







第一部分:Transformer
一.Transformer的优缺点
Transformer虽然好,但它也不是万能地,还是存在着一些不足之处,接下来就来介绍一下它的优缺点:
优点:1.效果好
2.可以并行训练,速度快
3.很好地解决了长距离依赖的问题
缺点:
完全基于self-attention,对于词语位置之间的信息有一定的丢失,虽然加入了positional encoding来解决这个问题,但也还存在着可以优化的地方。
二. Self-attention(Scaled DotProduct Attention)
1.Fully-connected

因为从图中可以看到,第一个saw是动词,第二个saw是名词锯子的意思。我们如何做到同一个单词能够分别出不同的词性呢?
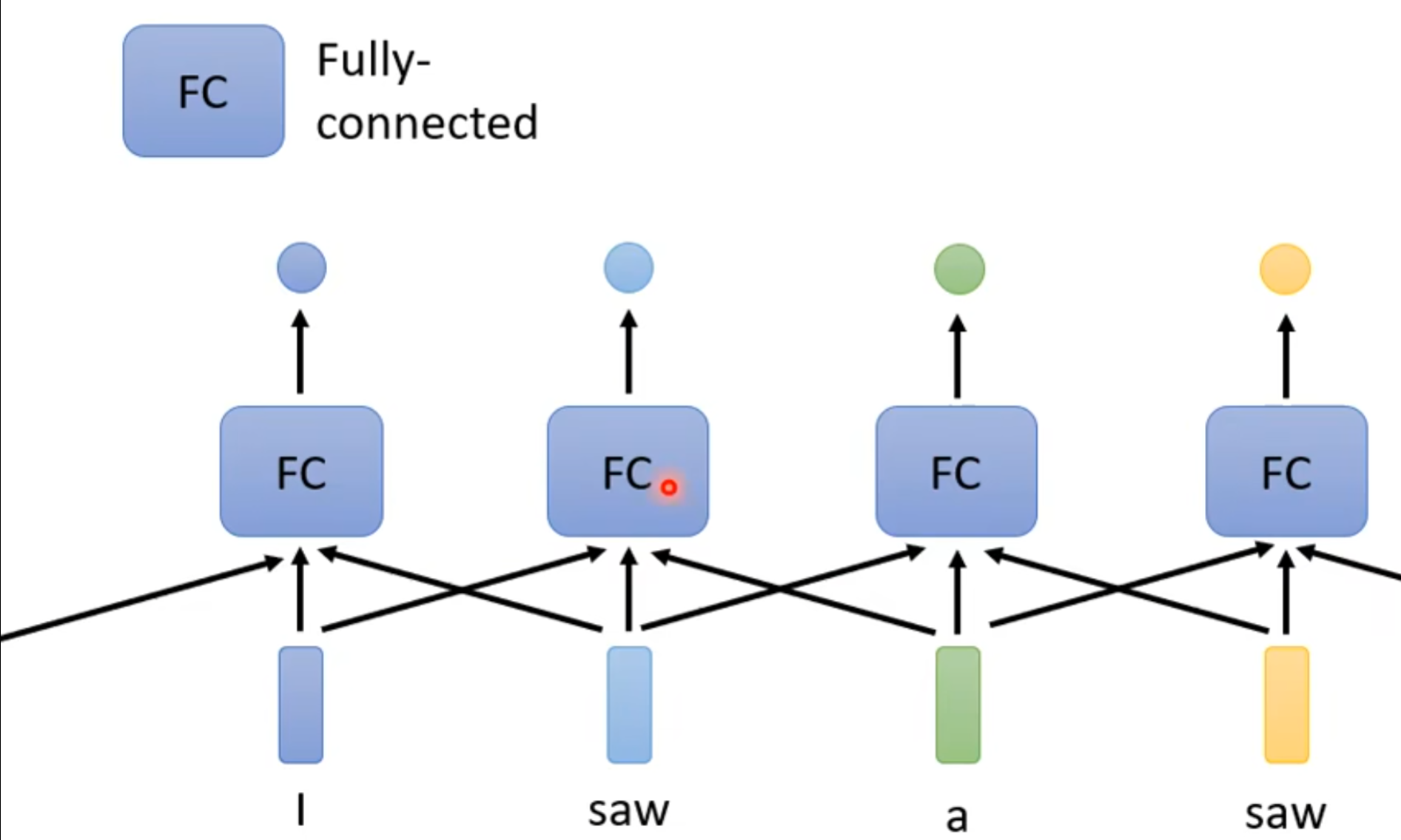
考虑多个及其相邻的向量,我们可以给Fully-connected network一整个windows去考虑上下文,相邻的向量的其他值。

疑点:假如sequences很长怎么办?
