
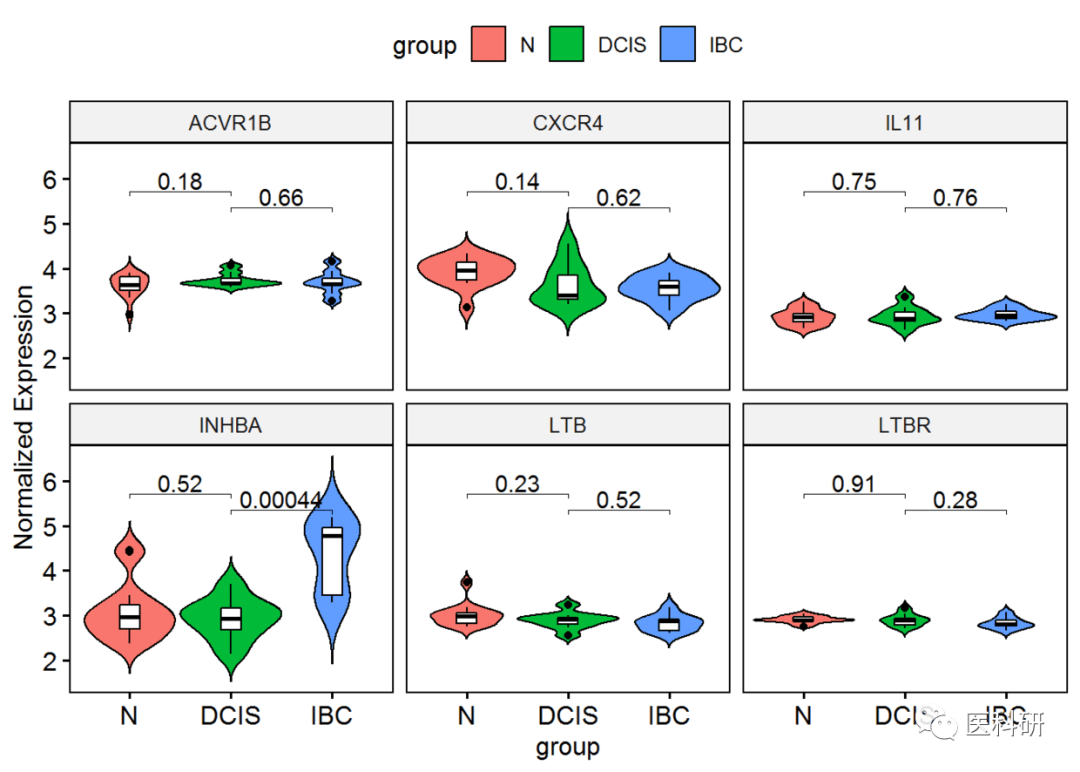
1. 数据准备
# 设定工作目录
data "data.csv",header = T,sep = ",")
colnames(data) "gene",colnames(data)[-1])
test 1:5,1:5]
View(test) # 预览数据集
#
data 2:ncol(data)],by=list(data$gene),FUN = mean, na.rm=T)## 重复基因求平均值
genename rownames(data) data1]
sampleID data1, as.numeric)
rownames(data) ##分组信息构造
group "N",14),rep("DCIS",9),rep("IBC",9),rep("NS",14),rep("DCISS",11),rep("IBCS",9))
length(group) == dim(data)[[1]] ##确认信息匹配
## [1] TRUE
data data$group table(data$group)
##
## DCIS DCISS IBC IBCS N NS
## 9 11 9 9 14 14
data[1:5,1:5] ##行为sample名 列为gene
## ACVR1B CX








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









