







好歹学习了一段时间的WEB搜索技术,尝试着设计一个WEB搜索技术相关的系统。
思来想去,做了一个选课推荐系统,毕竟每年的选课时间都和打架一样。到处问学长学姐,在网上找各种各样的相关信息,跑到每个课堂上去试听。太痛苦。
所以方案里面写的需求都是我和同学们真正的翘首以盼的功能需要。
学分管理与选课推荐系统方案设计
目录
1. 引言
1.1 项目背景
在高校中,对于不同的学生而言,学习方法各异、对于不同的教师的教学方式也各有偏好、同时往往具有不同的听课目的,如何在繁杂的课程和各种选课规定中选择最符合自己需求的课程,成为了很多学生的困扰。通过推荐系统,可以有效的客服这种问题。同时,随着互联网技术的发展,尤其在本次疫情期间,在线教学成为了当前流行的一种学习方式,在互联网的海量学习资源中找到最适合自己的课程,费时又费力。本项目希望能够设计一种就不同用户需求提供线下选课建议和相应的线上课程的推荐系统,解决学生的需要。
1.2 项目目标
本项目的设计目标可以分为三个方面:
- 系统能为学生提供便捷的学分管理,通过获取学生培养方案中各类型课程的学分需求,并允许学生个性化各学期修读学分并提供相应的建议。
- 系统能为学生提供选课推荐的服务,根据不同学生对老师授课方式的偏好、考核方式的偏好、不同课程的偏好和分数偏好推荐选课,为学生在选课时提供选择。
- 系统能为学生提供线上课程的推荐服务,针对不同学生的兴趣、学习需要,提供适合他们的线上课程,以实现提高学习成绩、培养人才的效果。
具体而言,本项目旨在开发一个系统,方便学生用户管理课程、完成选课操作,同时为师生搭建一个沟通的平台,以便学生更好地利用资源学习、教师更好的改善教学方式。
1.3 参考资料
[1]朱丽,付海涛,冯宇轩,李恒,孙宇,艾洪福,裴欣彤.基于深度学习的在线教学推荐系统设计与研究[J].计算机产品与流通,2020(04):183+187.
[2]杨梅,迟锦贵,刘小平,钱立龙.课程推荐系统可行性分析报告[DB/OL]. 2020-04-08. https://wenku.baidu.com/view/39f1fd3eaff8941ea76e58fafab069dc512247ef.html?fr=search
[3]论坛需求分析[DB/OL]. 2020-04-09. https://wenku.baidu.com/view/e3b87c2950d380eb6294dd88d0d233d4b04e3f5c.html?fr=search
[4]李兴万. 软件需求分析报告模板(完整版)[DB/OL]. 2014-06-19. https://wenku.baidu.com/view/d784292d5acfa1c7ab00cc18.html?fr=search
[5]左旭诚.UI界面设计的需求分析方法[DB/OL]. 2020-04-28. https://libcon.bupt.edu.cn/https/77726476706e69737468656265737421e7f24f97327e6a51770c9ce29b5a2e/view/15d70e72c67da26925c52cc58bd63186bceb928f.html?fr=search
[6]刘青文. 基于协同过滤的推荐算法研究[D].中国科学技术大学,2013.
[7]刘畅. 基于知乎用户行为的理财产品推荐系统的设计与实现[D].西北大学,2019.
[8]曹一鸣. 基于协同过滤的个性化新闻推荐系统的研究与实现[D].北京邮电大学,2013.
[9]袁惠蓉.基于“MOOC”的信息检索课程辅助学习系统的研究——以海南大学为例[J].信息技术与信息化,2018(12):158-160.
[10]张欢,邹冲.高校选课系统的课程推荐机制研究[J].电子世界,2018(20):91-92.
[11]巩晓悦. 基于个性化推荐的在线学习系统研究与实现[D].北京邮电大学,2019.
[12]康梅娟.基于SSM的摄影爱好者论坛的设计[J].科技资讯,2019,17(31):6-7.
