







 DIN模型是一种用于电商广告推荐的点击率预估模型,它基于BaseModel结构,通过引入注意力机制来考虑用户历史行为的重要性。激活单元计算商品与广告的关联权重,提高推荐的准确性。为防止过拟合,DIN采用了mini-batch正则化方法,并使用Dice激活函数适应数据分布变化,优化训练过程。
DIN模型是一种用于电商广告推荐的点击率预估模型,它基于BaseModel结构,通过引入注意力机制来考虑用户历史行为的重要性。激活单元计算商品与广告的关联权重,提高推荐的准确性。为防止过拟合,DIN采用了mini-batch正则化方法,并使用Dice激活函数适应数据分布变化,优化训练过程。
DIN 模型的应用场景是阿里最典型的电商广告推荐, DIN 模型本质上是一个点击率预估模型。
Base Model
下图是 DIN 的基础模型 Base Model。我们可以看到,Base Model 是一个典型的 Embedding MLP 的结构。它的输入特征有用户属性特征(User Proflie Features)、用户行为特征(User Behaviors)、候选广告特征(Candidate Ad)和场景特征(Context Features)。
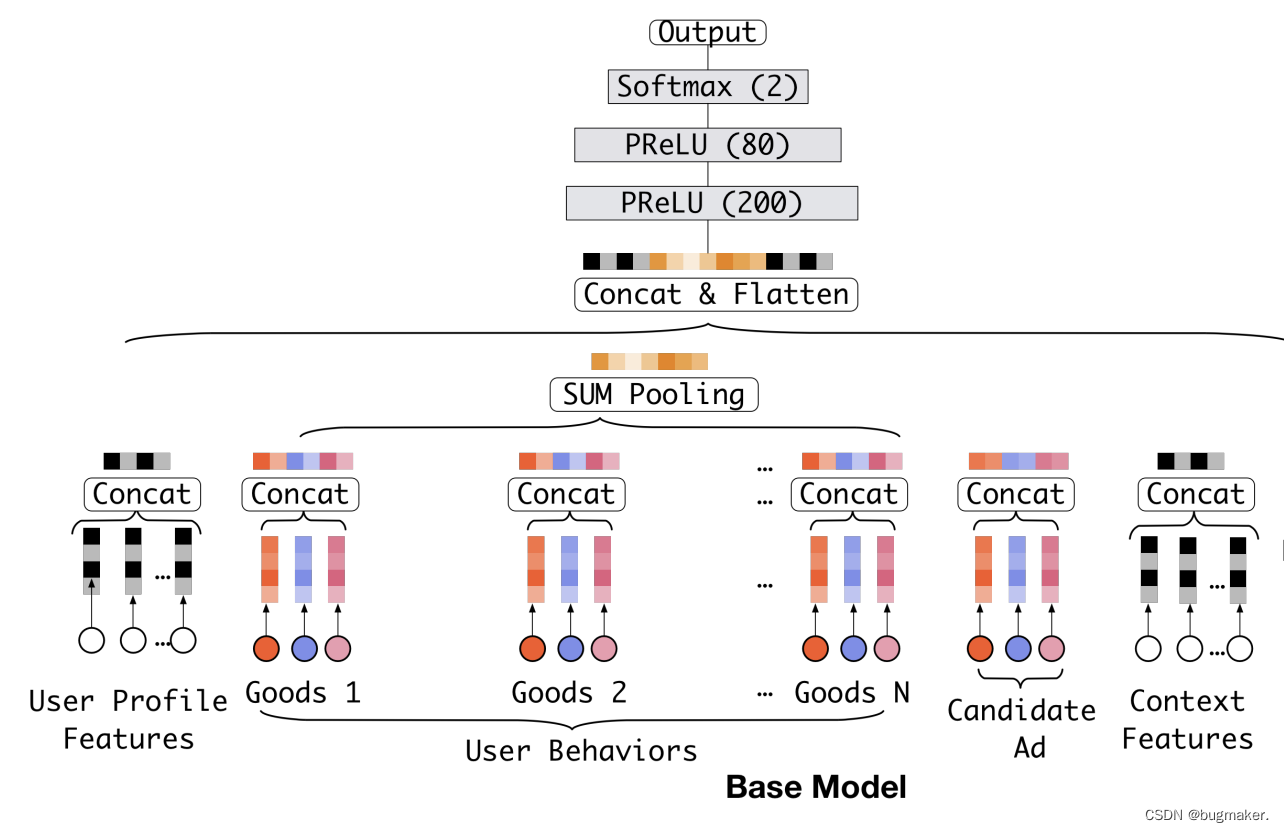
这里我们重点关注用户的行为特征和候选广告特征,也就是图中彩色的部分。
我们可以清楚地看到,用户行为特征是由一系列用户购买过的商品组成的,也就是图上的 Goods 1 到 Goods N,而每个商品又包含了三个子特征,也就是图中的三个彩色点,其中红色代表商品 ID,蓝色是商铺 ID,粉色是商品类别 ID。同时,候选广告特征也包含了这三个 ID 型的子特征,因为这里的候选广告也是一个阿里平台上的商品。
