







Abstract:ViT(Vision Transformer)在图像大模型领域取得了突破性的进展,然而高昂的计算代价与单一的尺度信息限制了其的推广。Swin Transformer则借鉴了卷积神经网络归纳配置,建立了层级式架构移动窗口的Transformer框架,极大地减少了计算代价并能够完成视觉中稠密预测的任务。Swin Transformer在图像分类(ImageNet-1K),目标检测(COCO)和实例分割(ADE20K)任务上均取得了SOTA的结果。
1. Problem and contributions
在图像处理中,传统的CNN因为具备了局部感受野与层级式的多尺度信息融合归纳配置,这样的强先验信息使得CNN在处理数据量较小的数据以及稠密预测任务(分割、检测等)取得较为优秀的结果。ViT文章通过实验指出:当数据量比较小时,这种局部感受野的归纳配置是有利的。但数据量足够大时,基于Transformer的全局上下文建模具有更强的表达能力。本文章的主要动机在于:把CNN的归纳配置融入Transformer中,提出一种通用性的骨架网络,从而能够处理图像任务中常见的数据缺乏且需要稠密预测情况。
针对上述问题,作者的主要贡献在于:(1)作者提出了一种基于层级式Transformer架构的通用性骨干网络,该架构能够建立稠密预测任务所必须的多尺度图像信息;(2)作者基于CNN所特有局部性归纳偏置建立了基于Shift Window机制的局部注意力机制,极大降低了Transformer的计算量,使得Transformer在视觉任务小数据集上也具有可训练性;(3)作者提出了一种基于MASK机制的通用性Shift Window计算机制,该计算机制具有计算高效性;(4) Swin Transformer在图像分类(ImageNet-1K),目标检测(COCO)和实例分割(ADE20K)任务上均取得了SOTA的结果,推动了视觉任务基线的提升。
2. Solution
2.1 Hierarchical Transformer
Swin Transformer-T的基本框架如图1(a)所示。举例输入图像为(224, 224, 3)时,经过Patch Partition模块将图像划分为基本尺寸为(4, 4)的token(Patch, like word in NLP),则原始图像可以表达为(56, 56, 48),随后在Linear Embedding模块通过C=96个1*1的卷积核对通道数进行拓展为(56, 56, 96),并作为核心模块Swin Transformer Block的输入。在Swin Transformer Block中图像尺寸不发生变化,即输出尺寸也为(56, 56, 96)。将该特征图输入到Patch Merging模块中,得到尺寸减半,通道数翻倍的特征图,即尺寸为(28, 28, 192)。重复上述流程,最后得到类似于传统卷积神经网络VGG或AlexNet的尺寸为(7, 7, 784)的输出。Patch Merging的作用与Pooling下采样相似,其基本过程的举例如图1(c)所示:对相邻的2×2的token进行下采样产生4个尺寸相同的token,并使用2个1*1的卷积进行通道缩减,最后实现类似于Pooling操作:尺寸减半、通道翻倍的结果,从而建立多尺度信息。
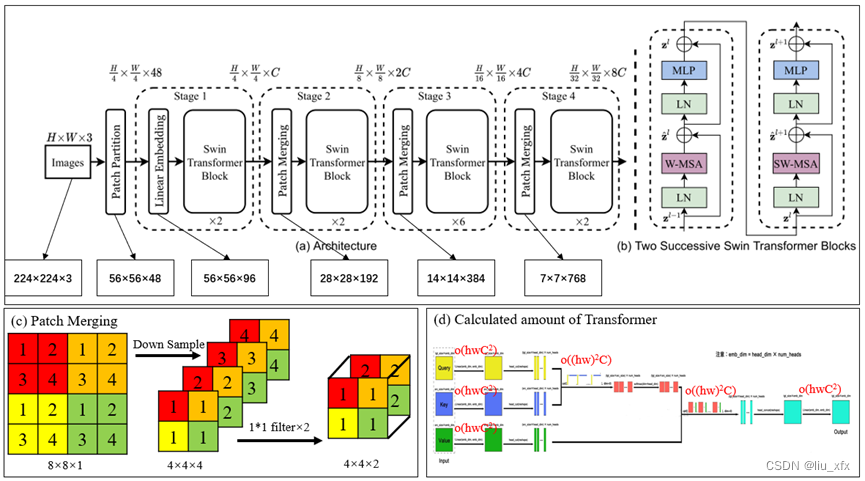