2. 需求分析
2.1 功能需求分析
2.1.1.学分管理子系统
(1)用户可以设定各类课程需要修读的学分和已修读的学分;
(2)用户可以设定希望各个学期修读的学分数,同时也提供建议修读的学分数;
(3)管理员可以添加课程和相关资料。
2.1.2.选课推荐子系统
(1)通过推荐算法向用户推荐选课;
(2)向用户展示各个课程的相关信息,如往年分数分布、老师简介、课程构成等;
(3)提供线上的师生沟通平台,方便学生了解课程的详细信息。
2.1.3.线上课程推荐子系统
(1)通过推荐算法向用户推荐线上课程;
(2)允许用户检索感兴趣的内容,并根据排序算法向用户展示多个网站的课程检索结果。
2.1.4.系统功能
(1)登录管理:能够对用户的学号、密码进行简单的认证,能够区别学生用户和老师用户;首次登陆需要修改密码并且设置密保问题;
(2)课程评价管理:只有选修过课程的学生用户能够对课程进行评价,允许匿名评价;
(3)讨论区管理:只有未选修过课程的学生用户和任课老师能够发表和回复讨论区,并且对讨论帖子的字数有限制;允许课程的任课老师对课程的讨论区中的帖子进行管理,允许删除帖子;
(4)公告管理:只有任课老师和管理员(辅导员)有该权限,可以添加和删除课程的公告;
(5)课程管理:只有管理员有该权限,管理员可以添加、删除课程,也可以修改课程的资料,如任课教师、课程名称、课程类别等;
(6)用户管理:只有管理员有该权限,可以禁用、启用用户、进行密码重置。
2.2 性能需求分析
2.2.1.精度需求
(1)在执行数据增加时,不允许因为程序的原因导致增加数据失败,也不允许增加重复数据;
(2)执行数据删除操作时,不允许因为程序的原因发生多删除数据、删除数据失败的情况;
(3)数据的修改也要求保持相应的准确性;
(4)不允许因为服务器设置未完成导致的系统错误。
2.2.2.时间性能需求
(1)系统运行不响应时间不能超过10s;
(2)对系统进行操作时,响应时间应在5s之内;
(3)对用户操作时,时间要求如上;
(4)系统应实现24h*7的不间断运行。
2.2.3.故障处理需求
(1)在用户输入不合理数据时,能够进行一些合理的提示,不能因为输入错误而导致系统的错误或者程序停止运行;
(2)系统运行时,能够对服务器或网络通信的故障进行识别并进行提示,当故障排除后,系统能够恢复正常运行;
(3)数据库应该设有备份机制,防止数据丢失。
2.3 运行环境和系统接口需求分析
2.3.1.软件环境需求
(1)客户端:Chrome、Firefox、IE浏览器等。