阿里的 Base Model 把三个 ID 转换成了对应的 Embedding。由于用户的行为序列是一组商品的序列,这个序列可长可短,为了把这一组商品的 Embedding 处理成一个长度固定的 Embedding ,阿里使用 SUM Pooling 层直接把这些商品的 Embedding 叠加起来,然后再把叠加后的 Embedding 跟其他所有特征的连接结果输入 MLP。
DIN模型结构
这个时候问题来了,SUM Pooling 的 Embedding 叠加操作其实是把所有历史行为一视同仁,没有任何重点地加起来,这其实并不符合我们购物的习惯。阿里正是在 Base Model 的基础上,把注意力机制应用在了用户的历史行为序列的处理上,从而形成了 DIN 模型。我们可以从下面的 DIN 模型架构图中看到,与 Base Model 相比,DIN 为每个用户的历史购买商品加上了一个激活单元(Activation Unit),这个激活单元生成了一个权重,这个权重就是用户对这个历史商品的注意力得分,权重的大小对应用户注意力的高低。
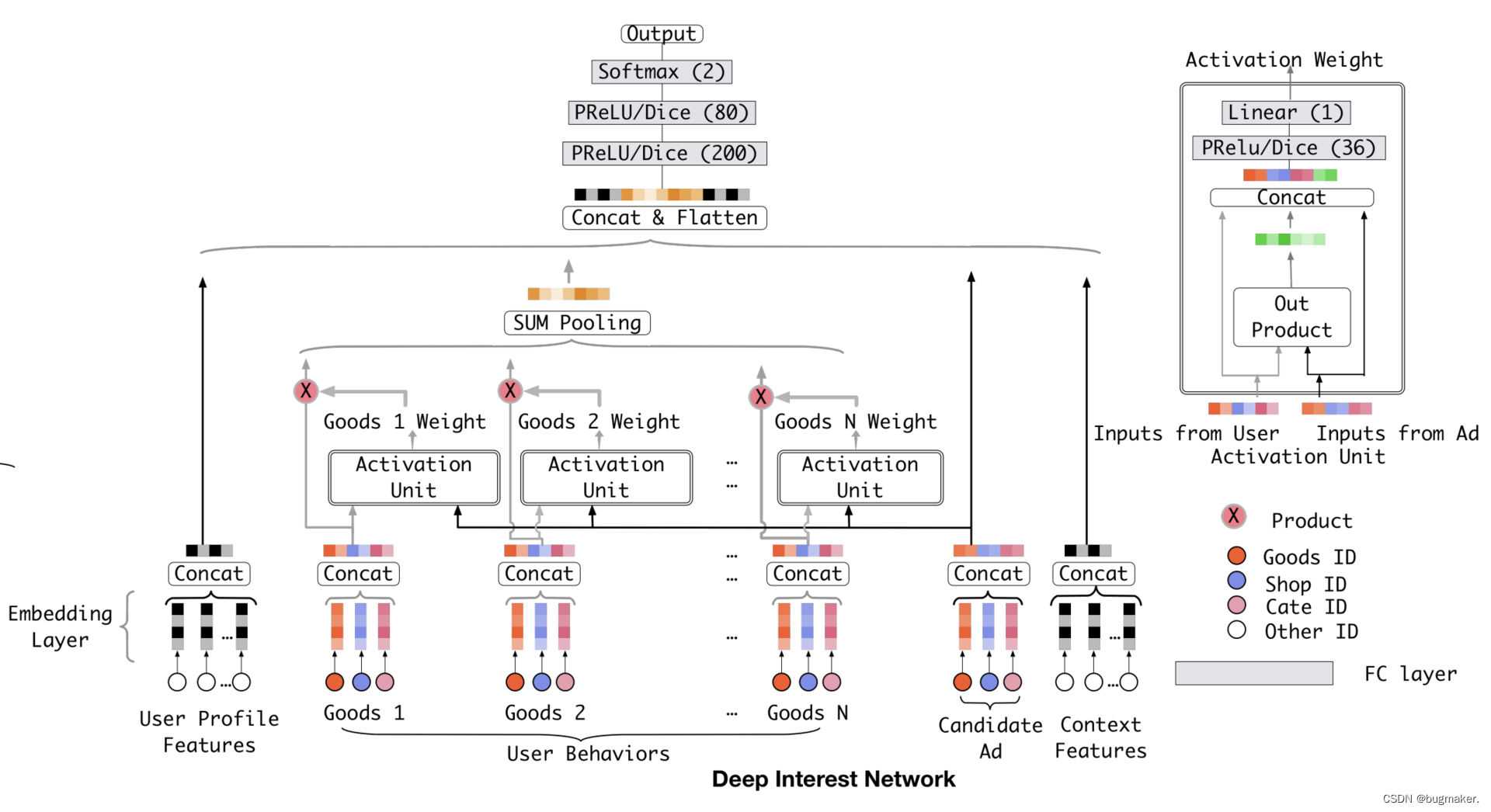
这个所谓的激活单元,到底是怎么计算出最后的注意力权重的呢?一起来看看图右上角激活单元的详细结构。
它的输入是当前这个历史行为商品的 Embedding(q),以及候选广告商品的 Embedding§。我们把[q,p,q-p,qp]concat起来形成一个向量,再输入给激活单元的 MLP 层,最终会生成一个注意力权重,这就是激活单元的结构。简单来说,激活单元就相当于一个小的深度学习模型,它利用两个商品的 Embedding,生成了代表它们关联程度的注意力权重。
注意,激活单元的输入实际上包括了丰富的信息,涵盖了加减乘三种,包括了线性和非线性,低阶和高阶,是attention效果的一个关键点。concat后进行全连接操作,相当于进行了加; q-p表示了两者的差异信息; qp可以理解为对两者进行了特征交叉,具有高阶性。
DIN训练方式
