






以下来自官网文档说明
https://pan.quark.cn/s/8e66ada8a434
SD启动器2024最新版本下载
链接:https://pan.quark.cn/s/eea6375642fd
我用夸克网盘分享了「小说推文底模一键合集」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:https://pan.quark.cn/s/108e0996f35e
支持使用SDXL模型和一定的选项直接生成高清大图,不再需要上传模板,需要16GB显存
SDXL–TXT2video
第二版本
1.安装与使用教程2
学习前言
在视觉方向的AIGC领域,AI写真是一个靠谱且经过验证的落地方案,随着StableDiffusion领域开源社区的快速发展,社区也涌现了类似 FaceChain 这样基于 Modelscope开源社区结合 diffusers 的开源项目,用于指导用户快速开发个人写真。
然而对于大量使用SDWebUI的 AIGC 同学们,短时间内却没有一个效果足够好的开源插件,去适配真人写真这一功能。
对于AI写真而言,需要注意两个方向的重点,一个是一定要和用户像,另外一个是一定要真实。
最近我参与了一个EasyPhoto的项目,可以根据模板图像生成对应的用户写真,借助Stable Diffusion与Lora的强大生成能力,生成图片可以做到较为相似且真实,近期也开源了出来。
源码下载地址
https://github.com/aigc-apps/sd-webui-EasyPhoto
麻烦各位朋友点个Star,这对我来讲还是很重要的!
技术原理储备(SD/Control/Lora)
StableDiffusion
StableDiffusion作为Stability-AI开源图像生成模型,通常分为SD1.5/SD2.1/SDXL等版本, 是通过对海量的图像文本对进行训练结合文本引导的扩散模型,使用训练后的模型,通过对输入的文字进行特征提取,引导扩散模型在多次的迭代中生成高质量且符合输入语义的图像。下面的图像就是Stable Diffusion官网贴出来的他们的效果。
EasyPhoto AI基于StableDiffusion丰富的开源社区与强大的生成能力,进而生成逼真且自然的AI写真。

ControlNet
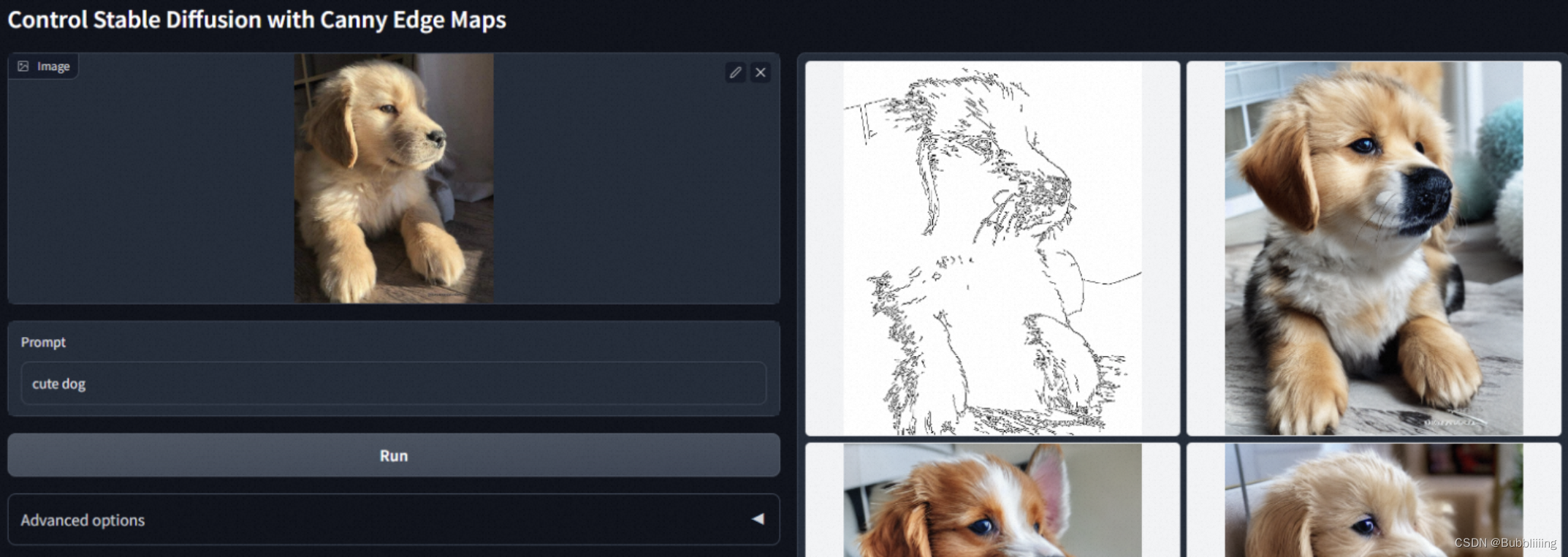
ControlNet是《Adding Conditional Control to Text-to-Image Diffusion Models》提出的通过添加部分训练过的参数,对StableDiffsion模型进行扩展,用于处理一些额外的输入信号,例如骨架图/边缘图/深度图/人体姿态图等等输入,从而完成利用这些额外输入的信号,引导扩散模型生成与信号相关的图像内容。例如我们在官方 Repo 可以看到的,使用Canny边缘作为信号,控制输出的小狗。
EasyPhoto 基于多Controlnet强大的控制能力,在保留原模板特点的情况下(如颜色、光照、轮廓),生成非常自然写真图像。
Lora
由《LoRA: Low-Rank Adaptation of Large Language Models》 提出的一种基于低秩矩阵的对大参数模型进行少量参数微调训练的方法,广泛引用在各种大模型的下游使用中。AI真人写真需要保证最后生成的图像和我们想要生成的人是相像的,这就需要我们使用Lora 技术,对输入的少量图片,进行一个简单的训练,从而使得我们可以得到一个小的指定人脸(Face id)的模型。
