







提起Embedding,就不得不提Word2vec,它不仅让词向量在自然语言处理领域再度流行,更为关键的是,自2013年谷歌提出Word2vec以来,Embedding 技术从自然语言处理领域推广到广告、搜索、图像、推荐等深度学习应用领域, 成了深度学习知识框架中不可或缺的技术点。作为经典的Embedding方法,熟悉 Word2vec对于理解之后所有的Embedding相关技术和概念至关重要。
什么是Word2vec?
Word2vec是“word to vector”的简称,顾名思义,Word2vec是一个生成对 “词”的向量表达的模型。
想要训练 Word2vec 模型,我们需要准备由一组句子组成的语料库。
假设其中一个长度为 T 的句子包含的词有 w1,w2……wt,并且我们假定每个词都跟其相邻词的关系最密切(这个假设非常重要)。
根据模型假设的不同,Word2vec 模型分为两种形式,CBOW 模型(图左)和 Skip-gram 模型(图右)。
其中,CBOW 模型假设句子中每个词的选取都由相邻的词决定,因此我们就看到 CBOW 模型的输入是 wt周边的词,预测的输出是 wt。 Skip-gram 模型则正好相反,它假设句子中的每个词都决定了相邻词的选取,所以你可以看到 Skip-gram 模型的输入是 wt,预测的输出是 wt周边的词。按照一般的经验,Skip-gram 模型的效果会更好一些,所以我接下来也会以 Skip-gram 作为框架,来给你讲讲 Word2vec 的模型细节。

Skip-gram(跳字模型)
跳字模型的概念是在每一次迭代中都取一个词作为中心词汇,尝试去预测它一定范围内的上下文词汇。
拿到一个文本,遍历文本中所有的位置,对于文本中的每个位置,我们都会定义一个围绕中心词汇大小为2m的窗口,这样就得到了一个概率分布,可以根据中心词汇给出其上下文词汇出现的概率。我们的目标是选取词汇的向量表示,从而让概率分布值最大化。
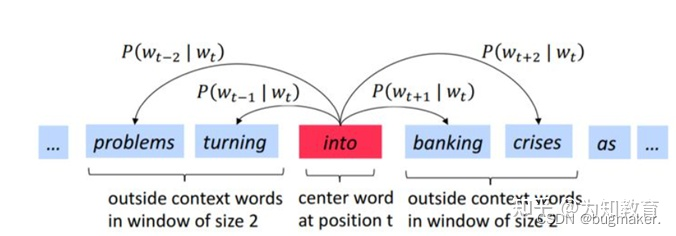
例如,我们已经得到了一个句子:problems turning into banking crises。现在我们记”into“这个词的位置为t,那么"into"这个词用wt表示。”problems“、”turing“、”banking“、“crises"分别表示为wt-2,wt-1,wt+1,wt+2。在已知 “into” 这个词的情况下, ”problems“、”turing“、”banking“、"crises"这四个词出现的条件概率可以表示为P(wt-2|wt),P(wt-1|wt),P(wt+1|wt),P(wt+2|wt)。
现在这个已知的句子就是我们的一个样本,我们要进行第一次迭代,在迭代的过程中,我们的损失函数(或者说目标函数)是这个函数:
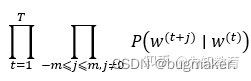
该函数又称为似然函数,这里表示在给定中心词的情况下,在2m窗口内的所有其他词出现的概率(T表示词库里所有词的总数)。我们的目标是要通过调节参数,从而最大化这个函数。根据平时的习惯,我们通常喜欢最小化损失函数,而不是最大化损失函数。因此我们对该函数取负对数,且除以T,得到新的损失函数(对数似然函数):
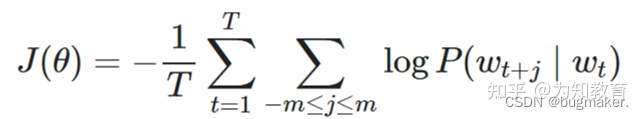
我们现在的任务就是要最小化这个损失函数。
从总体的角度明确了我们的训练任务之后,我们再来看我们具体要训练哪些参数 、如何去进行训练,或者更直观点说:我们怎么利用这些单词向量来最小化负的对数似然函数?