windows如果弄得很长的话需要改很多参数并且容易报错,于是我们提出了 Self-attention
2.Self-attention
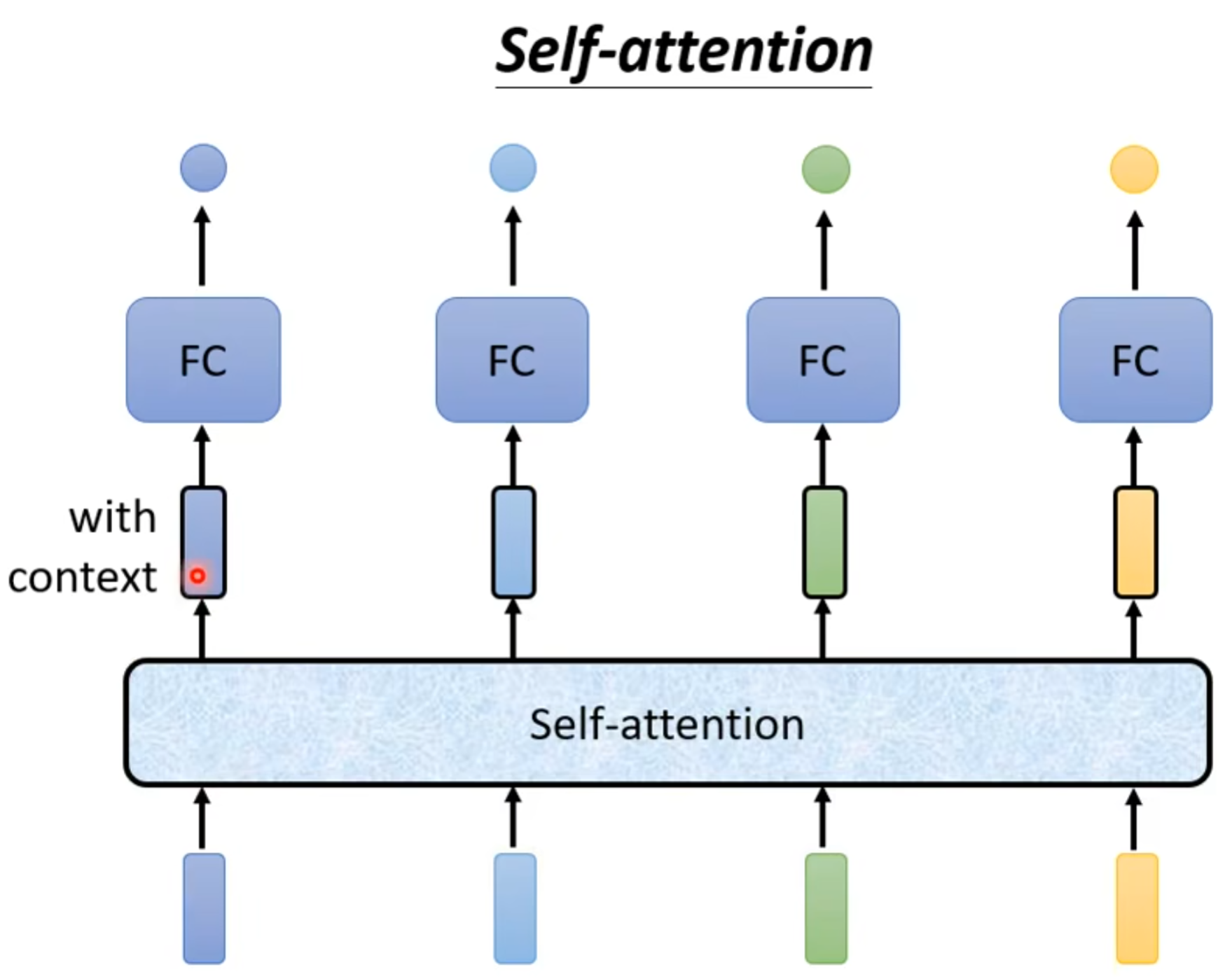