EasyPhoto插件简介
EasyPhoto是一款Webui UI插件,用于生成AI肖像画,该代码可用于训练与用户相关的数字分身。建议使用 5 到 20 张肖像图片进行训练,最好是半身照片且不要佩戴眼镜(少量可以接受)。训练完成后,EasyPhoto可以在推理部分生成图像。EasyPhoto支持使用预设模板图片与上传自己的图片进行推理。
这些是插件的生成结果,从生成结果来看,插件的生成效果还是非常不错的:

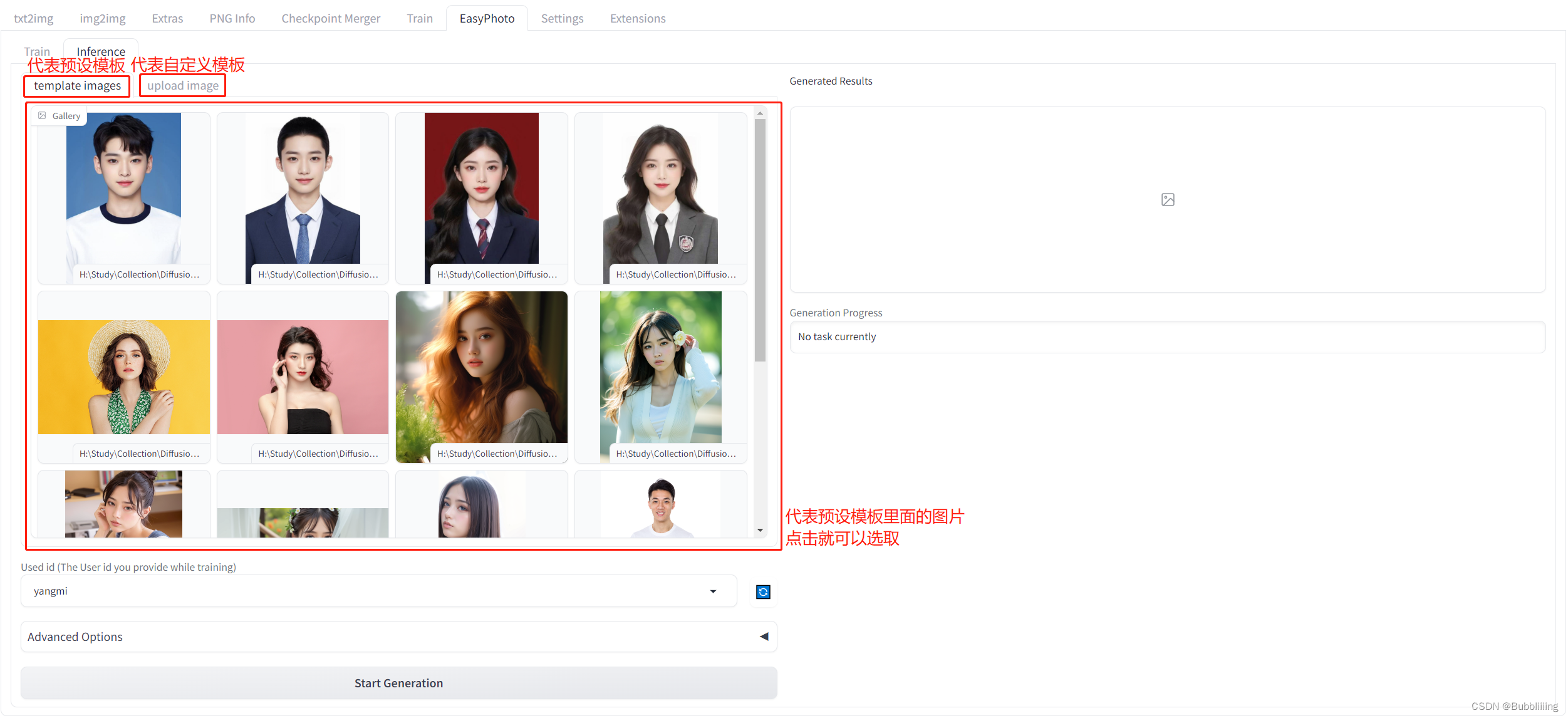
每个图片背后都有一个模板,EasyPhoto会对模板进行修改使其符合用户的特征。 在EasyPhoto插件中,Inference侧已经预置了一些模板,可以用插件预置的模板进行体验;另外,EasyPhoto同样可以自定义模板,在Inference侧有另外一个tab页面,可以用于上传自定义的模板。如下图所示。
而在Inference预测前,我们需要进行训练,训练需要上传一定数量的用户个人照片,训练的产出是一个Lora模型。该Lora模型会用于Inference预测。
总结而言,EasyPhoto的执行流程非常简单: 1、上传用户图片,训练一个与用户相关的Lora模型; 2、选择模板进行预测,获得预测结果。
EasyPhoto插件安装
安装方式一:Webui界面安装 (需要良好的网络)
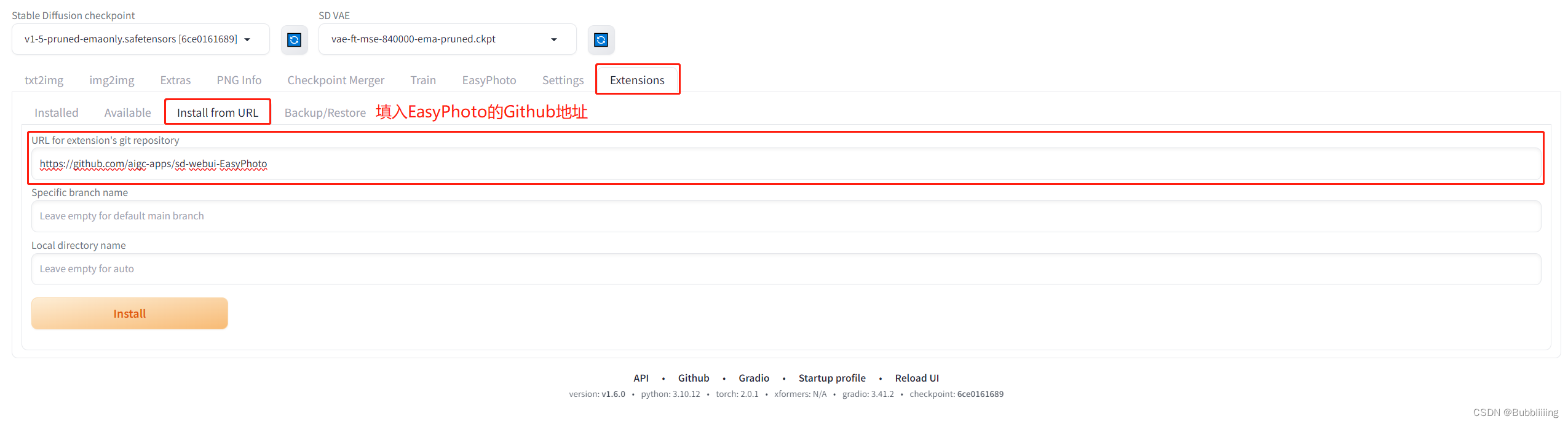
安装过程较为简单,网络良好的情况下,跳转到Extentions,然后选择install from URL。 输入https://github.com/aigc-apps/sd-webui-EasyPhoto,点击下方的install即可安装,在安装过程中,会自动安装依赖包,这个需要耐心等待一下。安装完需要重启WebUI。
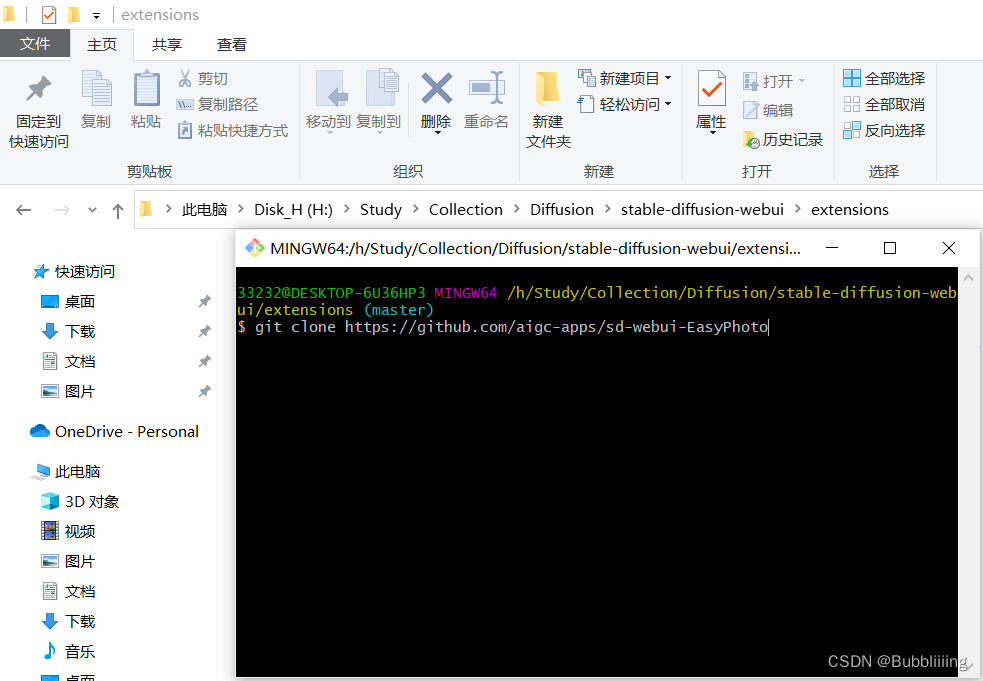
安装方式二:Git clone下载安装 (clone过程会提示安装进度)
直接进入到Webui的extensions文件夹,打开git工具,git clone即可。 下载完成后,重新启动webui,便会检查需要的环境库并且安装。
其它插件安装:Controlnet 安装
我们需要使用 Controlnet 进行推理。相关软件源是Mikubill/sd-webui-controlnet。在使用 EasyPhoto 之前,您需要安装这个软件源。
此外,我们至少需要三个 Controlnets 用于推理。因此,您需要设置 Multi ControlNet: Max models amount (requires restart)。
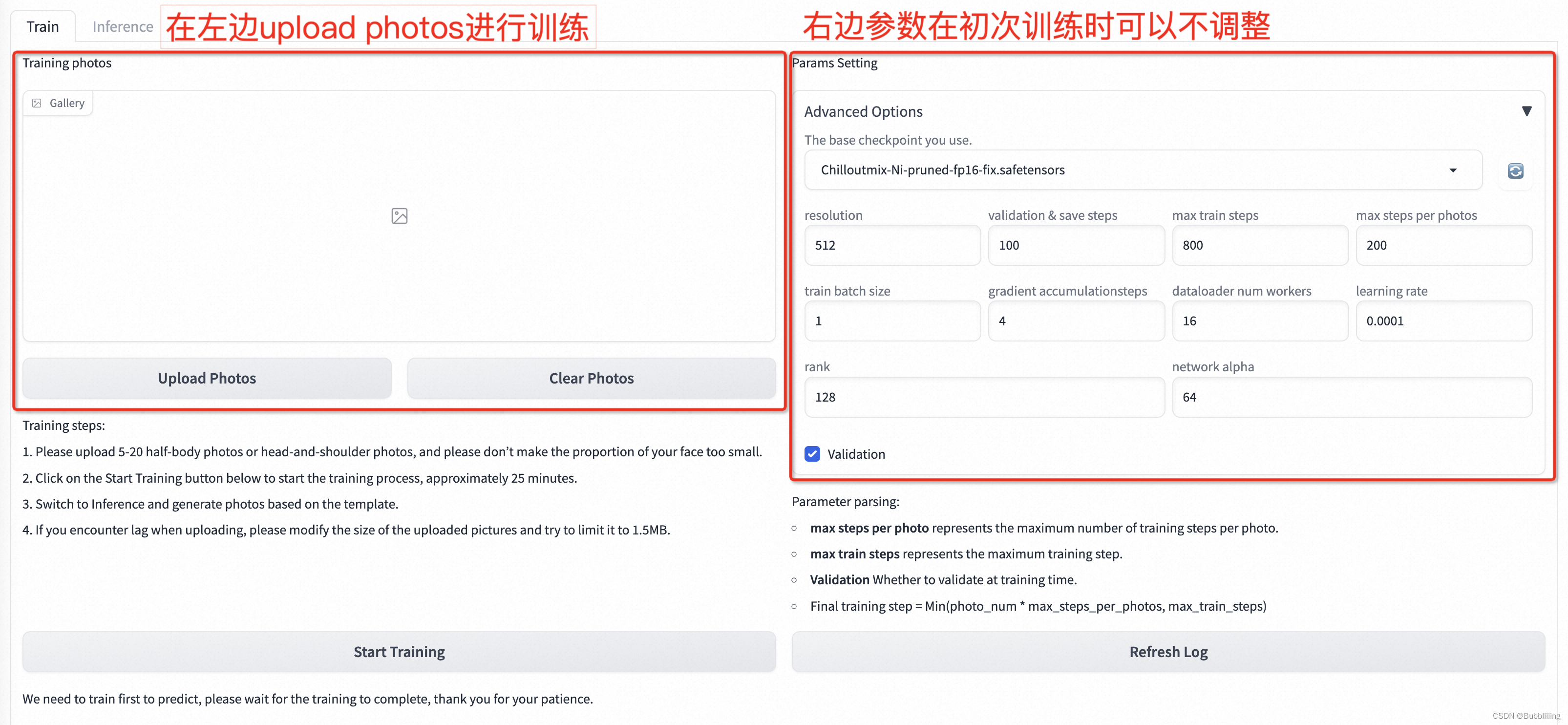
EasyPhoto训练
EasyPhoto训练界面如下:
- 左边是训练图片,直接点击Upload Photos即可上传图片,点击Clear Photos可以删除已经上传的图片;
- 右边是训练参数,初次训练可不做参数调整。
1、上传图片(Upload photos)
点击Upload Photos后即可开始上传图片,在此处我们最好上传5-15张图片、包含不同角度、不同光照的情况;而我这里用了7张,最好有一些图片是不包括眼镜的,如果都是眼镜,生成结果里面有容易会生成眼镜。
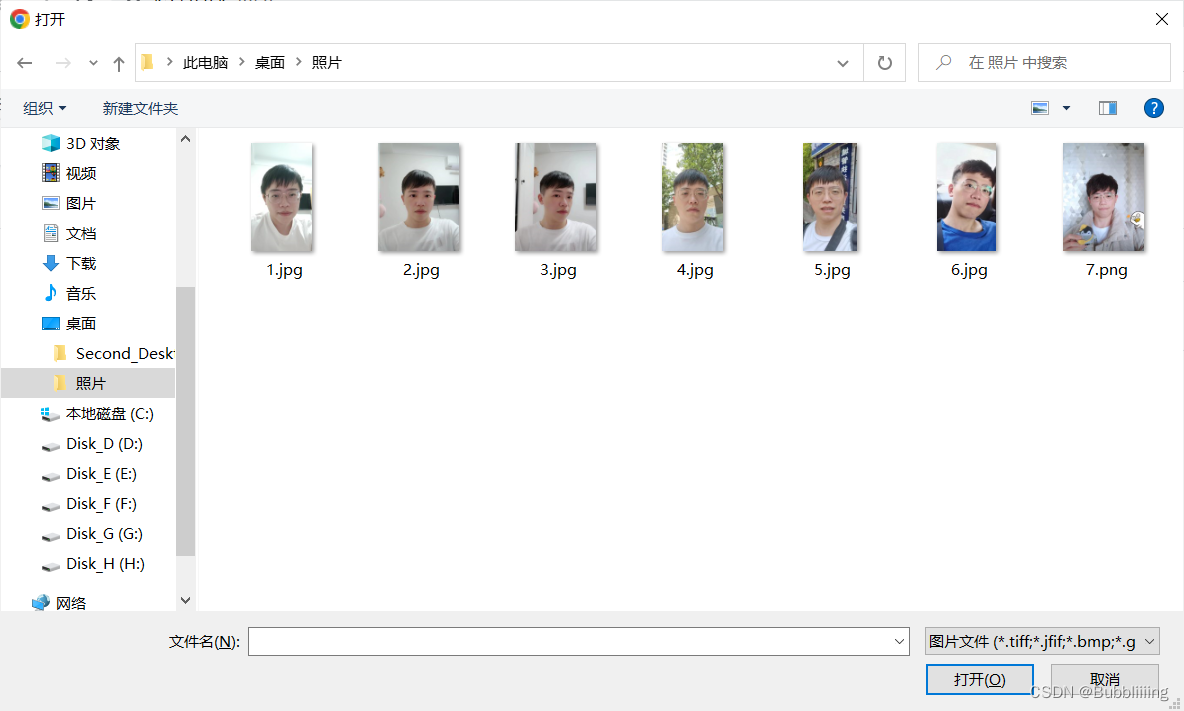
上传完成后,我们就可以在界面上看到已经上传的图像啦!
