







将离散特征onehot(multihot)编码后,相乘对应特征的embedding矩阵,获取稠密向量
如果是multihot编码与对应embedding矩阵相乘以后,会得到一个列表(多个embedding向量组合)
2.池化层pooling layer层:只输入表示用户行为的embedding列表(multihot编码* 对应用户行为的物品embedding矩阵),将不同用户的历史行为embedding转成定长向量
因为每个用户的历史商品数量不同,multihot中的1元素不同,则经过embedding层一回合获取的列表不一样长,而全连接网络输入,需要定长的特征输入。所以使用pooling layer层来固定特征长度。
pooling layer层公式如下:
e i = p o o l i n g ( e i 1 , e i 2 , . . . e i k ) e_i=pooling(e_{i1}, e_{i2}, ...e_{ik}) ei=pooling(ei1,ei2,...eik)
e i j e_{ij} eij表示用户行为的embedding列表。 e i e_i ei为转换后表示用户行为的定长向量,这里的 i i i表示(我个人认为是表示第 i i i个用户)[第 i i i个历史特征组(是历史行为,比如历史的商品id,历史的商品类别id等)], 这里的 k k k表示对应第i个用户历史购买过的商品数量,也就是历史行为embedding的个数。
3.Concat&Faltten层:将所有特征embedding向量拼接整合,作为MLP的输入
4.多层感知机(MLP)层:普通的全连接,用来学习特征交互
神经网络目前有很多,如误差反向传播(Back Propagation,BP)神经网路、概率神经网络、卷积神经网络(Convolutional Neural Network ,CNN-适用于图像识别)、时间递归神经网络(Long short-term Memory Network ,LSTM-适用于语音识别)等
神经网络有三个基本要素:权重、偏置和激活函数
>权重:神经元的连接强度
>偏置:
>激活函数:非线性映射,将神经元的输出幅度在一定范围内,限制在(-1,1),(0-1)
>常见激活函数有:Sigmoid函数,tanh函数,relu函数等
神经网络的训练:
就是神经元权重参数的更新,基于求导的链式法则的梯度反向传播
前向传播:在当前网络的权重、偏置和激活函数作用下,得到模型对输入的预测
利用损失函数来计算模型损失
反向传播:利用梯度下降法计算神经元中权重的梯度,借此更新神经网络的权重
MLP是最基本的神经网络,包含输入层,隐层,输出层
MLP神经网络中不同层都是全连接的(全连接:指上一层的任何神经元与下一层均有连接)
输入层:输入变量X
输入层-》隐藏层:X1=f(W1X+b1) ,W1输入层到隐藏层的权重,b1是偏置,f是对应层的激活函数
隐藏层-》输出层:softmax(W2X1+b2),X1表示隐藏层的输出,W2和b2类似,softmax是隐藏层到输出层的激活函数,可以看做一个多类别的逻辑回归
5.LOSS损失函数 :在电商网站中的点击率预测任务,属于二分类,对应损失函数使用二元交叉熵来衡量
L = − 1 N ∑ ( x , y ) ∈ S ( y log p ( x ) + ( 1 − y ) log ( 1 − p ( x ) ) ) L=-\frac{1}{N} \sum_{(\boldsymbol{x}, y) \in \mathcal{S}}(y \log p(\boldsymbol{x})+(1-y) \log (1-p(\boldsymbol{x}))) L=−N1(x,y)∈S∑(ylogp(x)+(1−y)log(1−p(x)))
3.2DIN模型
改进
在base模型的结构基础上,在用户行为特征embedding上,增加local activation unit单元。
该单元位于embedding层和pooling层之间。
