







概念介绍
向量空间模型(VSM:Vector Space Model)由Salton等人于20世纪70年代提出,并成功地应用于文本检索系统。
VSM概念简单,把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间 的相似性来度量文档间的相似性。文本处理中最常用的相似性度量方式是余弦距离。
M个无序特征项ti,词根/词/短语/其他每个文档dj可以用特征项向量来表示(a1j,a2j,…, aMj)权重计算,N个训练文档AM*N= (aij) 文档相似度比较
向量空间模型 (或词组向量模型) 是一个应用于信息过滤,信息撷取,索引以及评估相关性的代数模型。
算法原理
1.计算权重(Term weight)的过程。
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中, this出现的次数更多,就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说
明,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
我们来看一下模型公式:
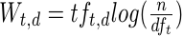
说明:

这仅仅只term weight计算公式的简单典型实现。实现全文检索系统的人会有自己的实现, Lucene就与此稍有不同。
2.判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
如图:
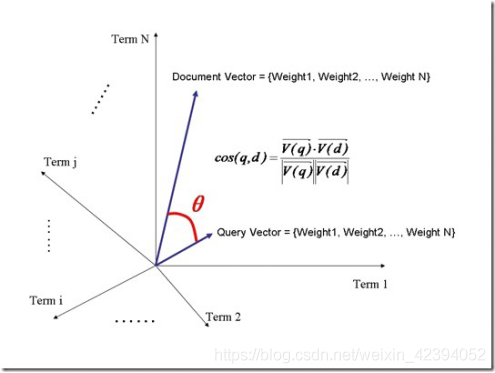
我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
相关性打分公式如下
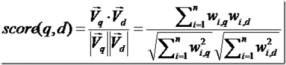
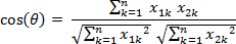
举个例子,查询语句有11个Term,共有三篇文档搜索出来。其中各自的权重(Term weight), 如下表格。

于是计算,三篇文档同查询语句的相关性打分分别为:
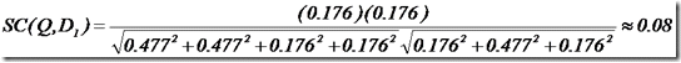
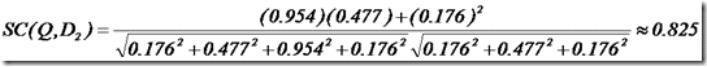
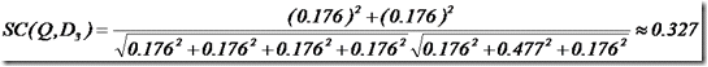
于是文档二相关性最高,先返回,其次是文档一,最后是文档三。
到此为止,我们可以找到我们最想要的文档了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