运作方式:self-attention维持一整个sequences的运行,你输入几个vector(矢量)就输出几个vector。这几个vector都是考虑到一整个sequences得到的咨询。再丢入FC得出它是属于什么类别等等。
特点:可以叠加交替运行
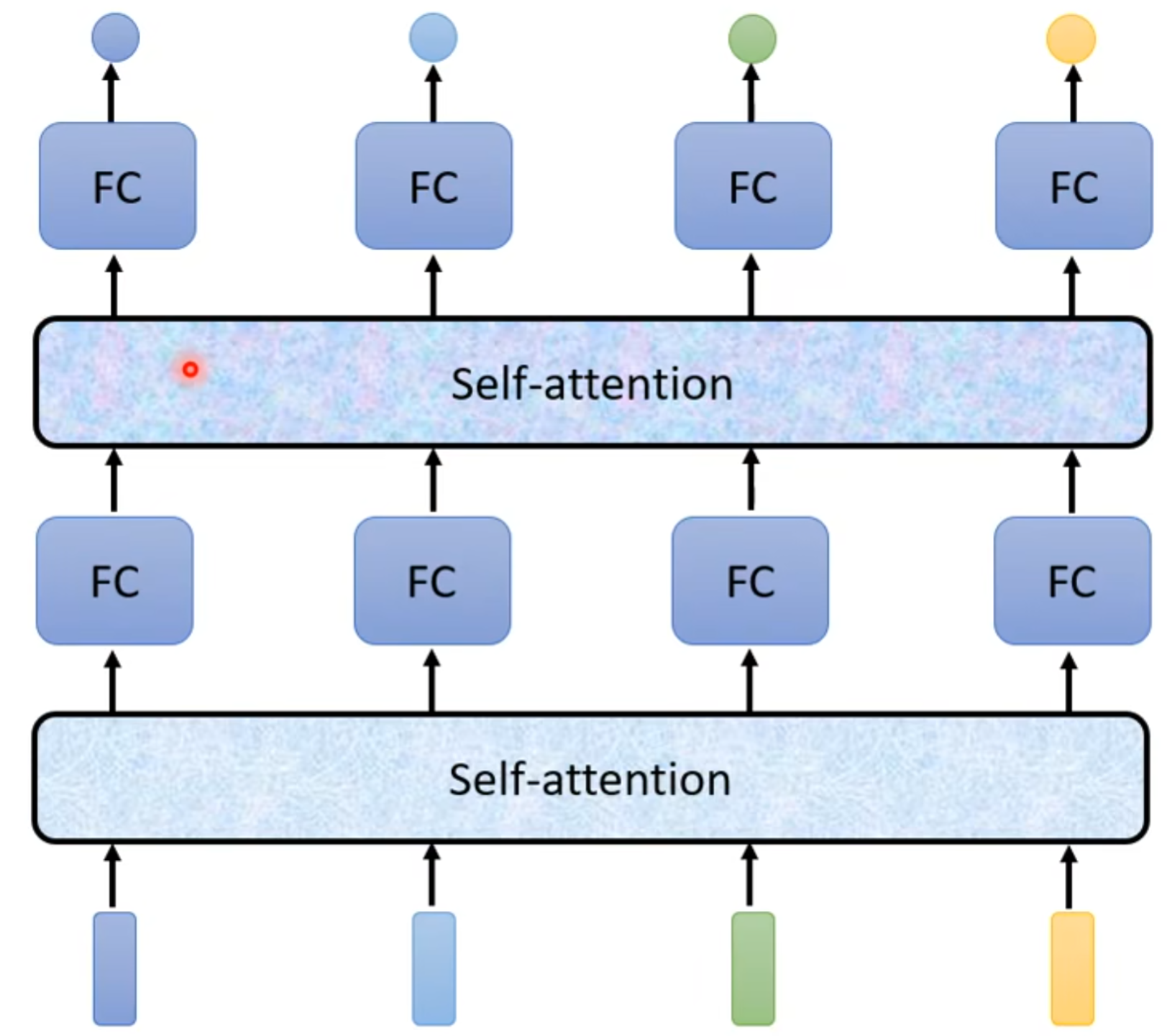
讲解完整运作方式:
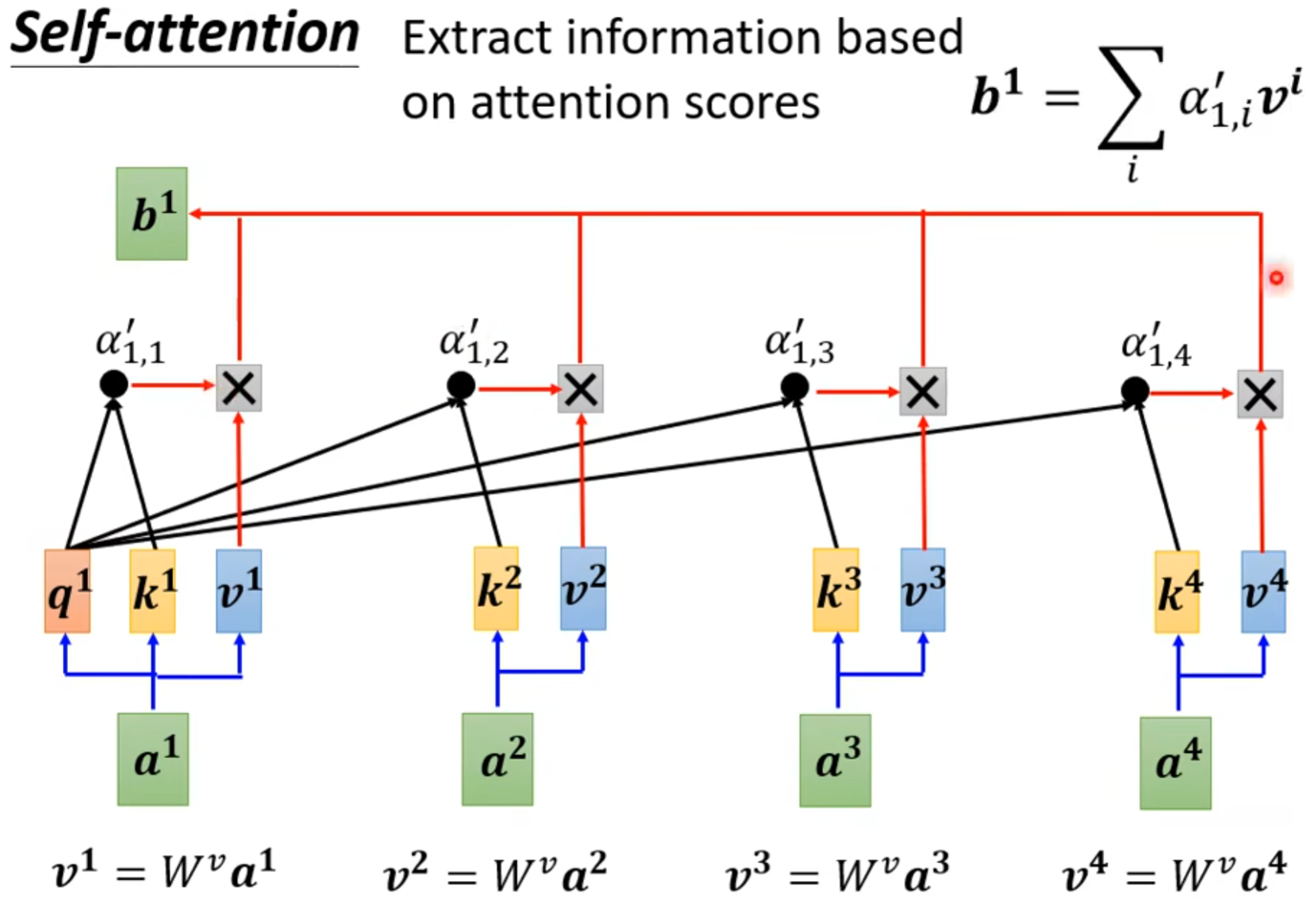
