







深度神经网络基础
监督学习和无监督学习
监督学习:数据有标签
- 回归问题
- 分类问题
无监督学习:数据无标签
欠拟合和过拟合
欠拟合解决方法:
- 增加特征项
- 构造更复杂的多项式
- 减少正则化参数
过拟合解决方法:
- 增大训练的数据量
- 正则化:L0正则、L1正则、L2正则
- Dropout方法:随机选取和丢弃指定层次之间的部分神经元连接
后向传播
损失和优化
损失函数:
- 均方误差函数: M S E = 1 N ∑ i = 1 N ( y t u r e i − y p e r d i ) 2 {\rm{MSE = }}{{\rm{1}} \over {\rm{N}}}{\sum\limits_{i = 1}^N {(y_{ture}^i - y_{perd}^i)} ^2} MSE=N1i=1∑N(yturei−yperdi)2
- 均方根误差函数: R M S E = 1 N ∑ i = 1 N ( y t u r e i − y p e r d i ) 2 {\rm{RMSE = }}\sqrt {{{\rm{1}} \over {\rm{N}}}{{\sum\limits_{i = 1}^N {(y_{ture}^i - y_{perd}^i)} }^2}} RMSE=N1i=1∑N(yturei−yperdi)2
- 平均绝对误差函数: M A E = 1 N ∑ i = 1 N ∣ y t u r e i − y p e r d i ∣ {\rm{MAE = }}{{\rm{1}} \over {\rm{N}}}\sum\limits_{i = 1}^N {\left| {y_{ture}^i - y_{perd}^i} \right|} MAE=N1i=1∑N∣∣yturei−yperdi∣∣
优化函数:
- 梯度下降
- 批量梯度下降
- 随机梯度下降
- Adam
激活函数
Sigmoid:
f
(
x
)
=
1
1
+
e
−
x
f(x) = {1 \over {1 + {e^{ - x}}}}
f(x)=1+e−x1
tanh:
f
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
f(x) = {{{e^x} - {e^{ - x}}} \over {{e^x} + {e^{ - x}}}}
