







吴恩达机器学习第一次作业
(一)Linear regression with one variable
(1)Plot the data
addpath('你电脑上的数据文件路径')
data = load('ex1data1.txt')
X = data(:,1);
Y = data(:,2);
plot(X,Y,'rx','MarkerSize',10);
(2)costFunction
function J = costFunction(X,y,theta)
m = length(y);
J = sum(((theta*X)-y).^2)/(2*m);
(3)Computing the cost J(θ)
m = length(y)
X = [ones(m,1),X]
theta =zeros(2,1);
J = costFunction(X,y,theta) %回车我们可以得到J= 32.073
(4)Gradient Descent
alpha = 0.01;
iterations = 1500;
%梯度下降函数为
function [theta,J_history] = gradientDescent(X,y,theta,alpha,num_iers)
m = length(y)
J_history = zeros(m,1);
for i=1:num_iers
theta = theta-(alpha/m)*X'*(X*theta-y);
J_history(i) = costFunction(X,y,theta);
end
end
%执行梯度下降函数
[theta,J_history] = gradientDescent(X,Y,theta,alpha,num_itera);
%得到theta为[ -3.6303;1.1664],求得theta之后,我们就可以绘制出假设函数
plot(data(:,1),X*theta,'-');
predict1 = [1,3.5]*theta;
%predict1 = 0.45198
predict2 = [1,7]*theta;
(二) Linear regression with multiple variables
(1)Feature Scaling
data = load('ex1data2.txt')
X = [data(:,1),data(:,2)]
y = [data(:,3)]
%featureScaling的函数如下
unction [X_norm,mu,sigma] = featureScaling(X,y)
X_norm = X;
mu = zeros(1,size(X,2))
sigma = zeros(1,size(X,2))
mu = mean(X_norm)
sigma = std(X_norm)
X_norm(:,1) = (X_norm(:,1)-mu(1))./sigma(1);
X_norm(:,2) = (X_norm(:,2)-mu(2))./sigma(2);
end
%调用featureSacling函数
[X_norm,mu,sigma] = featureScaling(X,y)
X = [ones(size(y),1),X_norm]
theta = zeros(3,1)
alpha = 0.01
iterations = 400
(2)Cost Function
function J = costFunctionOfMulti(X,y,theta)
m = length(y);
J = sum((X*theta-y).^2)/(2*m)
%也可以写成J = (X*theta-y)'*(X*theta-y)/(2*m);
(3)Gradient Descent
function [theta,J_history] = GradientDescentOfMulti(X,y,theta,alpha,iterations)
m = length(y)
J_history = zeros(m,1)
for i= 1:iterations
theta = theta - (alpha/m)*X'*(X*theta-y)
J_history(i) = costFunctionOfMulti(X,y,theta)
end
end
% 调用GradientDescentOfMulti函数,其实单变量和多变量的代价函数和梯度下降
%可以相同
[theta,J_history] = GradientDescentOfMulti(X,y,theta,alpha,iterations)
%得到theta为
theta =
334302.06399
100087.11601
3673.54845
(4)绘制迭代次数和代价之间的关系图
plot(1:numel(J_history),J_history,'-b','LineWidth',2);
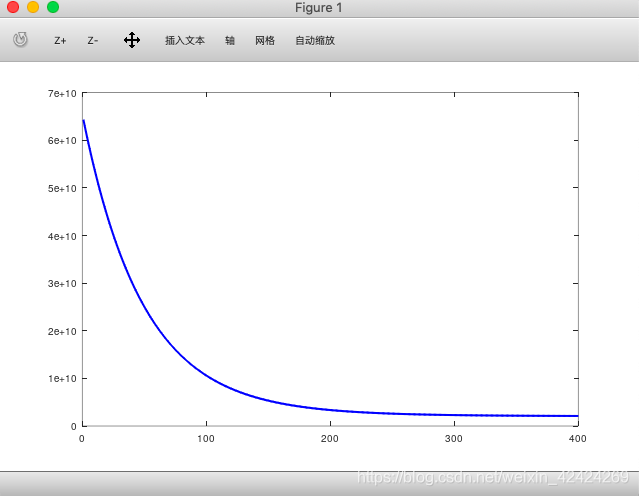
%改变alpha的值,重新调用梯度下降函数,重新绘制图像
alpha = 0.1
[theta,J_history] = GradientDescentOfMulti(X,y,theta,alpha,iterations)
plot(1:numel(J_history),J_history,'-b','LineWidth',2);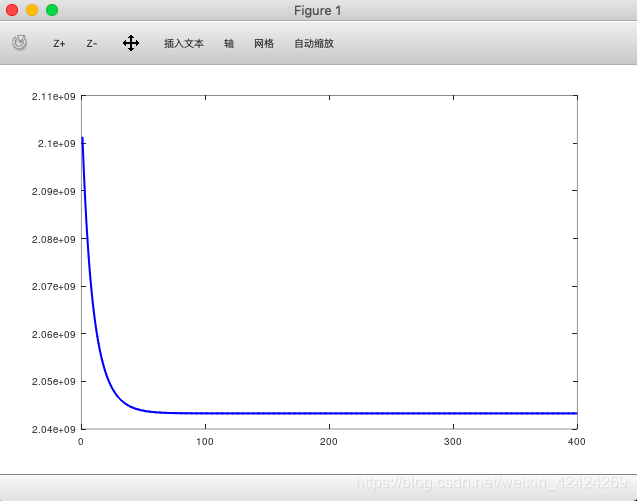
%我们可以看到当alpha变小时,函数收敛的速度变小。我们知道alpha代表的是学习效率
%如果我们把梯度下降的过程比作是下山的话,那么alpha就代表着我们迈步子的大小
(三)Normal Equation
(1)一次性求解theta的值
function [theta] = normalEqn(X, y)
theta = zeros(size(X, 2), 1);
theta = pinv(X'*X)*(X'*y);
end















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