(1).每个b都考虑了所有a才生成出来的。
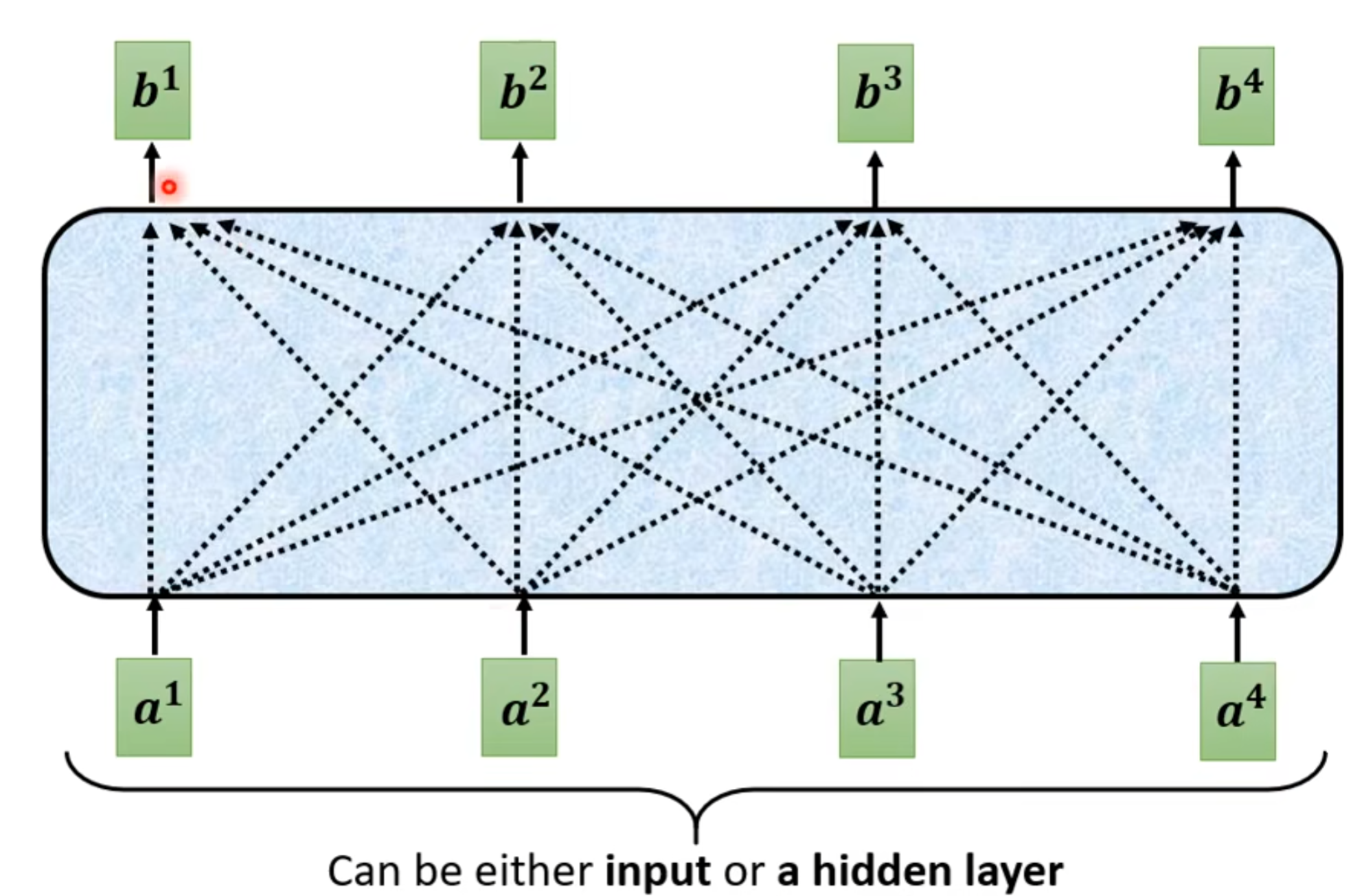
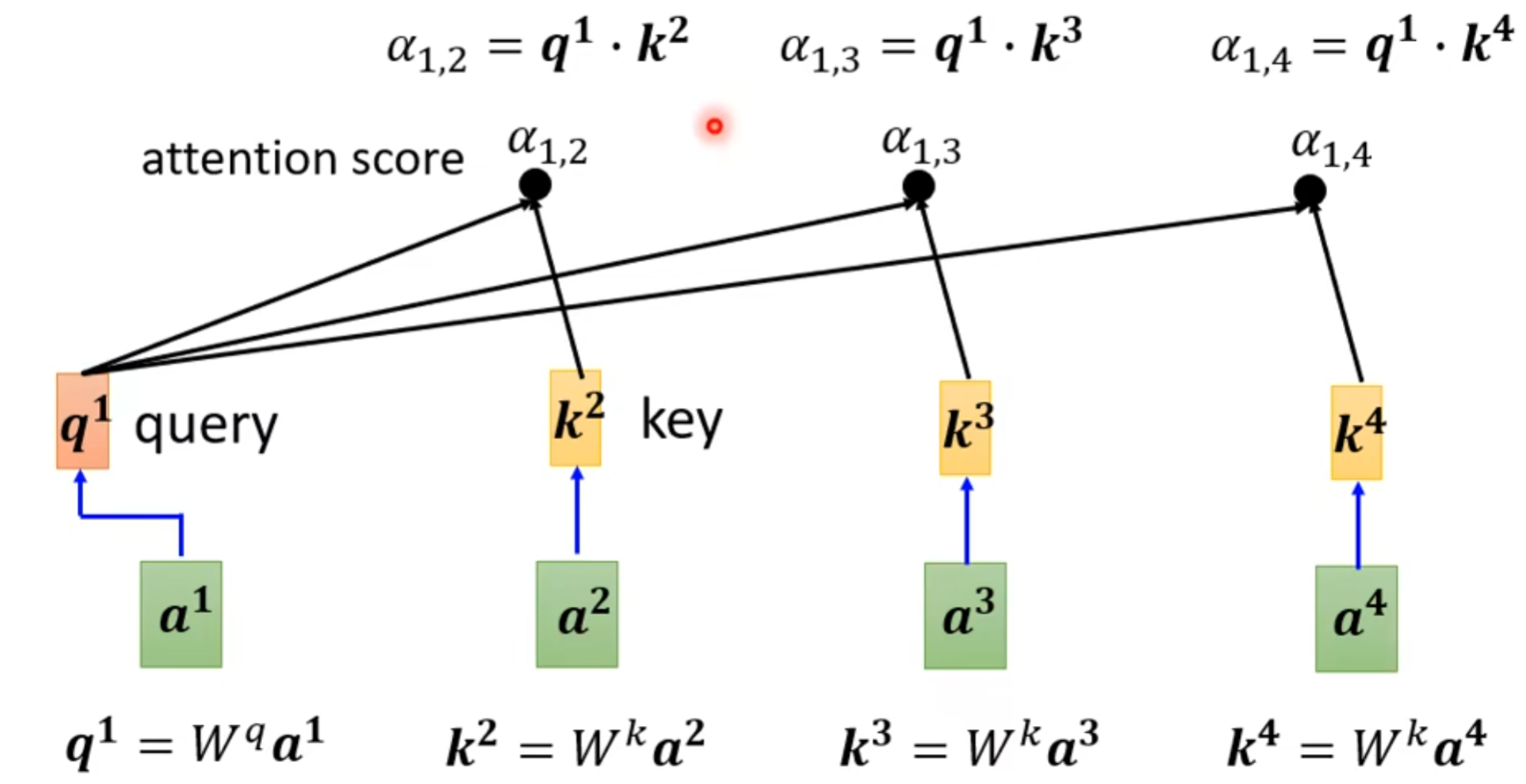