f(x)=ex+e−xex−e−x
ReLU:
f
(
x
)
=
m
a
x
(
0
,
x
)
f(x) = max(0,x)
f(x)=max(0,x)
卷积神经网络
基础
- 卷积层:对输入的数据进行特征提取
- 池化层:对数据进行提取和压缩(平均池化、最大池化)
- 全连接层:将输入图像在经过卷积和池化操作后提取的特征进行压缩,并根据压缩的特征完成模型的分类功能。
LeNet模型
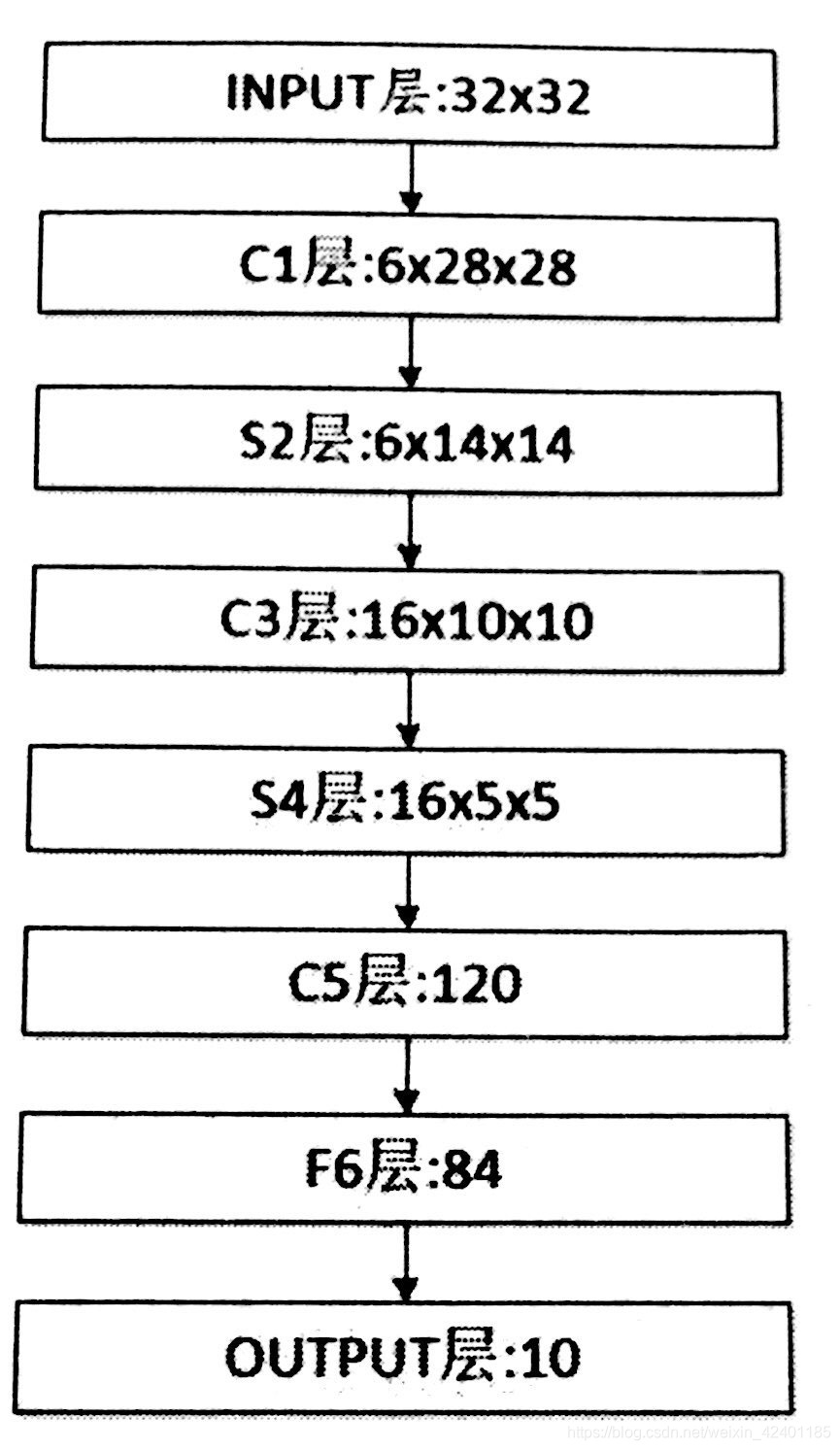
- INPUT层:32 * 32 * 1(高宽均为32的单通道图像)
- C1层:第一个卷积层,卷积窗口为5 * 5 * 1,步长为1,不使用Padding。则输出图像为28 * 28 ,进行6次操作,得到28 *28 *6的图像
- S2层:下采样层,缩减输入的特征图的大小,这里使用最大池化层(2 * 2 * 6)来进行下采样,则输出图像大小为14 * 14 * 6。
- C3层:第二个卷积层,卷积窗口为5 * 5 * 6,,步长为1,不使用Padding。卷积16次,则输出图像为10 * 10 * 16