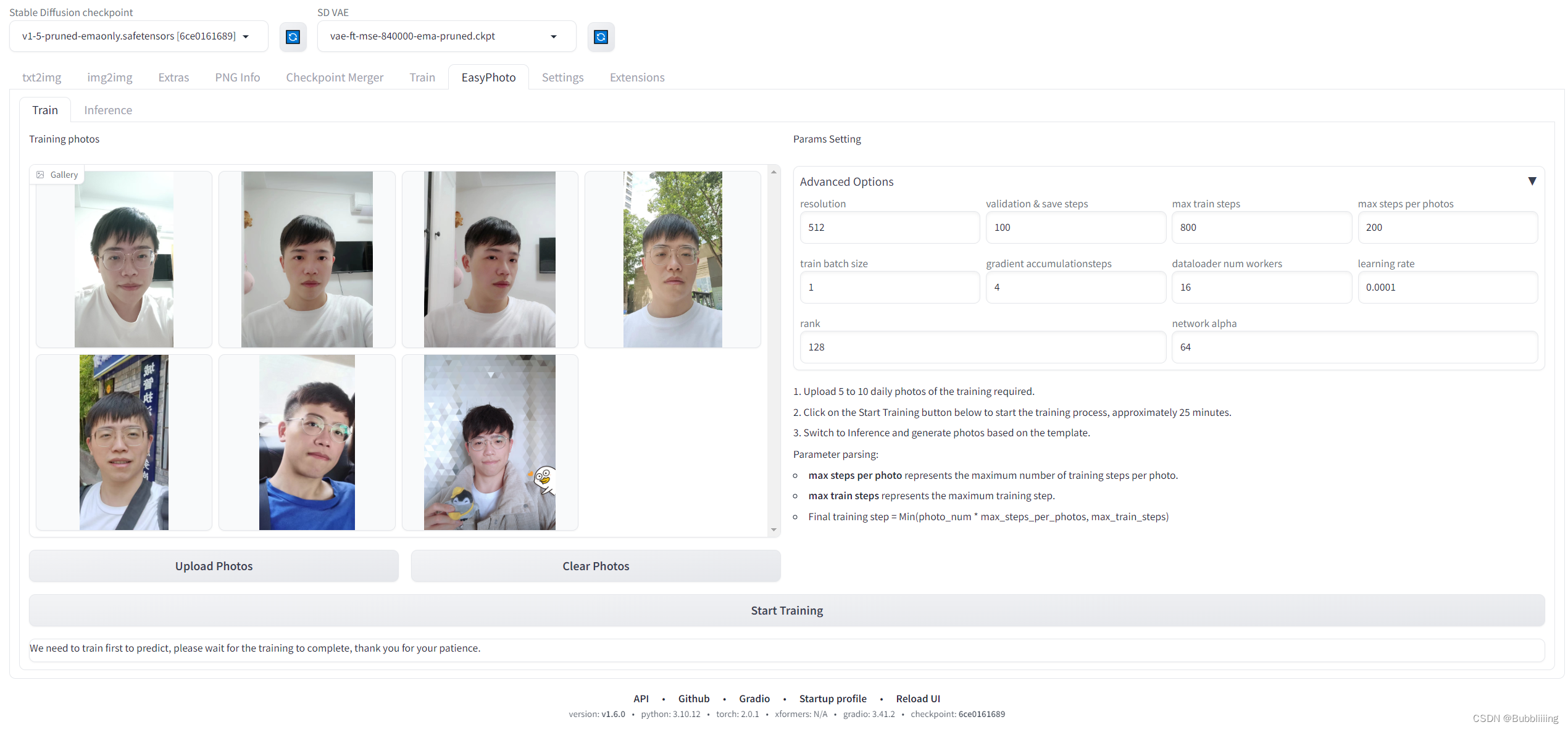
2、参数设置(Adanced Options)
a、默认参数解析
然后我们来看右边的参数设置部分,这里参数可调节的量还是比较多的,初次训练不做调整,每个参数的解析如下:
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 参数名 | 含义 |
|---|---|
| resolution | 训练时喂入网络的图片大小,默认值为512 |
| validation & save steps | 验证图片与保存中间权重的steps数,默认值为100,代表每100步验证一次图片并保存权重 |
| max train steps | 最大训练步数,默认值为800 |
| max steps per photos | 每张图片的最大训练次数,默认为200 |
| train batch size | 训练的批次大小,默认值为1 |
| gradient accumulationsteps | 是否进行梯度累计,默认值为4,结合train batch size来看,每个Step相当于喂入四张图片 |
| dataloader num workers | 数据加载的works数量,windows下不生效,因为设置了会报错,Linux正常设置 |
| learning rate | 训练Lora的学习率,默认为1e-4 |
| rank Lora | 权重的特征长度,默认为128 |
| network alpha | Lora训练的正则化参数,一般为rank的二分之一,默认为64 |
最终训练步数的计算公式也比较简单,Final training step = Min(photo_num * max_steps_per_photos, max_train_steps)。
简单来理解就是: 图片数量少的时候,训练步数为photo_num * max_steps_per_photos。 图片数量多的时候,训练步数为max_train_steps。
b、开启或者关闭验证
EasyPhoto在训练时默认会对训练过程进行验证,然后根据 训练过程中的验证结果,进行最优秀的几个Lora进行融合。
但这个 验证 在显存不足时容易导致 卡住,并且因为验证的频次较多,会影响一定的训练速度,如果机器的配置不足,可以尝试关闭验证来加快训练速度。

3、开始训练(Start Training)
a、填入User ID
然后我们点击下方的开始训练,此时需要在上方填入一下User ID,比如 用户的名字,然后就可以开始训练了。

b、下载权重
开始初次训练时会从oss上下载一部分权重,我们耐心等待即可,大概需要下载10G左右的资源,下载进度需要关注终端。
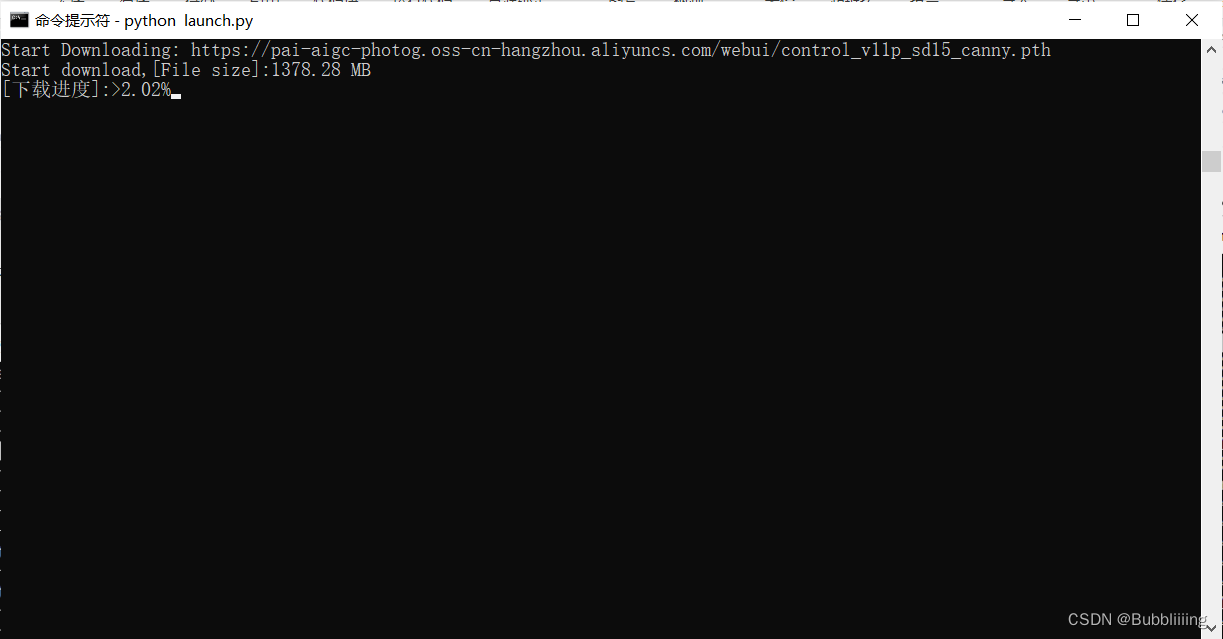
c、开始训练
在自动预处理完成后,Lora模型开始训练,我们只需要耐心的等待训练完成即可!