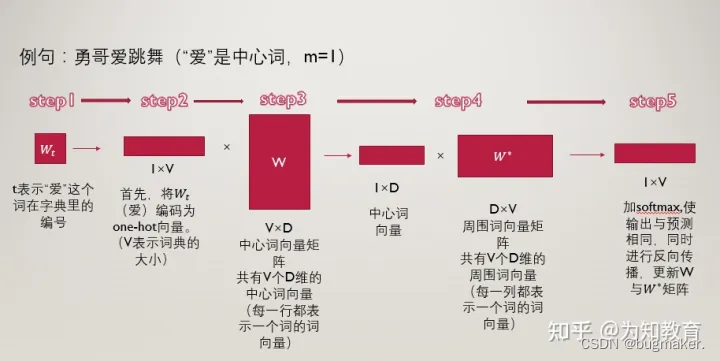
第一步 :t表示“爱”这个词在词典中的位置,那么“爱”用wt表示,“勇哥”用wt-1表示,“跳舞”用wt+1表示。
第二步:将“爱”这个词首先表示为one-hot编码,方便进行后续的矩阵操作。
接下来我们构建两个参数矩阵,分别为中心词矩阵和周围词矩阵,这两个矩阵分别是V×D维和D×V维,其中V表示词典的大小,D表示我们要构建的词向量的维度,是一个超参数,我们暂时认为其是固定的,不去管它。
第三步:用第二步中的得到的,“爱”的one-hot编码乘以中心词向量矩阵W,得到一个1×D维的向量,这个向量可以认为是该词的中心词向量表示。
第四步:用该中心词向量乘以周围词向量矩阵w*,该步骤可以理解为对于“爱”这个词,我们分别与每一个词作内积,最终得到的1×V向量中的每一个元素,便是该位置的词与“爱”这个词的内积大小。
第五步:对于最终的得到的向量,我们再进一步的做softmax归一化,归一化之后的概率越大,表示该词与“爱”的相关性越大,现在我们的目标就是要使得:“勇哥”这个词的概率较大,我们如何去实现这个目标呢?那就是通过调整参数矩阵w和w*,(这里就可以明白这两个矩阵其实只是辅助矩阵,我们根据损失函数,使用反向传播算法来对参数矩阵进行调节,最终实现损失函数的最小化。
WORD2VEC模型的结构
我们最关心的当然是 Word2vec 这个模型的结构是什么样的。它的结构本质上就是一个三层的神经网络。
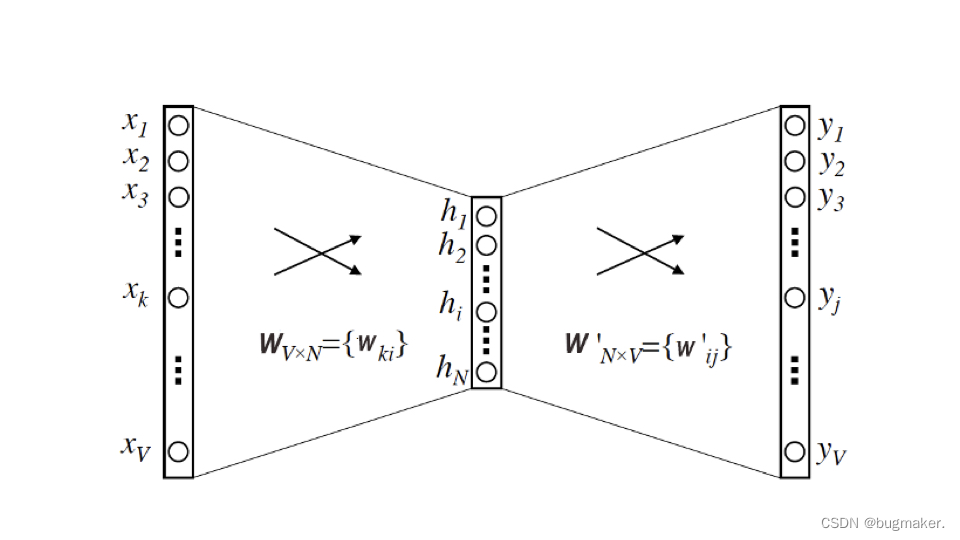
它的输入层和输出层的维度都是 V,这个 V 其实就是语料库词典的大小。假设语料库一共使用了 10000 个词,那么 V 就等于 10000。根据生成的训练样本,这里的输入向量自然就是由输入词转换而来的 One-hot 编码向量,输出向量则是由多个输出词转换而来的 Multi-hot 编码向量,显然,基于 Skip-gram 框架的 Word2vec 模型解决的是一个多分类问题。
隐层的维度是 N,N 的选择就需要一定的调参能力了,我们需要对模型的效果和模型的复杂度进行权衡,来决定最后 N 的取值,并且最终每个词的 Embedding 向量维度也由 N 来决定。
最后是激活函数的问题,这里我们需要注意的是,隐层神经元是没有激活函数的,或者说采用了输入即输出的恒等函数作为激活函数,而输出层神经元采用了 softmax 作为激活函数。
怎样把词向量从Word2vec模型中提取出来?