(2)服务器端:Windows7及以上,Tomcat6.0,JDK1.5及以上,IE6.0及以上版本。
(3)数据库:采用大数据处理平台Hadoop的分布式文件系统HDFS;
(4)网络架构:支持TCP/IP协议;
(5)开发工具或技术体系:为了保证系统的上下兼容性,开发者应使用比较通用的开发工具的较新版本进行开发。
2.3.2.硬件环境需求
(1)服务器CPU:PIII 500以上,内存512M以上。
(2)客户机CPU:P200MMX以上,内存64M以上。
2.4 用户特性分析
2.4.1.学生用户:
(1)在选课时间附近,会产生较大的访问量,估计高峰时段每小时1k~2k;
(2)不同的学生用户具有不同的偏好,根据用户自定义和历史选课行为进行确定。
2.4.2.教师用户:
(1)在选课前会陆续登录,对课程信息进行完善、发布公告、在讨论区讨论,访问量可控,估计高峰时段每小时100~200;
(2)不同的教师用户具有不同的授课风格,根据教师自测和往年学生评价进行确定。
2.4.3.管理员用户:
(1)访问时间和访问量皆可控,估计高峰时段访问量在每小时 100以下。
面对不同的用户角色,界面元素和相应的功能模块有所不同,根据用户角色的不同,目标系统中的页面元素和组成都不同。允许用户根据自己想象中的理想系统向开发人员提出个性化需求,通过多次设计与要求的交互、设计更优秀的系统。
3. 系统设计
3.1 系统结构设计及子系统划分
学分管理与选课推荐系统总体结构图如图1所示。
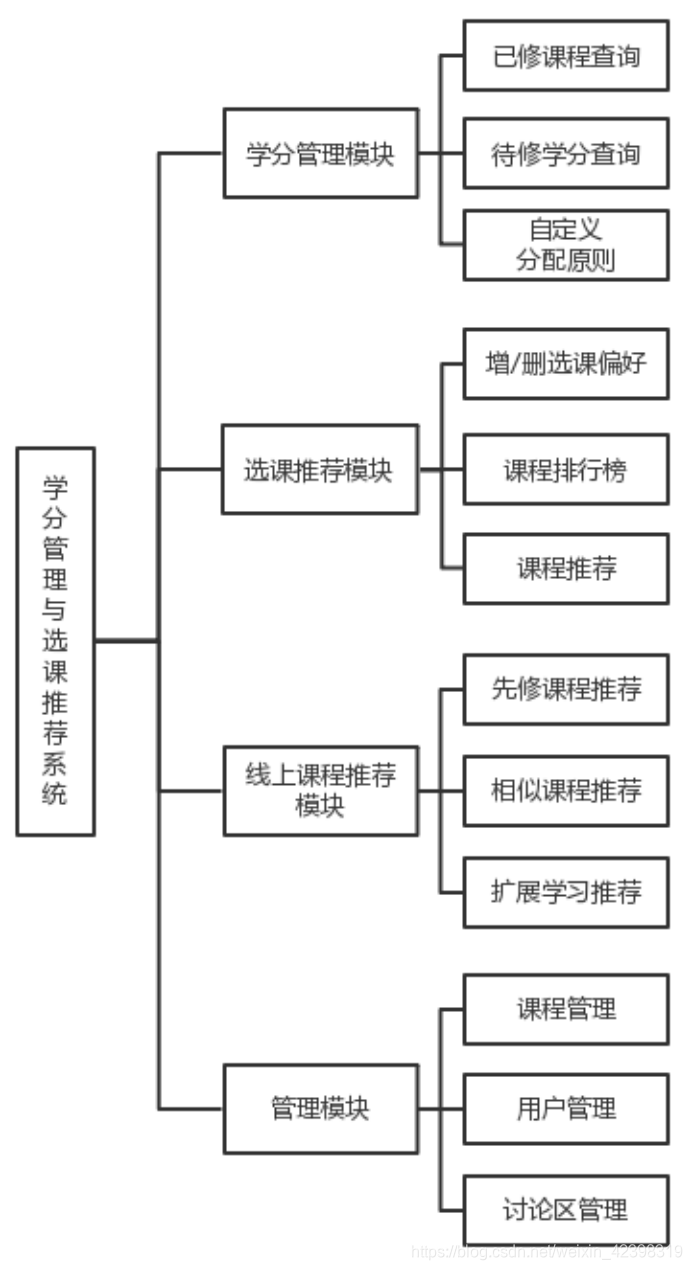
图1 学分管理与选课推荐系统的总体结构
通过图1可以看出,学分管理与选课推荐系统主要包括四个部分,即学分管理模块、选课推荐模块、线上课程推荐模块和管理模块;数据库中存储的用户相关信息、课程相关信息将展示至学生用户界面,系统通过推荐算法和排序算法实现选课和线上课程的推荐,便于用户选择喜欢的课程。系统的管理员用户和教师用户可以通过管理模块进行课程管理,包括增加、删除课程,修改课程的详细资料和用户的管理,如密码重置、增删、修改用户属性;教师用户可以通过管理模块管理课程和讨论区,如发布公告、删除帖子等。
3.1.2.系统流程图
(1)学生用户使用学分管理与选课推荐系统流程图如图2所示。
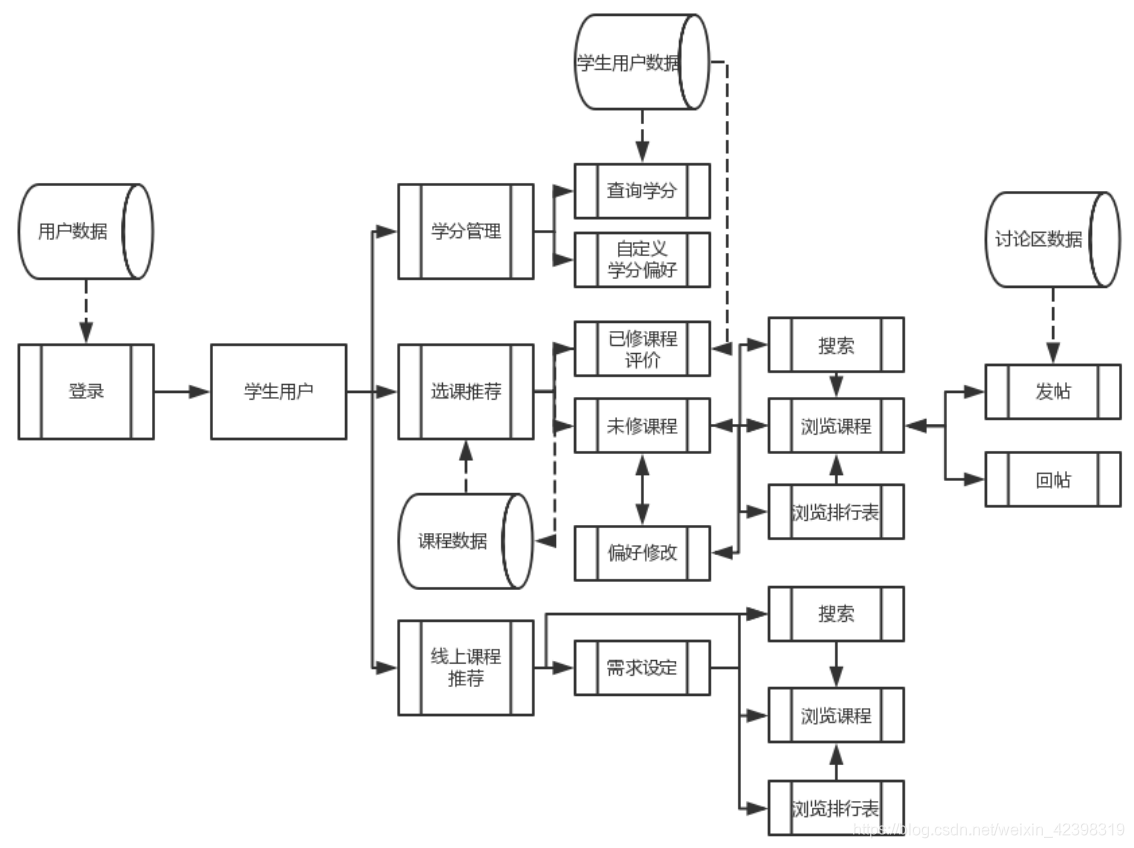
图2 学生用户使用学分管理与选课推荐系统的系统流程图
如图2,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