Figure 1 Swin Transformer的基本构架及多头注意力机制的计算复杂度
2.2 Local Transformer
Swin Transformer的局部注意力机制体现在其在核心模块Swin Transformer Block中仅计算不重叠窗口内所有M×M(default M=7)个Token之间的注意力。Swin Transformer Block如图1(b)所示,至少包括两个连续的多头注意力模块。局部的注意力机制能够极大地降低计算量,对于Token数目为h×w![]() 的图像,标准的多头注意力机制及其计算复杂度如图1(d)所示。总计算复杂度为:
的图像,标准的多头注意力机制及其计算复杂度如图1(d)所示。总计算复杂度为:
ΩMSA=4hwC2+2hw2C#1![]()
对于仅计算窗口内M×M(default M=7)个Token之间的局部计算注意力机制:
ΩW-MSA=hwM24M2C2+2M22C=4hwC2+2M2hwC#2![]()
可以看出,局部注意力机制使得计算复杂度从与图像尺寸二次方降低为线性关系。
2.3 Mask mechanism in Shift Window
窗口每次同时沿着横纵方向同时滑动,滑动过程如图2(a)所示,原来只有4个窗口的特征图在滑动后产生了9个窗口,若依然对每个窗口进行注意力机制的计算,这意味着计算量急剧上升,这是我们所不希望的。因此对图2(a)中的A,B,C部分进行移位,产生新的特征图依然只有4个窗口,但是直接在窗口内计算局部注意力机制显然是不合适的,因为A,B,C与原来窗口内的内容不具有直接的上下文关系。因此在文中引入了基于MASK的移位机制。为了更好的可视化,我们将图2(a)绘制为图2(b)形式。对图2(b)中的四个窗口进行多头注意力机制计算如图2(c)所示。显然区域1是可以直接进行注意力机制计算的,而其他区域的只有特定区域的注意机制计算结果是有效的,通过高亮颜色表示。对于无效区域,使用-100作为MASK值,并对结果做Softmax操作即可屏蔽无效区域带来的影响。
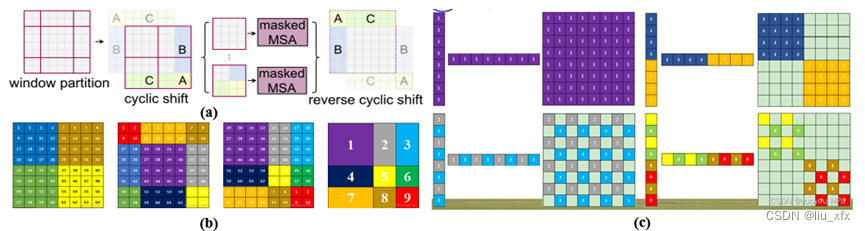
Figure 2 Shift Window带来的问题及MASK机制
3. My Own Understanding
作者提出了一种基于滑动窗口的多尺度融合注意力机制计算方法,这种方法可以作为计算机视觉任务的通用性骨干网络,在图像分类(ImageNet-1K),目标检测(COCO)和实例分割(ADE20K)任务上均取得了SOTA的结果,推动了视觉任务基线的提升。但是这种方法依然存在着CNN归纳配置所固有的问题,若需要建立全局的上下文信息,则要求网络具备足够的深度才能完成,而全局的Transformer可以通过一步直接建立,这意味着Swin Transformer丢失传统Transformer最大的优势。尤其是在NLP领域中上下文距离可能较大的情况,Swin Transformer的劣势将被进一步放大,这可以与作者所希望建立的视觉-语言大一统模型是违背的。如何把该方法高效地应用到NLP领域中,是众多研究者值得思考的问题。















 1702
1702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