在训练完 Word2vec 的神经网络之后,可能你还会有疑问,我们不是想得到每个词对应的 Embedding 向量嘛,这个 Embedding 在哪呢?其实,它就藏在输入层到隐层的权重矩阵 WVxN中。我想看了下面的图你一下就明白了。
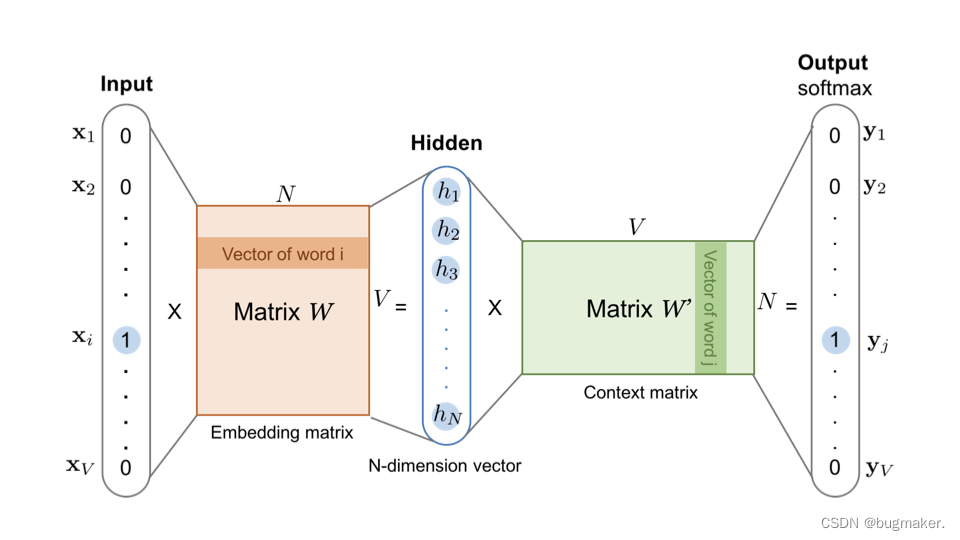
你可以看到,输入向量矩阵 WVxN 的每一个行向量对应的就是我们要找的“词向量”。比如我们要找词典里第 i 个词对应的 Embedding,因为输入向量是采用 One-hot 编码的,所以输入向量的第 i 维就应该是 1,那么输入向量矩阵 WVxN 中第 i 行的行向量自然就是该词的 Embedding 啦。细心的你可能也发现了,输出向量矩阵 W′ 也遵循这个道理,确实是这样的,但一般来说,我们还是习惯于使用输入向量矩阵作为词向量矩阵。
Word2vec的训练方法
虽然上面给出了Word2vec的模型结构和训练方法,但事实上,完全遵循原始的Word2vec多分类结构的训练方法并不可行。假设语料库中的词的数量为 10000,就意味着输出层神经元有10000个,在每次迭代更新隐层到输出层神经元的权重时,都需要计算所有字典中的所有10000个词的预测误差(prediction error) ,在实际训练过程中几乎无法承受这样巨大的计算量。
为了减轻Word2vec的训练负担,我们可以采用以下几种方法:
1、 把常见的词组作为单词
“Boston Globe“(一家报社名字)这种词对,和两个单词 Boston/Globe有着完全不同语义。所以更合理的是把“Boston Globe“看成一个单词,有他自己的word vector。
2、少采样常见的词
像“the“这种常见的词,会经常在文本中出现,然而我们并不需要那么多the的样本。所以word2vec采用了降采样的策略。对于每个我们在训练样本中遇到的词,我们有一个概率去删除它,称之为“采样率”这个概率与单词出现的频率相关。我们使用wi来表示单词,z(wi)表示它出现在词库中的概率(频率)。下面这个等式代表保留这个词的概率:
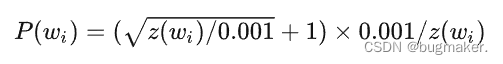
3、负采样
如果 vocabulary 大小为10000时, 当输入样本 ( “fox”, “quick”) 到神经网络时, “ fox” 经过 one-hot 编码,在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。负采样的想法也很直接 ,将随机选择一小部分的负样本,比如选 10个来更新对应的权重参数。在此情况下,Word2vec模型的优化目标从一个多分类问题退化成了一个近似二分类问题,如下所示。
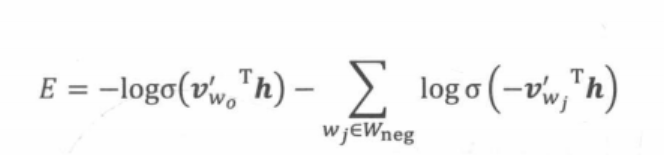
其中是输出词向量(即正样本),h是隐层向量,V’wj是负样本词向量。由于负样本集合的大小非常有限(在实际应用中通常小于10),
在每轮梯度下降的迭代中,计算复杂度至少可以缩小为原来的1/1000 (假设词表大小为10000)。
问题来了,如何选择10个negative sample呢?