d、得分检查
终端显示成这样就已经训练完了,最后这步是在计算验证图像与用户图像之间的人脸 ID 相似性,从而实现 Lora 融合,确保我们的 Lora 是用户的完美数字分身。
一般来讲这个得分相似性在0.50以上是正常的情况,如果得分在0.10以下则需要检查一下环境,可能因为环境不对导致模型并未训练。
EasyPhoto预测
1、User ID选择
训练完后,我们需要将tab页转到Inference。由于Gradio的特性,刚训练好的模型不会自动刷新,可以点击Used id旁的蓝色旋转按钮进行模型刷新。
刷新完后选择刚刚训练的模型,然后选择对应的模板即可开始预测。
2、模板选择
a、预设模板(template image)
EasyPhoto仓库中预设了一些模板,template image中直接点击,即可选择模版进行预测。
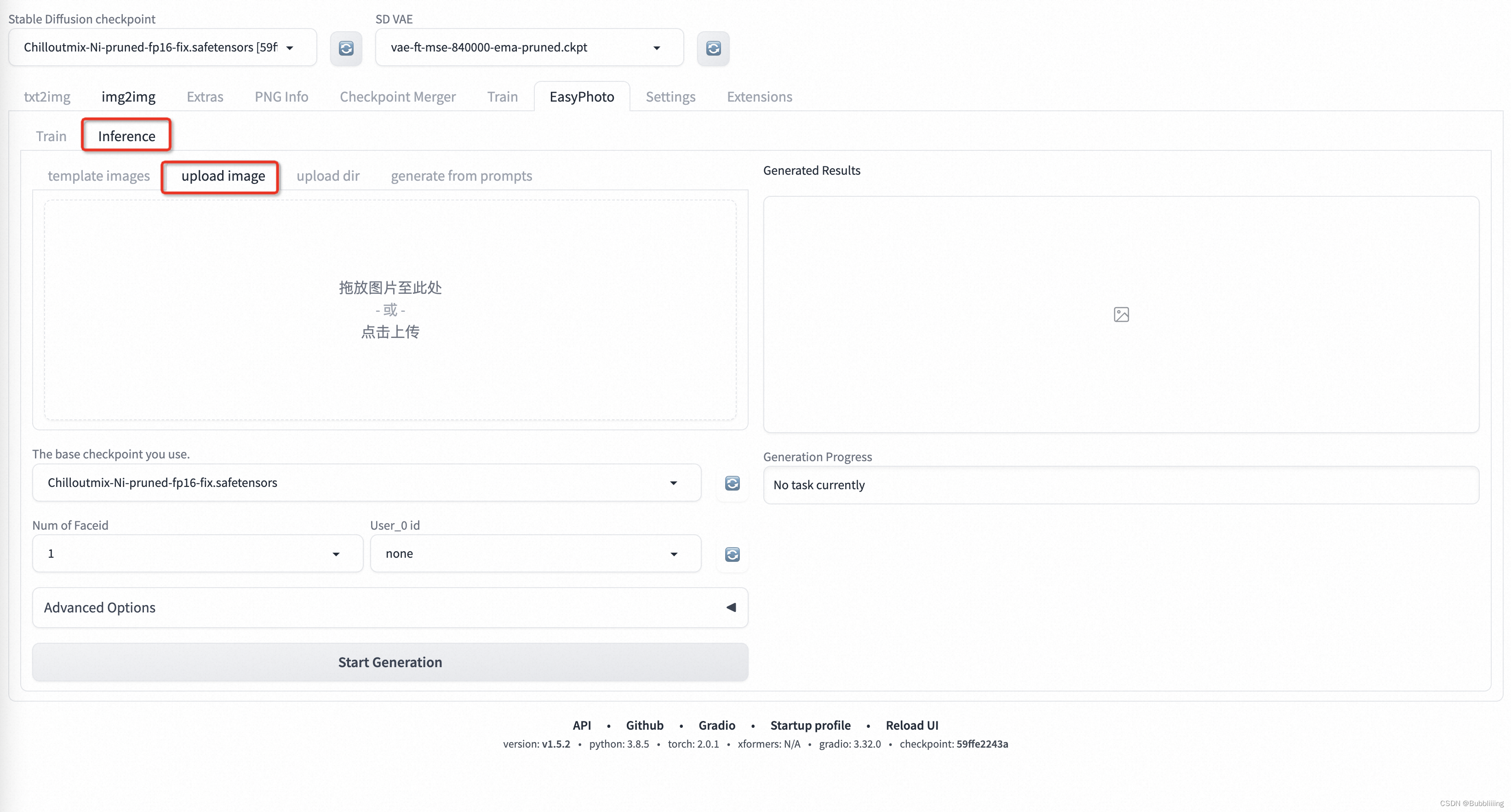
b、上传模板(upload image)
预设模板的内容比较有限,可以切到upload image,直接自己上传模板进行预测。
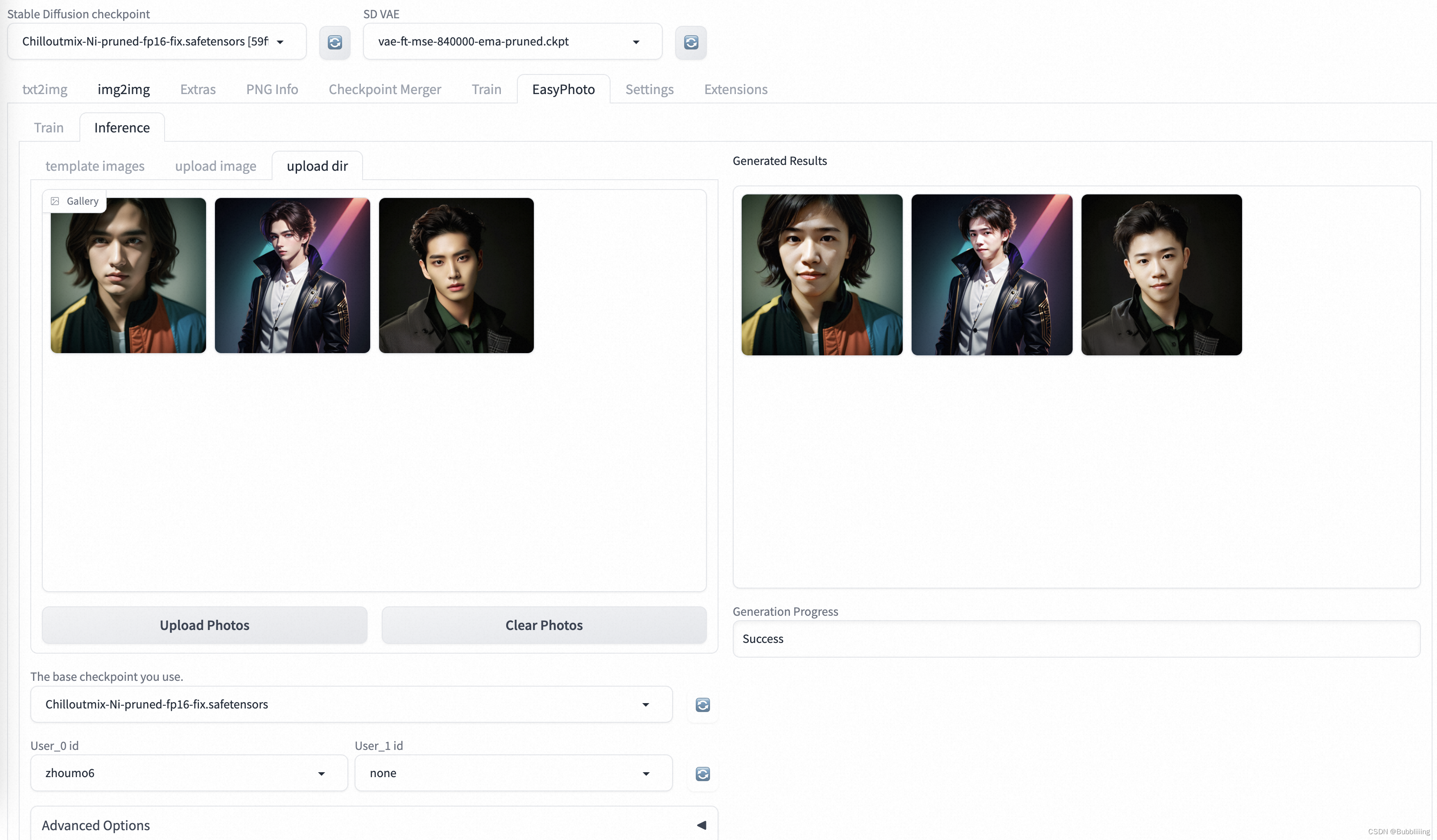
c、上传多图批量预测(upload dir)
点击upload dir可以上传多图进行批量预测,上传完成后,点击Start Generation即可批量生成。
批量生成时间较久,请耐心等待。
3、高级选项(Advanced Options,参数设置)
高级选项中包含预测中各个能够设置的参数,大概有下面这么几个,请各位同学按情况进行调整
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 参数名 | 参数解释 | 调整后的影响 |
|---|---|---|
| Additional Prompt | 正向提示词,会传入Stable Diffusion模型进行预测。 | 可以根据自身希望增加的元素调整prompt词。 |
| Seed | 种子值。 | 用于保证结果的可复现性,为-1时会随机选择一个种子数。 |
| Face Fusion Ratio Before | 第一次人脸融合的强度。 | 调节后会影响人物相似度,一般来讲,值越大与训练人物的相似度越高。 |
| Face Fusion Ratio After | 第二次人脸融合的强度。 | 调节后会影响人物相似度,一般来讲,值越大与训练人物的相似度越高。 |
| First Diffusion steps | 第一次进行Stable Diffusion的总步数。第一次Diffusion主要进行人像区域的调整,使得人像更自然。 | 调节后会影响图片质量与出图速度,一般值越大图片质量越高,出图越慢。 |
| First Diffusion denoising strength | 第一次进行Stable Diffusion的重绘比例。 | 调节后会影响图片的重绘比例与出图速度,一般值越大,人像变动越大。 |
| Second Diffusion steps | 第二次进行Stable Diffusion的总步数。 第二次Diffusion主要进行人像周围区域的调整,使得图片更和谐。 | 调节后会影响图片质量与出图速度,一般值越大图片质量越高,出图越慢。 |
| Second Diffusion denoising strength | 第二次进行Stable Diffusion的重绘比例。 | 调节后会影响图片的重绘比例与出图速度,一般值越大,人像周围变动越大。 |
| Crop Face Preprocess | 是否对人像裁剪后再处理。 | 推荐开启,假设输入的是大图,会对人像区域先做裁剪后再进行人像调整,调整结果更精细。 |
| Apply Face Fusion Before | 是否进行第一次人脸融合。 | 调节后会影响是否进行第一次人脸融合,会影响人像的相似度。 |
| Apply Face Fusion After | 是否进行第二次人脸融合。 | 调节后会影响是否进行第二次人脸融合,会影响人像的相似度。 如果感觉人像发虚则取消该次融合。 |