- S4层:下采样,最大池化层,窗口为2 * 2 * 16,则输出图像为5 * 5 * 16。
- C5层:第三个卷积层:窗口为5 * 5 * 16。步长为1,不使用Padding。卷积120次,则输出图像为1 * 1 * 120。
- F6层:第一个全连接层:输入为1 * 1 * 120,输出为深度为84的特征图。则乘以120 * 84的权重参数,根据矩阵的乘法法则,得到输出。
- OUTPUT层:输出层,将1 * 84压缩成1 * 10,需要用到84 * 10的矩阵。将最终的10个数据全部输入Softmax激活函数中,得到最终结果。
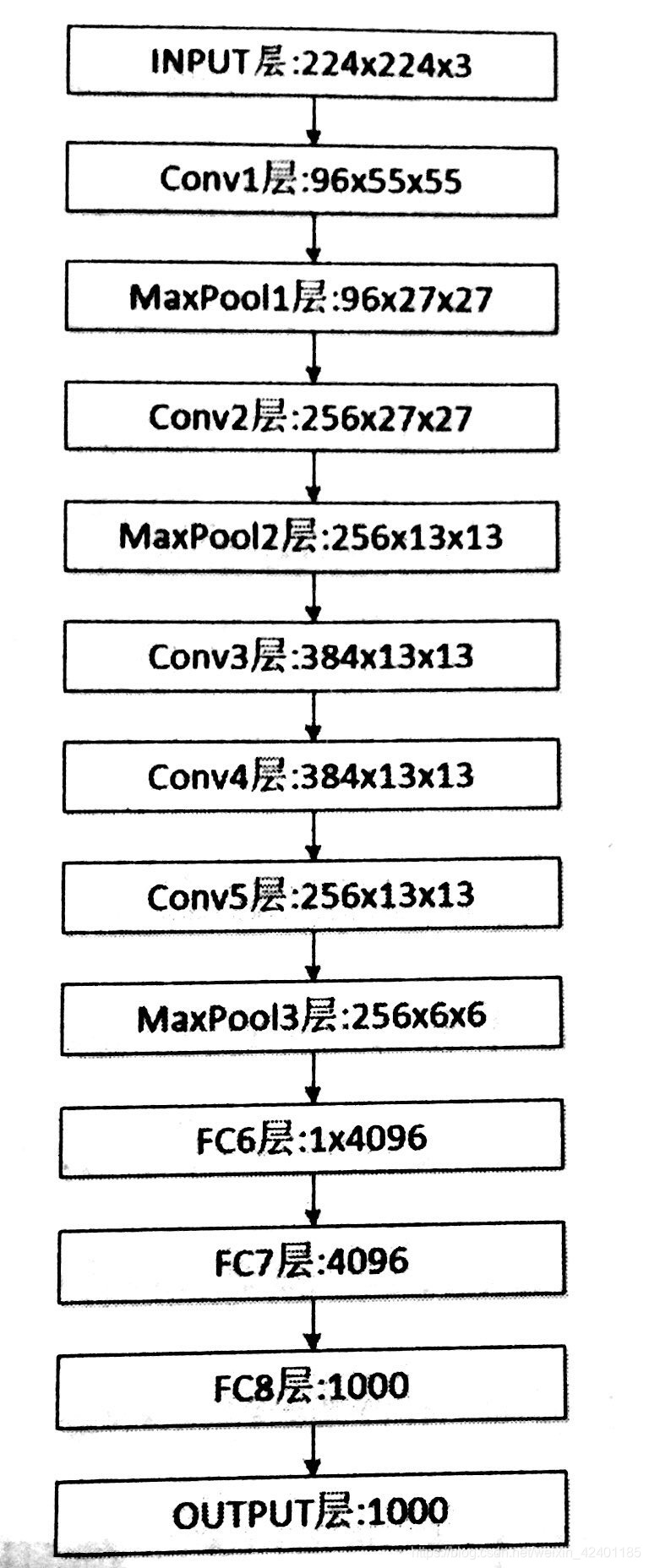
AlexNet模型
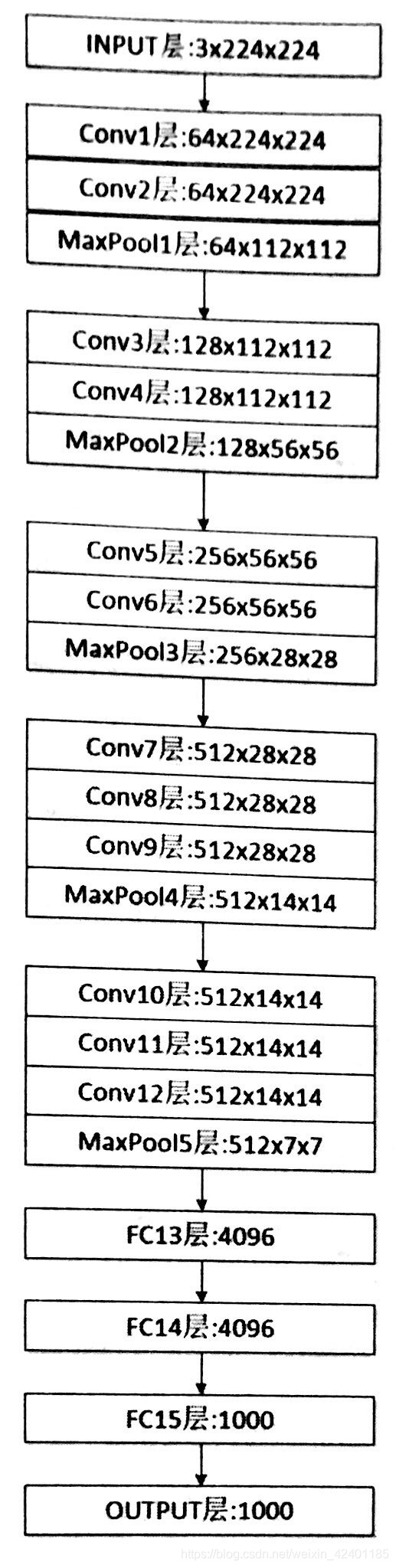
VGGNet模型
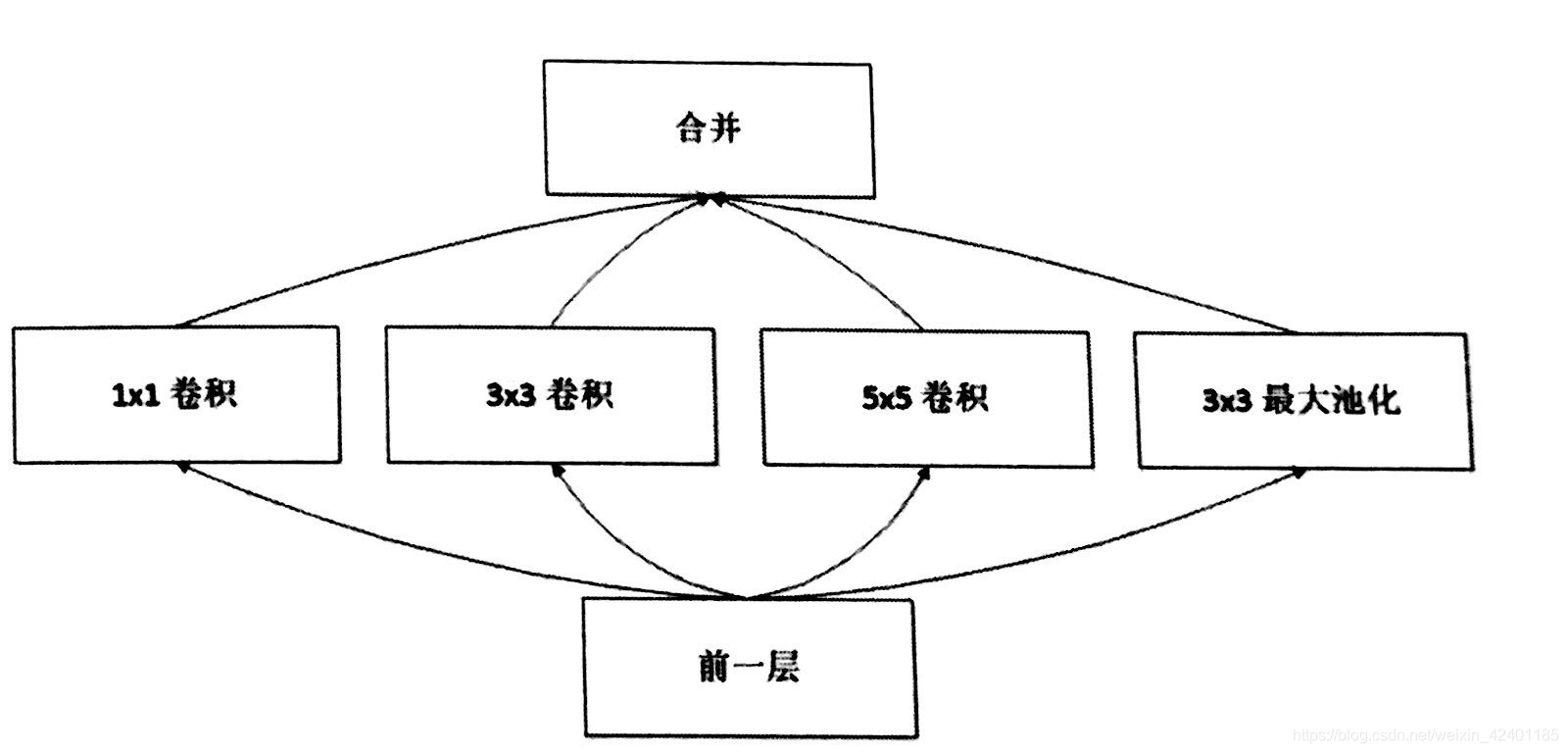
GoogleNet
Inception单元:















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