我们以通过负采样得到k个负例为例。如果词汇表的大小为V,那么我们就将一段长度为1的线段分成V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短(其实线段长度就是权重,权重高的词在采样过程中被选取的此数就多)。每个词w的线段长度由下式决定:
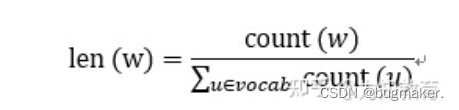
在采样前,我们将这段长度为1的线段划分成M等份,这里M>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要生成0-1之间的K个随机数,就可以完成采样了,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。
实际上,加快 Word2vec训练速度的方法还有Hierarchical softmax (层级 softmax ),但实现较为复杂,且最终效果没有明显优于负采样方法,因此较少采用。
Word2vec在其他领域的应用——Item2vec
在Word2vec诞生之后,Embedding的思想迅速从自然语言处理领域扩散到 几乎所有机器学习领域,推荐系统也不例外。既然Word2vec可以对词“序列” 中的词进行Embedding,那么对于用户购买“序列”中的一个商品,用户观看 “序列” 中的一个电影,也应该存在相应的Embedding方法,这就是Item2vec方法。
Item2vec的基本原理
矩阵分解部分曾介绍过,通过矩阵分解产生了用户隐向量和物品隐向量,如果从Embedding的角度看待矩阵分解模型,则用户隐向量和物品隐向量就是一种用户Embedding向量和物品Embedding向量。由于Word2vec的流行,越来越多的Embedding方法可以被直接用于物品Embedding向量的生成,而用户Embedding向量则更多通过行为历史中的物品Embedding平均或者聚类得到。利用用户向量和物品向量的相似性,可以直接在推荐系统的召回层快速得到候选集合,或在排序层直接用于最终推荐列表的排序。正是基于这样的技术背景, 微软于2016年提出了计算物品Embedding向量的方法Item2vec。
相比Word2vec利用“词序列”生成词Embedding。Item2vec利用的“物品序列”是由特定用户的浏览、购买等行为产生的历史行为记录序列。
假设Item2vec中一个长度为K的用户历史记录为w1,w2,…,wt,类比 Word2vec, Item2vec的优化目标如下所示。
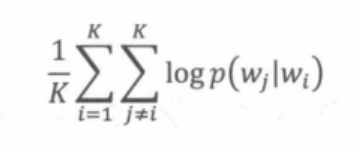
Item2vec与Word2vec唯一的不同在于,Item2vec摒弃了时间窗口的概念,认为序列中任意两个物品都相关, 因此在ltem2vec的目标函数中可以看到,其是两两物品的对数概率的和,而不仅是时间窗口内物品的对数概率之和。
在优化目标定义好之后,Item2vec剩余的训练过程和最终物品Embedding的产生过程都与Word2vec完全一致,最终物品向量的查找表就是Word2vec中词向量的查找表。
广义上的Item2vec
事实上,Embedding对物品进行向量化的方法远不止Item2vec。广义上讲, 任何能够生成物品向量的方法都可以称为Item2vec。典型的例子是曾在百度、 Facebook等公司成功应用的双塔模型。

在广告场景下的双塔模型中,广告侧的模型结构实现的其实就是对物品进行 Embedding的过程。该模型被称为“双塔模型”,因此以下将广告侧的模型结构 称为“物品塔”。那么,“物品塔”起到的作用本质上是接收物品相关的特征向量。 经过物品塔内的多层神经网络结构,最终生成一个多维的稠密向量。从Embedding 的角度看,这个稠密向量其实就是物品的Embedding向量,只不过Embedding 模型从Word2vec变成了更为复杂灵活的“物品塔”模型,输入特征由用户行为 序列生成的one-hot特征向量,变成了可包含更多信息的、全面的物品特征向量。 二者的最终目的都是把物品的原始特征转变为稠密的物品Embedding向量表达, 因此不管其中的模型结构如何,都可以把这类模型称为“广义”上的Item2vec 类模型。
Item2vec方法的特点和局限性
Item2vec作为Word2vec模型的推广,理论上可以利用任何序列型数据生成 物品的Embedding向量,这大大拓展了 Word2vec的应用场景。广义上的Item2vec 模型其实是物品向量化方法的统称,它可以利用不同的深度学习网络结构对物品 特征进行Embedding化。
Item2vec方法也有其局限性,因为只能利用序列型数据,所以Item2vec在处 理互联网场景下大量的网络化数据时往往显得捉襟见肘,这就是Graph Embedding技术出现的动因。














 1394
1394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