1、mini-batch正则化
我们可以注意到,DIN使用了非常多的ID类型特征。业界基于id特征训练的模型,容易出现过拟合问题。为了防止模型过拟合,通常采用正则化的方式。然而,传统的正则化方法,如L2和L1正则化,直接应用于具有稀疏输入和数亿个参数的训练网络是不现实的。以L2正则化为例。在基于SGD的无正则化优化方法的场景中,只需更新每个小批量中出现的非零稀疏特征的参数。然而,当添加L2正则化时,它需要计算每个小批的整个参数的l2范数,这导致了极其繁重的计算,并且是不可接受的,因为参数扩展到数亿。为了减少计算量,提升训练速度,论文提出基于mini-batch的正则化。该方法的思路是只对batch中出现的非0值sparse特征对应的参数进行正则化。

2、Dice激活函数
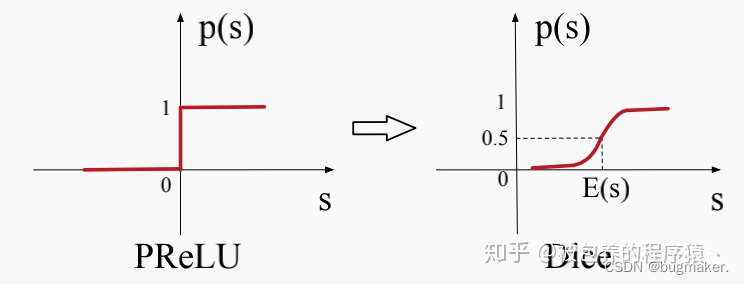
深度学习的训练过程需要经过多层网络的叠加,每一层参数的更新会导致该层预测输出的数据分布发生改变(当验证数据与训练数据不满足独立同分布时,会导致该层输出的数据分布变化非常剧烈),后几层神经网络的数据分布变化会尤为剧烈,若激活函数使用ReLu、PReLu等,当数据分布集中在x轴的负半轴,落入激活函数的饱和区,则参数更新缓慢甚至不会更新,产生梯度消失的问题。
目前的解决办法:
1.可以使用BN层将上层网络输出的数据分布移到x轴的正半轴,移到梯度变化较快的地方
2.那么可以不可以移动激活函数,让它适应上层网络输出的数据分布?基于上述思想,Dice激活函数诞生了!
思路1:将激活函数移动到每次输入的数据所分布的区域
思路2:将激活函数的拐点变得更加平滑
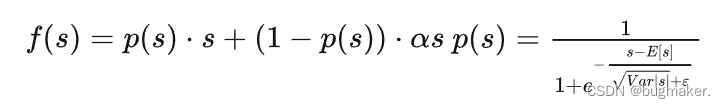


















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