| Apply color shift first | 是否进行第一次DIffusion后的色彩校正。 | 调节后会影响图片的人像自然程度。 |
| Apply color shift last | 是否进行第二次DIffusion后的色彩校正。 | 调节后会影响图片的人像自然程度。 |
| Background Restore | 是否进行背景的重建。 | 开启后可以对人像区域外背景进行重建,在使用动漫化模型时,可以让整个图片更和谐。 |
4、单人预测
选择完user id与模版后,点击start generation即可开始预测。初次预测需要下载一些modelscope的模型,耐心等待一下即可。
等待一段时间后,我们就可以获得预测结果了。
5、多人预测
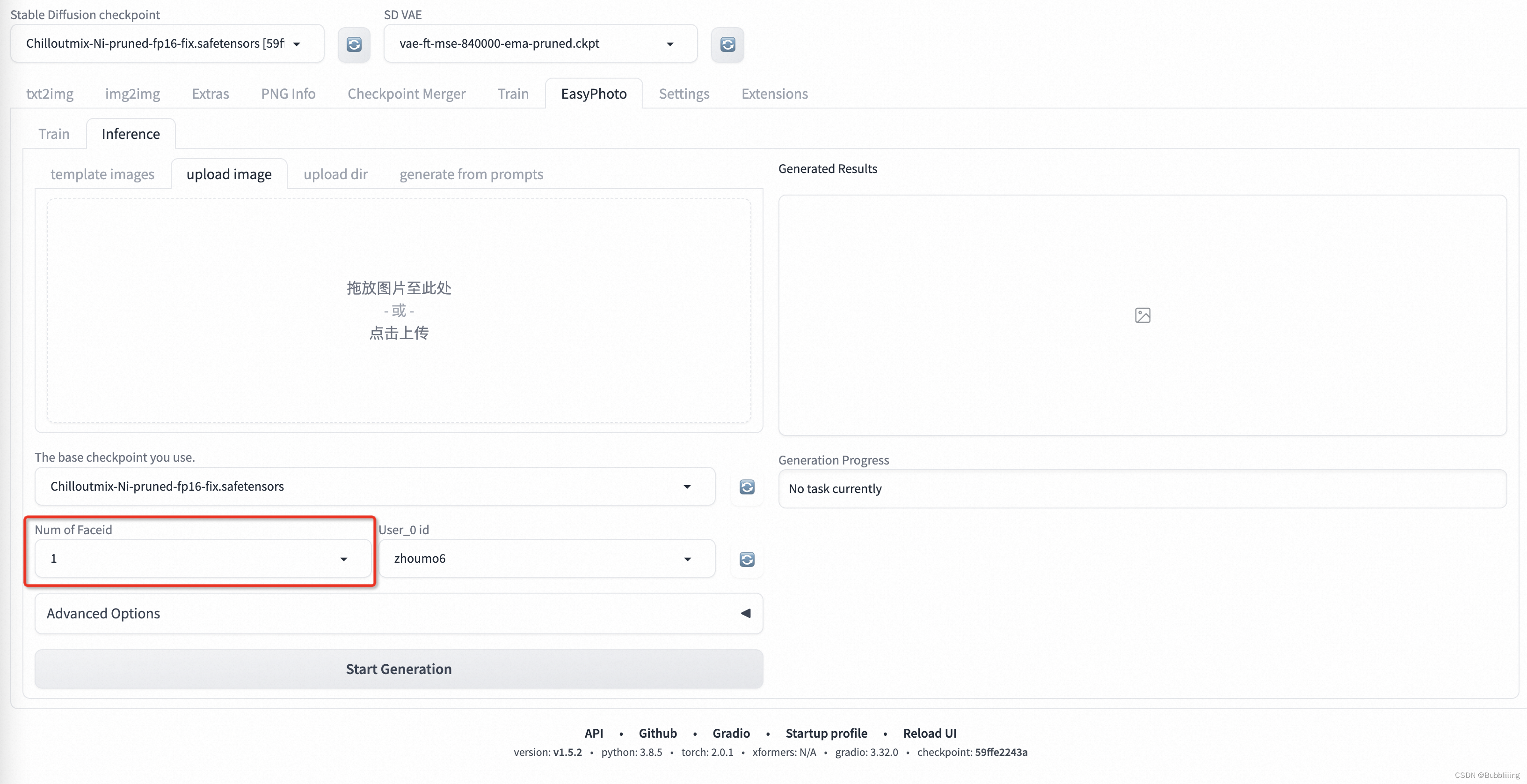
a、Num of Faceid设置
多人预测需要首先设置Num of Faceid,将其设置为需要设置的人数,如画面上有两个人则设置为2:
b、选择User ID
首先是替换多个人像的情况,User ID与图片上人像从左到右对应,如下图所示:
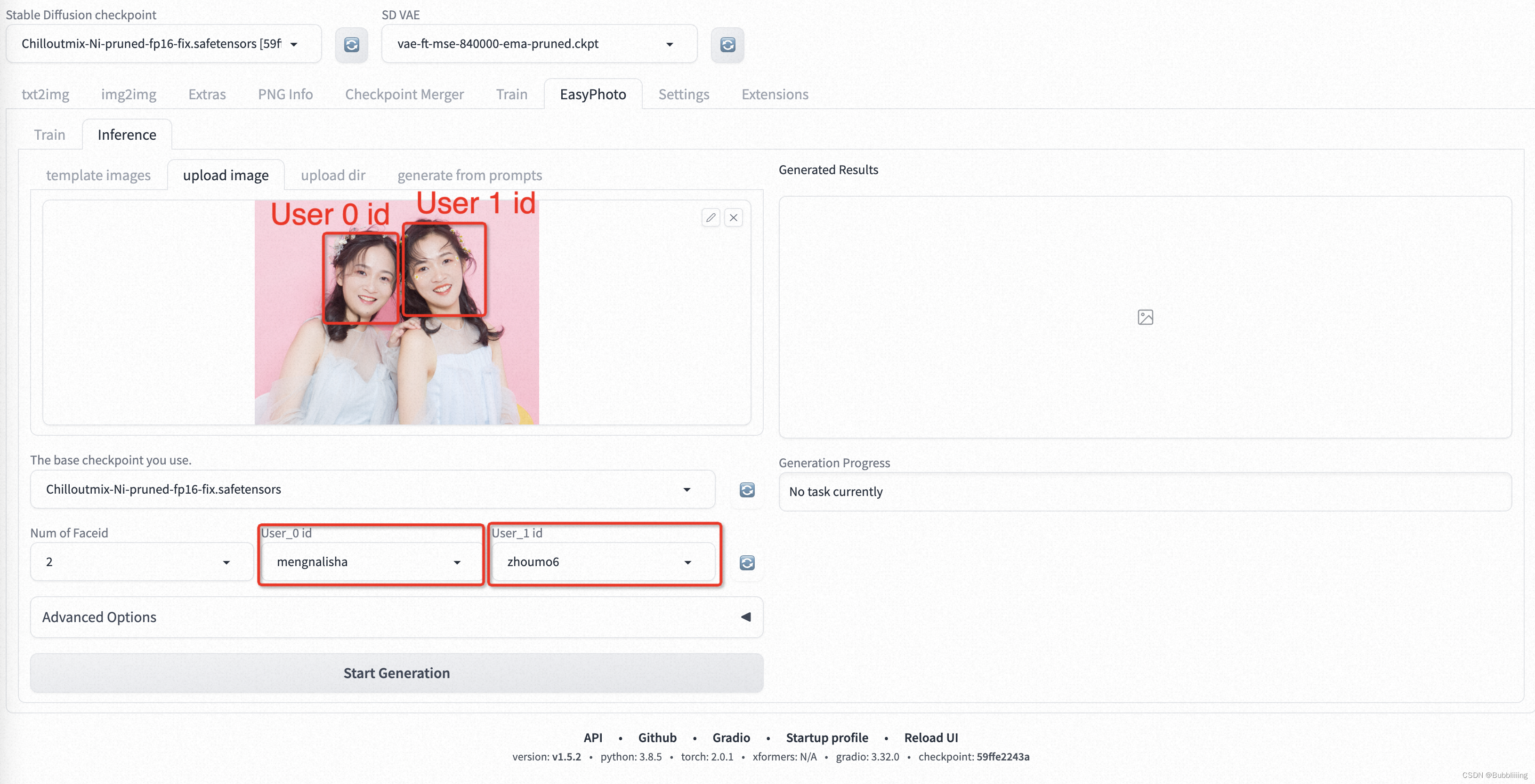
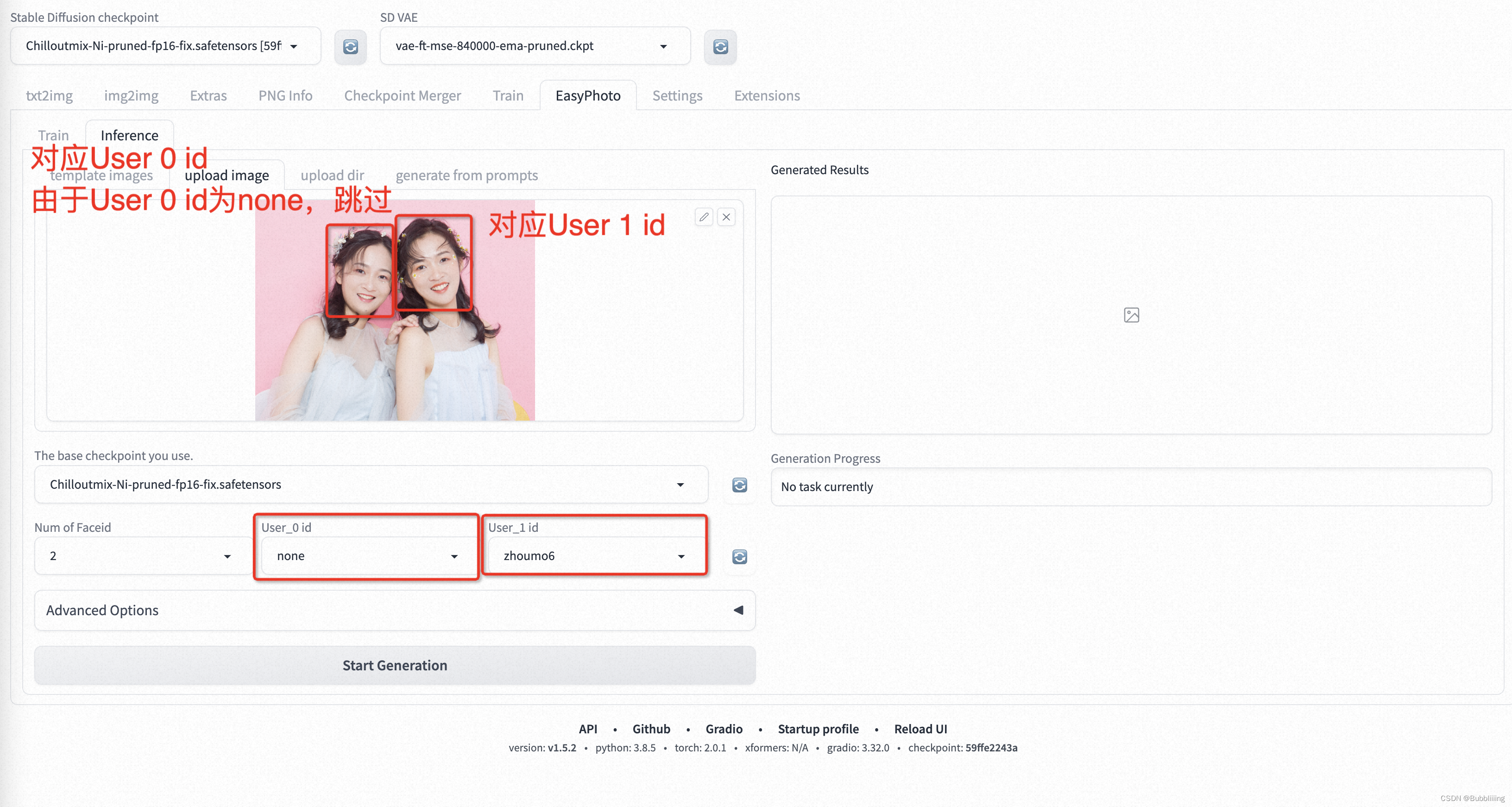
然后是替换多个人像中单个人像的情况,User ID同样与图片上人像从左到右对应,但需要跳过的人像则使用none即可:
训练加速与预测加速
常见问题汇总
常见问题汇总参考: https://github.com/aigc-apps/sd-webui-EasyPhoto/wiki/FAQ
数据加载dataloader(Linux下默认开启)
由于easyphoto训练场景是总样本数少,epoch多的场景,可以将torch.utils.data.DataLoader中persistent_workers=True。
该参数是保证每个epoch结束后数据加载迭代器不释放,不用每个epoch都初始化,从而节约时间。
batch_size等参数调优(修改ui界面的参数开启)
参数调优和GPU型号相关,为了充分利用GPU,可以修改训练启动脚本将batch_size调大.
当前代码中使用的train_batch_size=1, gradient_accumulation_steps=4,单卡的话,每4个训练样本更新一次梯度。
1、显存16G左右(V100)
train_batch_size=2, gradient_accumulation_steps=2;
train_batch_size=4, gradient_accumulation_steps=1;
2、显存23G左右(A10)
上述修改保证训练总样本数和val次数保持不变,当然这种情况下,梯度更新的次数降低了,由于相比之前batch_size仅扩大了1倍,因此lr暂时保持不变。 train_batch_size=8, gradient_accumulation_steps=1; max_train_steps = default_max_train_steps / 2; validation & save steps = default_validation & save steps / 2;
卷积计算(默认开启)
在训练循环之前设置torch.backends.cudnn.benchmark = True可以加速计算。
由于计算不同内核大小卷积的 cuDNN 算法的性能不同,自动调优器可以运行一个基准来找到最佳算法。当你的输入大小不经常改变时,建议开启这个设置。
优化器(环境变量开启)
可以用nvidia/apex的优化器fusedAdam,该优化器对参数更新的方式做了融合,使得参数更新变快。
使用方式需2步:
1、Linux安装
git clone https://github.com/NVIDIA/apex
cd apex
# if pip >= 23.1 (ref: https://pip.pypa.io/en/stable/news/#v23-1) which supports multiple `--config-settings` with the same key...