根据用户的历史行为特征和当前广告相关性给用户行为特征embedding加权。
模型结构
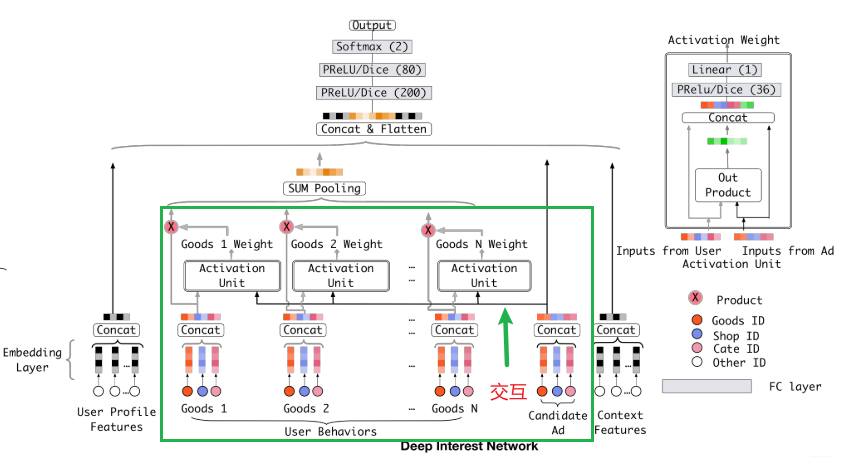
local activation unit是前馈神经网络,输入用户历史行为和当前的候选商品,输出其关联性,将该关联性作为每个历史商品的权重,把该权重与原历史行为embedding相乘求和获取用户兴趣表示 v U ( A ) \boldsymbol{v}_{U}(A) vU(A), 计算公式如下:
v U ( A ) = f ( v A , e 1 , e 2 , … , e H ) = ∑ j = 1 H a ( e j , v A ) e j = ∑ j = 1 H w j e j \boldsymbol{v}_{U}(A)=f\left(\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\right)=\sum_{j=1}^{H} a\left(\boldsymbol{e}_{j}, \boldsymbol{v}_{A}\right) \boldsymbol{e}_{j}=\sum_{j=1}^{H} \boldsymbol{w}_{j} \boldsymbol{e}_{j} vU(A)=f(vA,e1,e2,…,eH)=j=1∑Ha(ej,vA)ej=j=1∑Hwjej
这里的
{
v
A
,
e
1
,
e
2
,
…
,
e
H
}
\{\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\}
{vA,e1,e2,…,eH}是用户
U
U
U的历史行为特征embedding,
v
A
v_{A}
vA表示的是候选广告
A
A
A的embedding向量,
a
(
e
j
,
v
A
)
=
w
j
a(e_j, v_A)=w_j
a(ej,vA)=wj表示的权重或者历史行为商品与当前广告
A
A
A的相关性程度。
a
(
⋅
)
a(\cdot)
a(⋅)表示的上面那个前馈神经网络,也就是那个所谓的注意力机制。
当然,看图里的话,输入除了历史行为向量和候选广告向量外,还加了一个它俩的外积操作,作者说这里是有利于模型相关性建模的显性知识。
这里的权重是直接计算的scores分数,是为了保留用户的兴趣强度
3.3DIN模型的实现
前提处理
1.DIN模型的应用场景基于用户的历史行为,历史行为是序列形式的特征。
2.不同用户的历史行为特征不同,而全连接网络要求输入序列等长,按照最长的序列使用padding(不够长的填0)操作来构造用户行为特征,具体运算时采用mask掩码来标记填充位置
数据处理
DIN的输入数据分为 Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型)即历史行为数据。
Dense数值型特征:为每个数值型特征建立输入层,接收输入,将所有数值型特征拼接起来
Sparse离散型特征:为离散型特征建立Input层接收,通过embedding层转成低纬稠密向量,然后拼接存放。将候选商品的embedding向量提出,单独存放。后期计算用户历史行为的相关性。
VarlenSparse(变长离散型)指用户历史行为特征:对该特征进行padding处理,然后建立对应特征的input层接收输入,通过embedding层,获取用户商品历史记录的embedding列表。将该embedding列表与候选商品的embedding向量放入AttentionPoolinglayer,获取相关性权重,最后获取输出。
将处理好的连续特征,离散特征,和处理后的用户历史行为数据(用户兴趣embedding向量)进行拼接,输入DNN网络,获取结果。














 2288
2288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









