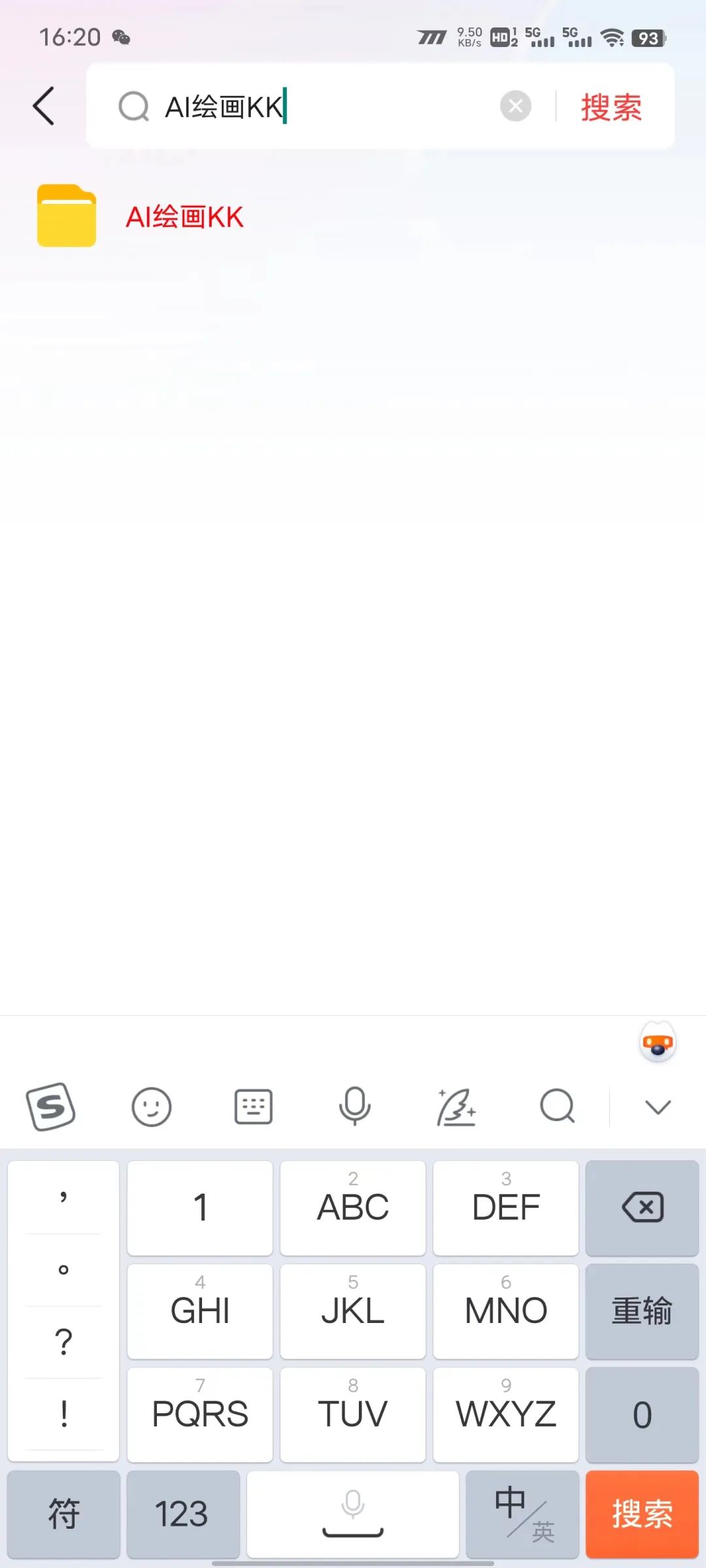

超多AI合集已整理到https://yv4kfv1n3j.feishu.cn/docx/MRyxdaqz8ow5RjxyL1ucrvOYnnH
文档更新
4万字comfyui教程、AI模特、AI换脸、AI抠图、AI制作PPT、AI音频、AI视频、AI物体消除
后台回复【起飞】获取加速插件下载地址















 1877
1877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