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
# otherwise
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --global-option="--cpp_ext" --global-option="--cuda_ext" ./
2、打开环境变量即可启用
代码已经内置,仅需打开环境变量即可启用
export ENABLE_APEX_OPT=1
混合精度
1、tf32 (环境变量开启)
目前,NVIDIA的Ampere架构的GPU(例如A100、RTX 30系列)支持TF32。
在代码中,如果加载了一些fp32的预训练模型,或者训练过程中使用了fp32的操作,可以使用tf32去加速。TF32使用32位浮点数格式来进行计算,同时使用16位浮点数格式来进行累积操作和存储。这种格式可以提供接近FP32精度的计算结果,同时在存储需求和计算成本方面更加高效。
代码已经内置,仅需打开环境变量即可启用
export ENABLE_TF32=1
2、bf16 (修改启动脚本开启)
目前,NVIDIA的Ampere架构的GPU(例如A100、RTX 30系列)支持BF16。
BF16(BFloat16)是一种特殊的浮点数格式,用于在深度学习和人工智能计算中进行计算和存储。BF16使用16位浮点数来表示数字,但与传统的IEEE 754浮点数格式不同,它将低精度位(低8位)用于表示小数部分,而将高精度位(高8位)用于表示指数部分。

可以修改train_lora.py脚本使用bf16去加速。
加入:
--mixed_precision=bf16
https://github.com/aigc-apps/sd-webui-EasyPhoto
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 人脸模型 | 模型卡片 | 功能 | 使用 |
|---|---|---|---|
| FaceID | insightface | 对矫正后的人脸提取特征,同一个人的特征距离会更接近 | EasyPhoto图片预处理,过滤非同ID人脸EasyPhoto训练中途验证模型效果EasyPhoto预测挑选基图片 |
| 人脸检测 | cv_resnet50_face | 输出一张图片中人脸的检测框和关键点 | 训练预处理,处理图片并抠图预测定位模板人脸和关键点 |
| 人脸分割 | cv_u2net_salient | 显著目标分割 | 训练预处理,处理图片并去除费劲 |
| 人脸融合 | cv_unet-image-face-fusion | 融合两张输入的人脸图像 | 预测,用于融合挑选出的基图片和生成图片,使得图片更像ID对应的人 |
| 人脸美肤 | cv_unet_skin_retouching_torch | 对输入的人脸进行美肤 | 训练预处理:处理训练图片,提升图片质量预测:用于提升输出图片的质量。 |
https://github.com/deepinsight/insightface
https://www.modelscope.cn/models/damo/cv_resnet50_face-detection_retinaface/summary
https://www.modelscope.cn/models/damo/cv_u2net_salient-detection/summary
https://www.modelscope.cn/models/damo/cv_unet-image-face-fusion_damo/summary
更新表格一览
下表展现了更新的表格版本,除了常见环境bug修复和效果提升,还有包含多人写真,风格化,批量推理,SDXL,无模板写真等高级功能,平均迭代速度3天1次。
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 发布功能 | 发布时间 | PR链接 | 介绍 |
|---|---|---|---|
| 多人写真发布 | 230910 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/45 | 支持在一次推理中,完成多人写真 |
| 基础模型选配 | 230910 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/45 | 可在推理中更换基础模型,保持人脸相似度的前提下支持多风格,例如动漫,赛博朋克等。 |
| 人脸相似度显示 | 230914 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/75 | 推理界面高级选项,支持在推理后展示参考图片,并输出人脸相似度 |
| 背景重绘功能 | 230914 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/72 | 在模板推理情况下,可以扩大重绘范围,修改部分背景,发型等区域 |
| diffusers版本发布 | 230922 | https://github.com/aigc-apps/EasyPhoto | 独立diffuers repo,不依赖sdwebui可以完成easyphoto当前功能 |
| 批量推理功能 | 230922 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/110 | 可以上传文件夹,批量完成文件夹内的推理 |
| github-wiki发布加速指南 | 230922 | https://github.com/aigc-apps/sd-webui-EasyPhoto/wiki | 发布加速推理相关指南,A10训练时间从25分钟降低到10分钟 |
| fastapi支持 | 230925 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/114 | 支持全部功能的fastapi调用和调试 |
| 强化学习Lora增强 | 230928 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/109 | 真人写真,不需要使用任何模板,效果大幅提升支持开启强化学习进一步提升Lora提升功能,普遍提升10%以上的人脸相似度。 |
| SDXL-创意生成 | 230928 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/125 | 支持使用SDXL直接生成 |
EasyPhoto当前的版本是基于StableDiffusion文图生成技术和一系列复杂的图像前处理/后处理结合的写真图片生成技术,可能包括的关键词有StableDiffusion,Lora,ControlNet, FaceID, 人脸分割,人脸姿态匹配,人脸颜色转换,人脸融合
1.插件下载
填入地址即可
2.使用
1. 模型训练
EasyPhoto训练界面如下:
- 左边是训练图像。只需点击上传照片即可上传图片,点击清除照片即可删除上传的图片;
- 右边是训练参数,不能为第一次训练进行调整。
点击上传照片后,我们可以开始上传图像这里最好上传5到20张图像,包括不同的角度和光照。最好有一些不包括眼镜的图像。如果所有图片都包含眼镜眼镜,则生成的结果可以容易地生成眼镜。
然后我们点击下面的“开始培训”,此时,我们需要填写上面的用户ID,例如用户名,才能开始培训。
模型开始训练后,webui会自动刷新训练日志。如果没有刷新,请单击“Refresh Log”按钮。
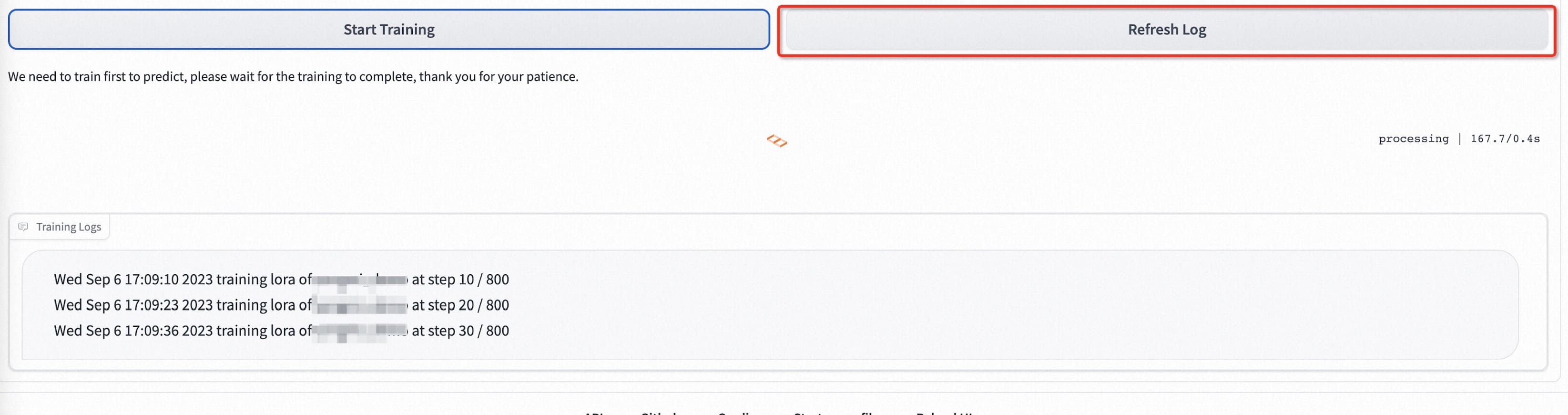
如果要设置参数,每个参数的解析如下:
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 参数名 | 含义 |
|---|---|
| resolution | 训练时喂入网络的图片大小,默认值为512 |
| validation & save steps | 验证图片与保存中间权重的steps数,默认值为100,代表每100步验证一次图片并保存权重 |
| max train steps | 最大训练步数,默认值为800 |
| max steps per photos | 每张图片的最大训练次数,默认为200 |
| train batch size | 训练的批次大小,默认值为1 |
| gradient accumulationsteps | 是否进行梯度累计,默认值为4,结合train batch size来看,每个Step相当于喂入四张图片 |
| dataloader num workers | 数据加载的works数量,windows下不生效,因为设置了会报错,Linux正常设置 |
| learning rate | 训练Lora的学习率,默认为1e-4 |
| rank Lora | 权重的特征长度,默认为128 |
| network alpha | Lora训练的正则化参数,一般为rank的二分之一,默认为64 |
2. 人物生成
a. 单人模版
- 步骤1:点击刷新按钮,查询训练后的用户ID对应的模型。
- 步骤2:选择用户ID。
- 步骤3:选择需要生成的模板。
- 步骤4:单击“生成”按钮生成结果。
b. 多人模板
- 步骤1:转到EasyPhoto的设置页面,设置num_of_Faceid大于1。
- 步骤2:应用设置。
- 步骤3:重新启动webui的ui界面。
- 步骤4:返回EasyPhoto并上传多人模板。
- 步骤5:选择两个人的用户ID。
- 步骤6:单击“生成”按钮。执行图像生成。
算法详细信息
1. 架构概述
在人工智能肖像领域,我们希望模型生成的图像逼真且与用户相似,而传统方法会引入不真实的光照(如人脸融合或roop)。为了解决这种不真实的问题,我们引入了稳定扩散模型的图像到图像功能。生成完美的个人肖像需要考虑所需的生成场景和用户的数字分身。我们使用一个预先准备好的模板作为所需的生成场景,并使用一个在线训练的人脸 LoRA 模型作为用户的数字分身,这是一种流行的稳定扩散微调模型。我们使用少量用户图像来训练用户的稳定数字分身,并在推理过程中根据人脸 LoRA 模型和预期生成场景生成个人肖像图像。
2. 训练细节
首先,我们对输入的用户图像进行人脸检测,确定人脸位置后,按照一定比例截取输入图像。然后,我们使用显著性检测模型和皮肤美化模型获得干净的人脸训练图像,该图像基本上只包含人脸。然后,我们为每张图像贴上一个固定标签。这里不需要使用标签器,而且效果很好。最后,我们对稳定扩散模型进行微调,得到用户的数字分身。
在训练过程中,我们会利用模板图像进行实时验证,在训练结束后,我们会计算验证图像与用户图像之间的人脸 ID 差距,从而实现 Lora 融合,确保我们的 Lora 是用户的完美数字分 身。
此外,我们将选择验证中与用户最相似的图像作为 face_id 图像,用于推理。
3. 推理细节
a. 第一次扩散:
首先,我们将对接收到的模板图像进行人脸检测,以确定为实现稳定扩散而需要涂抹的遮罩。然后,我们将使用模板图像与最佳用户图像进行人脸融合。人脸融合完成后,我们将使用上述遮罩对融合后的人脸图像进行内绘(fusion_image)。此外,我们还将通过仿射变换(replace_image)把训练中获得的最佳 face_id 图像贴到模板图像上。然后,我们将对其应用 Controlnets,在融合图像中使用带有颜色的 canny 提取特征,在替换图像中使用 openpose 提取特征,以确保图像的相似性和稳定性。然后,我们将使用稳定扩散(Stable Diffusion)结合用户的数字分割进行生成。
b. 第二次扩散:
在得到第一次扩散的结果后,我们将把该结果与最佳用户图像进行人脸融合,然后再次使用稳定扩散与用户的数字分身进行生成。第二次生成将使用更高的分辨率。
特别感谢
特别感谢DevelopmentZheng, qiuyanxin, rainlee, jhuang1207, bubbliiiing, wuziheng, yjjinjie, hkunzhe, yunkchen同学们的代码贡献(此排名不分先后)。
参考文献
- insightface:https://github.com/deepinsight/insightface
- cv_resnet50_face:https://www.modelscope.cn/models/damo/cv_resnet50_face-detection_retinaface/summary
- cv_u2net_salient:https://www.modelscope.cn/models/damo/cv_u2net_salient-detection/summary
- cv_unet_skin_retouching_torch:https://www.modelscope.cn/models/damo/cv_unet_skin_retouching_torch/summary
- cv_unet-image-face-fusion:https://www.modelscope.cn/models/damo/cv_unet-image-face-fusion_damo/summary
- kohya:https://github.com/bmaltais/kohya_ss
- controlnet-webui:https://github.com/Mikubill/sd-webui-controlnet
相关项目
我们还列出了一些很棒的开源项目以及任何你可能会感兴趣的扩展项目:
- ModelScope.
