






r语言包查找的步骤
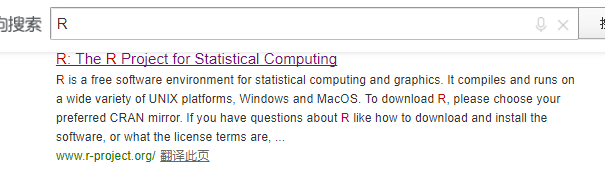
选择download下的CRAN

随便选择一个网址进去(没差)

点击目录下的packages
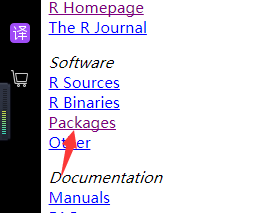
接下来还是随便选,这里是包的排列方式,比如按发布时间,或者字母排列方式(方便)

查找相应的包,打开pdf,就可以学习方法应用啦
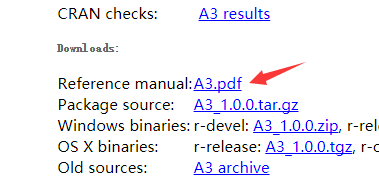
这里演示forecast包的方法使用
Forecast包:时间序列和线性模型的预测函数
(1):seasonplot()

Description: PlotsaseasonalplotasdescribedinHyndmanandAthanasopoulos(2014,chapter2). Thisislikea time plot except that the data are plotted against the seasons in separate years.绘制一个季节图,像一个时间图,除了数据是根据不同年份的季节绘制的。用法:
seasonplot(x, s, season.labels = NULL, year.labels = FALSE,
year.labels.left = FALSE, type = "o", main, xlab = NULL,
ylab = "", col = 1, labelgap = 0.1, ...)
参数:
x ts类的数值向量或时间序列
Season.labels “一年”中每个季节的标签year.labels 逻辑模糊指示数据的最大值应该在右边。year.labels.left 逻辑模糊指示数据的最大值应该在左边。Type 绘图类型(关于绘图)。ggseasonplot尚不支持。col 颜色
Continuous 多年的配色方案应该是连续,离散Polar 在季节坐标上绘制图表Labelgap 年份标签和绘制线之间的距离Xlab x轴标签
Ylab y轴标签
Examples
seasonplot(AirPassengers, col=rainbow(12), year.labels=TRUE)
代码学习:
par(mfrow=c(2,1))
library(forecast)
monthplot(AirPassengers, xlab="", ylab="")
seasonplot(AirPassengers, year.labels="True", main="")


第一幅图是月度图,表示的是每个月份组成的子序列(连接所有1月的点、连接所有2月的点,以此类推),以及每个子序列的平均值。
第二幅图是季节图,这幅图以年份为子序列。
(2)splinef三次样条预测

Description:使用三次平滑样条返回本地线性预测和预测间隔
用法:splinef(y, h = 10, level = c(80, 95), fan = FALSE, lambda = NULL,
biasadj = FALSE, method = c("gcv", "mle"), x = y
参数:
Y ts类的数值向量或时间序列
H 预测的周期数
Level 预测间隔的置信水平。
Fan 如果为真,级别设置为seq(51,99,by=3 )。这适用于风扇图。
Lambda 箱式柯克斯变换参数仪。如果λ= "自动",则使用BoxCox .λ自动选择转换。如果为空,则忽略转换。否则,在估计模型之前转换数据。
Biasadj 对Box-Cox变换使用调整后的反向变换平均值。如果转换后的数据用于生成预测和修正值,则定期的反向转换将会产生媒体信息。如果偏差为真,将进行调整以产生平均预测和修正值。
Method 选择平滑参数的方法。如果方法为gcv,则使用光滑样条的广义交叉验证方法。如果方法="mle ",则使用Hyndman等人( 2002 )的最大似然方法。
代码实例:
library(forecast)
fcast <- splinef(uspop,h=5)
dev.new()
plot(fcast)
summary(fcast)

Forecasts:
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
1980 225.6523 219.6912 231.6133 216.5356 234.7689
1990 248.1045 233.3293 262.8798 225.5077 270.7013
2000 270.5568 244.8162 296.2974 231.1900 309.9236
2010 293.0091 254.5045 331.5136 234.1214 351.8967
2020 315.4613 262.6160 368.3067 234.6413 396.2814
Plotrix:绘图功能
许多图,各种标签,轴和颜色缩放功能

Description
显示带有可选标签的3D饼图
Usage
pie3D(x,edges=NA,radius=1,height=0.1,theta=pi/6,start=0,border=par("fg"), col=NULL,labels=NULL,labelpos=NULL,labelcol=par("fg"),labelcex=1.5, sector.order=NULL,explode=0,shade=0.8,mar=c(4,4,4,4),pty="s",...)
参数:
x 每个值都是一个扇区的数值向量
edges 形成椭圆的行数
radius 以用户单位表示的饼图半径
height 以用户单位表示的饼图高度
theta 以弧度表示的视角
start 开始绘制扇区的角度
border 扇形边界线的颜色
col 扇区的颜色
labels 每个扇区的可选标签
labelpos 标签的可选位置
labelcol 标签标签的颜色
labelcex 标签的字符扩展因子
sector.order 允许操作员指定扇区的绘制顺序
explode 分解数量以用户单位“分解”饼图
… …
Value: 以弧度表示的扇形平分角。
# Get the library.
library("plotrix")
# Create data for the graph.
a <- c(21, 62, 10,53)
c<-paste(a,"%",sep="")
label=paste(c("70后", "80后", "90后", "00后"),c,sep='\n')
dev.new()
pie3D(a,labels = label,explode=0.1, main = "出生年龄段 - 饼状图")

Mapedata: 额外的地图数据库
地图包的补充,提供更大和/或更高分辨率的数据库

Description: 这个数据库产生了一张中国地图,包括各省的边界。
数据文件仅仅是指定环境名称的字符串的赋值
ment变量,包含地图绘制函数使用的二进制文件的基本位置。
Examples :map('china')
library(mapdata)
dev.new()
map("china", col = "red4", ylim = c(18, 54), panel.first = grid())
title(" 中国地图")
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









