







# 导入pandas
import pandas as pd数据如下:
file_info = [
{'id': 'CCH204',
'email': 'cchippendale0@instagram.com',
'date': '06/07/8020',
'mac': 'BA:1C:99:10:4A:D3',
'file_name': 'TempusSemper.avi',
'url': 'http://sohu.com',
'time12': '6:25 PM',
'time24': '20:22',
'numbers': 559,
'html': '<address>'},
{'id': 'JMU2^^',
'email': 'jmusk1@netscape.com',
'date': '07/21/2020',
'mac': 'EA:33:74:C3:64:FB',
'file_name': 'NisiNam.jpeg',
'url': 'http://imgur.com',
'time12': '12:05 AM',
'time24': '3:40',
'numbers': 570,
'html': '</ul>'},
{'id': 'SSH279',
'email': 'ssherbrooke2@list-manage_com',
'date': '09/12/2019',
'mac': '1C:FD:AF:07:FE:42',
'file_name': 'UltriciesEuNibh.mp3',
'url': 'http://ihg.com',
'time12': '5:58 AM',
'time24': '9:51',
'numbers': -977,
'html': '<op^group>'},
{'id': 'RBO218',
'email': 'rboustead3@shutterfly.com',
'date': '07/25/2020',
'mac': '96:95:30:D9:D1:15',
'file_name': 'MusEtiamVel.mp3',
'url': 'http://umn_edu',
'time12': '7:28 PM',
'time24': '4:27',
'numbers': 685,
'html': '<^body>'},
{'id': 'ZFA290',
'email': 'zfabri4@biblegateway_com',
'date': '10/13/2019',
'mac': '00:2B:B1:3C:36:79',
'file_name': 'Penatibus.tiff',
'url': 'https://gizmodo.com',
'time12': '13:70 PM',
'time24': '1:10',
'numbers': 919,
'html': '<kbd>'}
]建立一个DataFrame
df = pd.DataFrame(file_info)看一下数据
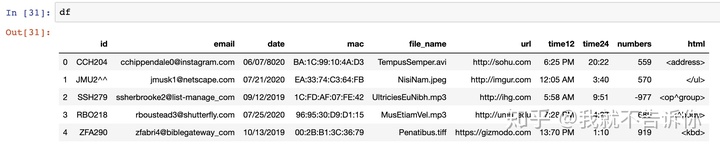
我发现第一条记录的date有错,日期写成了8020年,根据前面的知识,我们很容易修改这个错误。
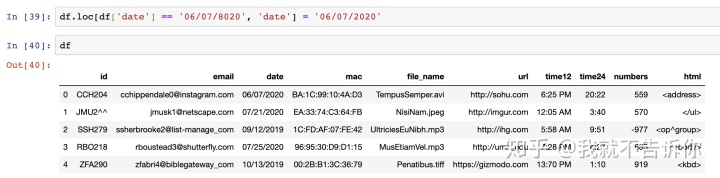
不过如果数据真的只有这么少,我想大家不介意直接把源数据修改一下。
在实际应用中,我们要处理的数据是几万、几十万条,所以这样的操作是不行的。复杂的条件判断和数据梳理离不开正则表达式,我们今天就来看看正则表达式在Pandas中的应用。
我们要找出数据中所有的图片记录:
pattern = r'(?i)(w+).(jpeg|jpg|png|gif|tiff|svg)$'
df82['file_name'].str.contains(pattern,regex=True).value_counts()这里用到了DataFrame的contains包含函数和value_ccounts()的统计函数。

能够看到结果是有两条记录符合条件,另外3条不符合,返回了False。
这两个函数会经常配合使用,咱们再来看看id以A-R开头的记录都有哪些?