- FaceChain.
- sd-webui-controlnet.
- sd-webui-roop.
- roop.
- sd-webui-deforum.
- sd-webui-additional-networks.
- a1111-sd-webui-tagcomplete.
- sd-webui-segment-anything.
- sd-webui-tunnels.
- sd-webui-mov2mov.
许可证
本项目采用 Apache License (Version 2.0).
3.报错排查

命名不能使用中文
第一次使用下载模型较多,请耐心等待。。。。
一、环境问题
0、Autodl 使用官方镜像后遇到 tb-nightly 安装失败
答:不要使用小李启动器,直接运行 python3 launch.py --port 7860 即可正常启动
1、ModuleNotFoundError: No module named ‘launch’
具体报错:Traceback (most recent call last): File “C:\Users\xxx\xxx\sd-webui-EasyPhoto\install.py”, line 1, in import launch ModuleNotFoundError: No module named ‘launch’
答:Easyphoto是一个WebUI插件,需要安装SDWebui后才可以使用。
2、AttributeError: module "insightface’ has no attribute "model_zoo’
答:insightface版本较低,查看是否其他插件要求低版本insightface,可以先关闭其他插件,让easyphoto安装相关依赖。
3、RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
答:一般是模型权重没有下完全,需要查看具体的报错然后重新下载相关的模型权重。
4、ModuleNotFoundError: No module named "Cython’
答:这个一般是旧版秋叶安装包才会出现的问题,旧版的秋叶安装包不包含Cython,需要更新秋叶安装包。
5、requests.exceptions.ConnectionError:HTTPSConnectionPool
具体报错:requests.exceptions.ConnectionError:HTTPSConnectionPool(host=‘pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com’, port=443):Max retries exceeded with url: /webui/control_v11f1e_sd15_tile.pth (Caused by NewConnectionError(‘<urllib3.connection.HTTPSConnection object at 0x7fb23911cd30>: Failed to establish à new connection: (Errno 1101 Connection timed out’))
答:这个是没有使用国内网络导致的,关闭代理即可。后续会更新模型到huggingface,在国外的下载速度会快很多。
6、mouth_mask = face_skin(input_image, retinaface_detection) TypeError: ‘NoneType’ object is not callable
答:权重没下载全,检查一下easyphoto_utils.py下列表里的各个权重是否存在。
7、ModuleNotFoundError: No module named ‘venv’
答:这个问题是windows环境的问题,引入是因为使用了modelscope模型,可以参考modelscope的issue, 2023/10/17,他们还未修复,等到modelscope=1.9.3 更新后应该可以修复,参考链接 https://github.com/modelscope/modelscope/issues/572
8、Image size (222447600 pixels) exceeds Limit of 178956970 pixels, could be decompression bomb DOS
答:图片过大,上传小一些的图片,PIL无法读取太大的图片。
9、h_1, w_1, c_1 = np. shape(processed.images[1]) IndexError: list index out of range
答:这个是旧版本EasyPhoto在秋叶安装包上的问题,更新新版本即可。
10、urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host=‘127.0.0.1’, port=7890)
具体报错:urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host=‘127.0.0.1’, port=7890) : Max retries exceeded with url: http://www.modelscope.cn/api/v1/models/damo/cv_resnet50_face-detection_retinaface (Caused bv ResponseError(‘too manv 502 error responses’))
答:这是modelscope网络不稳定导致的,可以多重试几次。
11、stderr: ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问。
答:如果使用的是秋叶包的话,则是因为没有使用管理员模式运行,右键管理员模式运行即可。
12、AttributeError: ‘Nonetype’: object has no attribute ‘model_name’.
答:重启webui即可。
13、RuntimeError: Couldn’t install requirements for insightface.
答:在Windows下安装insightface需要注意安装visual studio,在如下链接中下载Community版本即可https://visualstudio.microsoft.com/zh-hans/downloads/。安装过程中需要选择C++组件。
14、template images = eval (selected template images) File “string>”, line 0 SyntaxError: invalid syntax
答:没有选中模板图片。需要注意选择模板图片。
15、error: Microsoft Visual C++ 14.0 or greater is required.
具体报错:error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”: https://visualstudio.microsoft.com/visual-cpp-build-tools/
答:在Windows下安装insightface需要注意安装visual studio,在如下链接中下载Community版本即可https://visualstudio.microsoft.com/zh-hans/downloads/。
安装过程中需要选择C++组件。
16、SDXL styles插件冲突:Template 1 error: Error info is expected string or bytes-like object
需要在使用EasyPhoto之前关闭 SDXL styles 插件,否则推理会出问题。
17、秋叶安装包下载地址:
答:https://pan.quark.cn/s/d6ee9d78dc5f
二、使用问题
1、训练中每个参数有什么用:
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 参数名 | 参数解释 | 调整后的影响 |
|---|---|---|
| resolution | 训练时喂入网络的图片大小,默认值为512。 | 调大后会增大显存占用,因为预测时也使用512的大小预测,不推荐调整。 |
| validation & save steps | 验证图片与保存中间权重的steps数,默认值为100,代表每100步验证一次图片并保存权重。 | 调节后会影响训练中验证的次数,间接影响训练速度与最终效果。 假设将其调整为200,总训练步数为800,那么只评估四次,训练速度加快。 因为模型的lora是根据每个验证结果进行融合的,验证少了理论融合效果会降低。 |
| max train steps | 最大训练步数,默认值为800。 | 调节后会影响训练的总步数。 最终训练步数 = Min(图片数 * max_steps_per_photos, max_train_steps) |
| max steps per photos | 每张图片的最大训练次数,默认为200。 | 调节后会影响每张图片的重复训练次数。 最终训练步数 = Min(图片数 * max_steps_per_photos, max_train_steps) |
| train batch size | 训练的批次大小,每个批次喂入模型训练的图片数量,默认值为1。 需要结合gradient accumulationsteps使用,推荐二者相乘为4,代表每个训练step的总图片数为4。 | 调节后影响显存占用与训练速度,如果机器的显存大的话可以将其调整为4以加快训练,但需要同时调节gradient accumulationsteps为1,以保证单次step的总图片数量不变。 |
| gradient accumulationsteps | 是否进行梯度累计,默认值为4。 | 调节后影响训练速度,需要同时调节train batch size,以保证单次step的总图片数量不变。 |
| dataloader num workers | 数据加载的works数量,windows下不生效,因为设置了会报错,Linux正常设置。 | 在cpu资源充足的情况下,设置的值越大,数据加载速度越快,训练速度越快。 |
| learning rate | 训练Lora的学习率,默认为1e-4。 | 一般来讲,每个训练step的总图片数越大,learning rate要越大,有经验的同学再尝试调节。1e-4是多次实验得出的最佳值。 |
| rank | Lora权重的特征长度,默认为128。 | 影响Lora的表征能力、训练速度、与显存占用: 调大后表征能力变强,容易过拟合,训练速度略微下降,显存占用略微上升。 |
| network alpha | Lora训练的正则化参数 | 一般为rank的二分之一,参考rank做调整。 |
2、预测中每个参数有什么用:
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 参数名 | 参数解释 | 调整后的影响 |
|---|---|---|
| Additional Prompt | 正向提示词,会传入Stable Diffusion模型进行预测。 | 可以根据自身希望增加的元素调整prompt词。 |
| Seed | 种子值。 | 用于保证结果的可复现性,为-1时会随机选择一个种子数。 |
| Face Fusion Ratio Before | 第一次人脸融合的强度。 | 调节后会影响人物相似度,一般来讲,值越大与训练人物的相似度越高。 |
| Face Fusion Ratio After | 第二次人脸融合的强度。 | 调节后会影响人物相似度,一般来讲,值越大与训练人物的相似度越高。 |
| First Diffusion steps | 第一次进行Stable Diffusion的总步数。第一次Diffusion主要进行人像区域的调整,使得人像更自然。 | 调节后会影响图片质量与出图速度,一般值越大图片质量越高,出图越慢。 |
| First Diffusion denoising strength | 第一次进行Stable Diffusion的重绘比例。 | 调节后会影响图片的重绘比例与出图速度,一般值越大,人像变动越大。 |
| Second Diffusion steps | 第二次进行Stable Diffusion的总步数。 第二次Diffusion主要进行人像周围区域的调整,使得图片更和谐。 | 调节后会影响图片质量与出图速度,一般值越大图片质量越高,出图越慢。 |
| Second Diffusion denoising strength | 第二次进行Stable Diffusion的重绘比例。 | 调节后会影响图片的重绘比例与出图速度,一般值越大,人像周围变动越大。 |
| Crop Face Preprocess | 是否对人像裁剪后再处理。 | 推荐开启,假设输入的是大图,会对人像区域先做裁剪后再进行人像调整,调整结果更精细。 |
| Apply Face Fusion Before | 是否进行第一次人脸融合。 | 调节后会影响是否进行第一次人脸融合,会影响人像的相似度。 |
| Apply Face Fusion After | 是否进行第二次人脸融合。 | 调节后会影响是否进行第二次人脸融合,会影响人像的相似度。 如果感觉人像发虚则取消该次融合。 |
| Apply color shift first | 是否进行第一次DIffusion后的色彩校正。 | 调节后会影响图片的人像自然程度。 |
| Apply color shift last | 是否进行第二次DIffusion后的色彩校正。 | 调节后会影响图片的人像自然程度。 |
| Background Restore | 是否进行背景的重建。 | 开启后可以对人像区域外背景进行重建,在使用动漫化模型时,可以让整个图片更和谐。 |