公司几千上万人怎么检查资料是否合法呢?来看一个email合法检查的例子。
pattern = r"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+$)"这是一个标准的正则表达式,我相信很多人都用它练习过如何取得email地址。

这样的判断在Python中的常用形式。
那么这样的正则表达式在Pandas中是如何应用的呢?
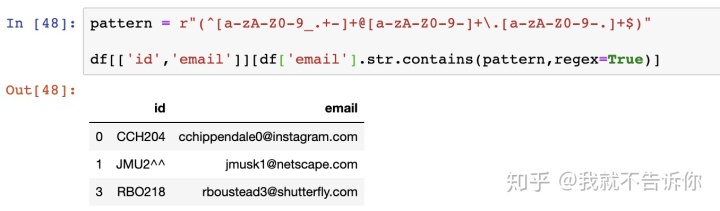
只需要在contains()中加入pattern实例就可以了,如同在Python中一样自由。
一共5条记录,其中有3条记录的email地址是合法的,那么另外两条呢?怎样选出非法的记录?
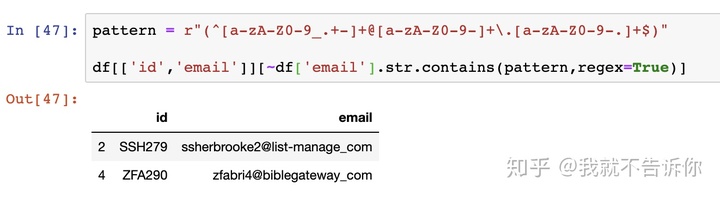
注意观察,我在前面的基础上加了”~“字符,还记得Python中”~“代表什么吗?是”非“运算,如同in和not in一样,与”&“或”|“和”~“操作存在于所有高级语言。
我们可以把以前学习Python正则表达式时做的练习都拿过来试试。
比如:
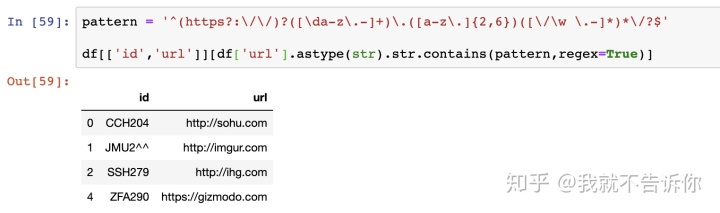
上面是合法的网址,下面则是不合法的。

筛查数据是否合法
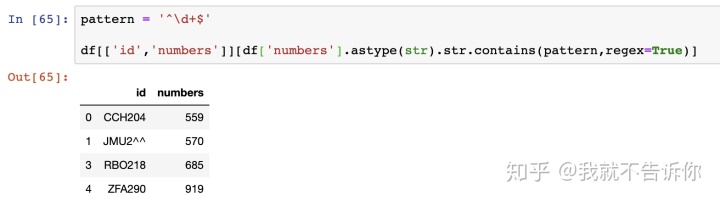
此处注意:numbers是整型,参与字符判断要转换为字符串astype(str)就是类型转换函数。
输出为4条记录,还有一条可能有问题,我们来看看。

原因是这条数据是负数。在实际工作中对数字的要求不完全一样,你可以尝试调整pattern实例。
当然,如果你只想选出负数来,也可以这样。

正确的做法是允许正负数存在。
pattern = '^-{0,1}d+$'这是标准的数据选取实例。
由于数据可能是小数,我给出小数的正负判断实例,你可以在自己的数据中尝试。
正数
pattern = '^d*.{0,1}d+$'负数
pattern = '^-d*.{0,1}d+$'所有合法数据
pattern = '^-{0,1}d*.{0,1}d+$'上来我们就提到的日期合法性
pattern = '^(0[1-9]|1[0-2])/(0[1-9]|1d|2d|3[01])/(19|20)d{2}$'对12小时制的判断
pattern = r'^(1[012]|[1-9]):[0-5][0-9](s)?(?i)(am|pm)$'这是24小时制的判断
pattern = r'^([0-1]{1}[0-9]{1}|20|21|22|23):[0-5]{1}[0-9]{1}$'这些知识都是在Python学习中我们接触过的,大家可以利用上面给出的,并结合自己工作数据的特点进行练习。















 4141
4141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