3、感觉不太像
答:人像相似度受到多个原因影响,训练图片、预测图片、主观因素都会影响。
首先看训练图片,我们推荐使用 同一个人的 5-20 张头肩照或者半身照进行训练,其中最好包含正面的人像,这样可以让模型更好的学习。并且Easyphoto会在训练一开始 打印所有训练图片的人像相似度,一般来讲,同一个人的人像相似度在0.55-0.70,如果低于该值则说明训练人像本身不够相似,同一个人在不同时期的相片也是不一样的。
然后看预测图片,最简单的例子就是肤色,假设训练图像的肤色和预测图像的肤色完全不同,那么新生成的人像怎么看都会有违和感。
另外,人像相似度是一个比较主观的看法,我们推荐使用face id得分来计算相似度,在指标上来看像不像。Easyphoto在人像相似度与美观之间做了平衡,在保留人像特征的情况下,尽量提高人像的相似度,后续我们会持续优化相似度。
4、为什么我训练完之后在预测界面没有找到自己的user id
答:需要点击右边的刷新按钮才会刷新出来。

5、为什么我训练完预测结果图片发虚
答:可以尝试关闭Apply Face Fusion After,关闭第二次人脸融合,此时图像不再发虚。
6、预测的输出图片在哪里
答:训练好的输出图片在stable-diffusion-webui/outputs/easyphoto-outputs路径下。
7、训练好的模型在哪里
答:训练好的权重文件在stable-diffusion-webui/outputs/easyphoto-user-id-infos中,另外stable-diffusion-webui/models/Lora中也有一份以User id命名的Lora权重。
一个user_id一个文件夹,如果觉得文件大小过大可以进入user_id/user_weights删除中间的safetensors文件,以下内容删除不影响正常预测:
stable-diffusion-webui/outputs/easyphoto-user-id-infos/{user_id}/user_weights/checkpoint-*.safetensors
stable-diffusion-webui/outputs/easyphoto-user-id-infos/{user_id}/user_weights/pytorch_lora_weights.safetensors
8、训练速度太慢了
答:首先查看自己的显卡,如果显存在24G左右(3090与4090)可以尝试将train batch size调整为4,gradient accumulationsteps调整为1。
如果显存在16G左右可以尝试将train batch size调整为2,gradient accumulationsteps调整为2。
另外,适当调整validation & save steps也可以加快训练速度,比如从100调整为200。
9、下载的权重文件太多了,每次启动都要下载吗
答:只需要第一次启动的时候下载一次即可,无需重复下载,插件会自动将每个权重放在对应的位置。
答:可以的,参考 https://github.com/aigc-apps/sd-webui-EasyPhoto/issues/154 , 然后Lora可以单独使用,也可以迁移整体内容,在别的机器上使用EasyPhoto
答:这是一个算法问题,可以通过修改一些参数缓解,具体参考https://github.com/aigc-apps/sd-webui-EasyPhoto/issues/177 讨论
11、总共需要多少权重,以及他们的作用
单页可能未显示完全,可以往右边拉。 答:
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}| 权重名 | 作用 | 下载地址 | 放置位置 |
|---|---|---|---|
| ChilloutMix-ni-fp16.safetensors | 基础的 Stable Diffusion (v1) 模型,在此基础上生成。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/ChilloutMix-ni-fp16.safetensors | stable-diffusion-webui/models/Stable-diffusion |
| SDXL_1.0_ArienMixXL_v2.0.safetensors | 基础的 Stable Diffusion (XL) 模型,在此基础上生成。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/SDXL_1.0_ArienMixXL_v2.0.safetensors | stable-diffusion-webui/models/Stable-diffusion |
| control_v11p_sd15_openpose.pth | 用于进行人像形状的控制,保持轮廓相似 (SD v1)。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/control_v11p_sd15_openpose.pth | stable-diffusion-webui/models/ControlNet |
| control_v11p_sd15_canny.pth | 用于进行人像形状的控制,防止图像崩坏,保持轮廓稳定 (SD v1)。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/control_v11p_sd15_canny.pth | stable-diffusion-webui/models/ControlNet |
| control_v11f1e_sd15_tile.pth | 用于保证图片的高分辨率控制,同时让图像更和谐。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/control_v11f1e_sd15_tile.pth | stable-diffusion-webui/models/ControlNet |
| control_sd15_random_color.pth | 用于保证图片的颜色控制,以适应不同的模板。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/control_sd15_random_color.pth | stable-diffusion-webui/models/ControlNet |
| diffusers_xl_canny_mid.safetensors | 用于进行人像形状的控制,防止图像崩坏,保持轮廓稳定 (SDXL)。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/diffusers_xl_canny_mid.safetensors | stable-diffusion-webui/models/ControlNet |
| FilmVelvia3.safetensors | 用于提供一定的摄影风格。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/FilmVelvia3.safetensors | stable-diffusion-webui/models/Lora |
| body_pose_model.pth | 控制模型的openpose权重之一。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/body_pose_model.pth | stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads/openpose |
| facenet.pth | 控制模型的openpose权重之一。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/facenet.pth | stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads/openpose |
| hand_pose_model.pth | 控制模型的openpose权重之一。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/hand_pose_model.pth | stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads/openpose |
| vae-ft-mse-840000-ema-pruned.ckpt | SD1 VAE权重,可以让生成的更符合真实与生动。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/vae-ft-mse-840000-ema-pruned.ckpt | stable-diffusion-webui/models/VAE |
| madebyollin-sdxl-vae-fp16-fix.safetensors | SDXL VAE权重,支持 fp16,可以让推理更快。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/madebyollin-sdxl-vae-fp16-fix.safetensors | stable-diffusion-webui/models/VAE |
| madebyollin_sdxl_vae_fp16_fix/diffusion_pytorch_model.safetensors | SDXL VAE权重,支持 fp16,可以让训练更快。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/madebyollin_sdxl_vae_fp16_fix/diffusion_pytorch_model.safetensors | stable-diffusion-webui/extensions/sd-webui-EasyPhoto/models/stable-diffusion-xl/madebyollin_sdxl_vae_fp16_fix |
| face_skin.pth | 人像分割模型,可以分割人像的各个区域。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/face_skin.pth | stable-diffusion-webui/extensions/easyphoto-sd-webui/models |
| w600k_r50.onnx | insightface的人脸embedding提取模型。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/w600k_r50.onnx | stable-diffusion-webui/extensions/easyphoto-sd-webui/models/buffalo_l |
| 2d106det.onnx | insightface的人脸检测模型。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/2d106det.onnx | stable-diffusion-webui/extensions/easyphoto-sd-webui/models/buffalo_l |
| det_10g.onnx | insightface的人脸检测模型。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/det_10g.onnx | stable-diffusion-webui/extensions/easyphoto-sd-webui/models/buffalo_l |
| diffusers_xl_canny_full.safetensors | 用于进行人像形状的控制,防止图像崩坏,保持轮廓稳定 (SDXL)。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/diffusers_xl_canny_mid.safetensors | stable-diffusion-webui/models/ControlNet |
| thibaud_xl_openpose.safetensors | 用于进行人像形状的控制,保持轮廓相似 (SDXL)。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/thibaud_xl_openpose.safetensors | stable-diffusion-webui/models/ControlNet |
modelscope模型则缓存在用户目录的cache文件夹下。
训练完的Lora存放在哪??
训练完毕的模型存放位置E:\sd-webui-aki\sd-webui-aki-v4\models\Lora
如何测试自己的Lora参考
SD 大模型 采样方法 Lora 测试
Start face detect
模型进度缓慢,正在进行脸部检测
第一次模型的测试会比较慢

前后模型对比
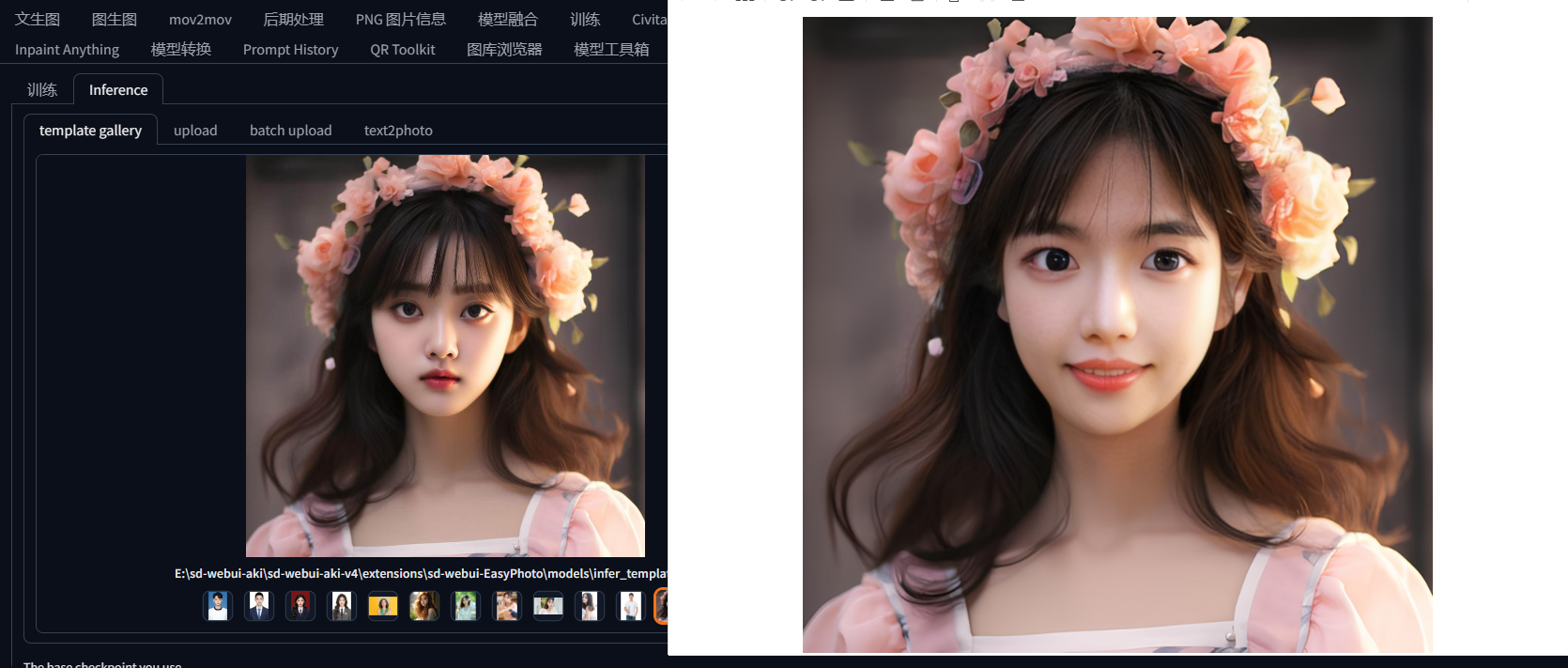


小姐姐2号

测试结果集

Litter sister3
训练素材:
测试结果集:
触发词错误
测试搭配其他Lora稳定性,提示词关联性较高,但是不够有损坏脸型

我正在参与2023腾讯技术创作特训营第三期有奖征文,组队打卡瓜分大奖!















 1802
1802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