(2).怎么产生b1这个向量
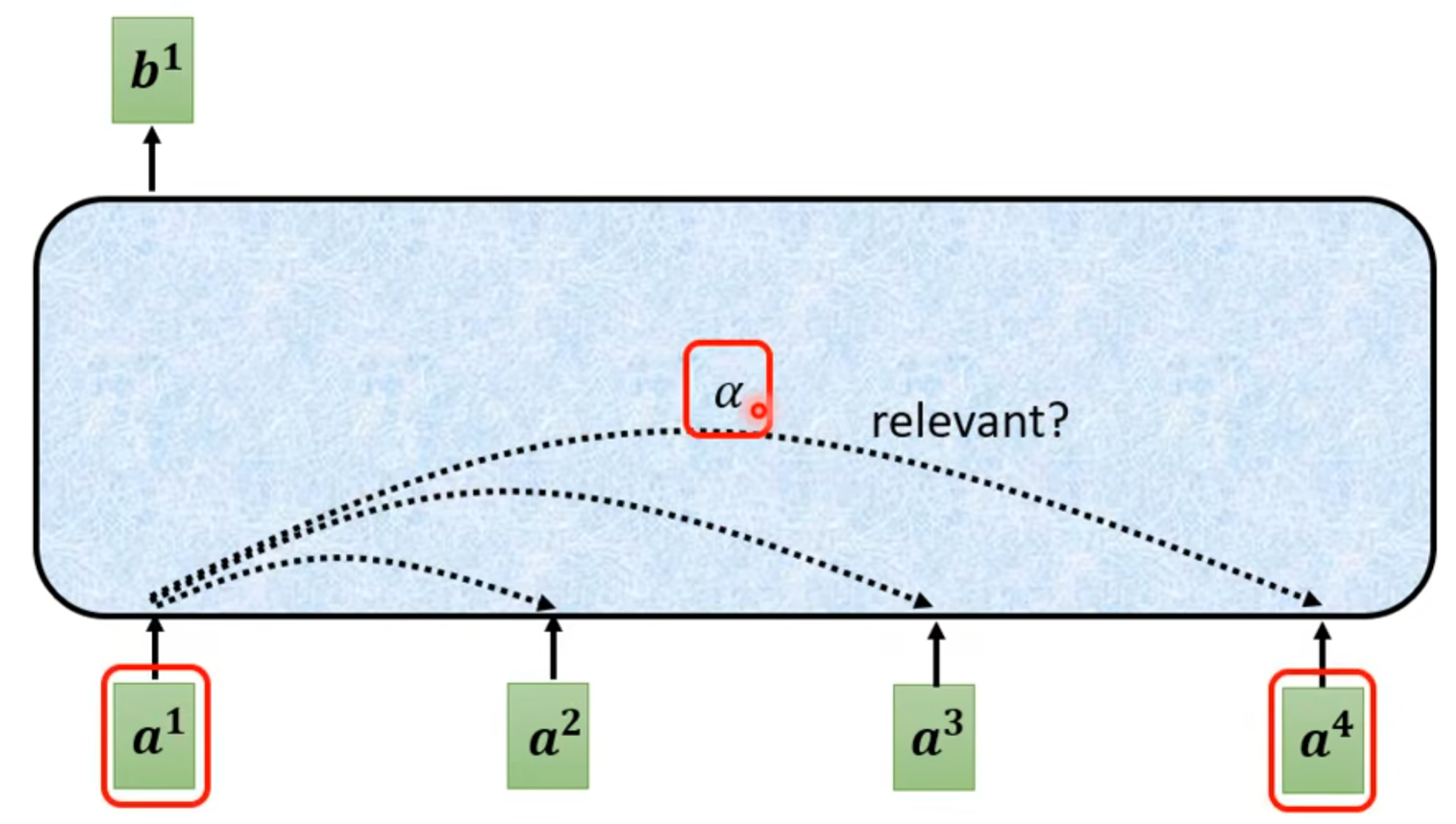
- 在这个sequences里面找出和a1相关的这个向量。跟a1相关的其他向量的重要程度和关联程度为
。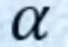
- 计算
的数值: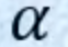
方法一: Dot-product
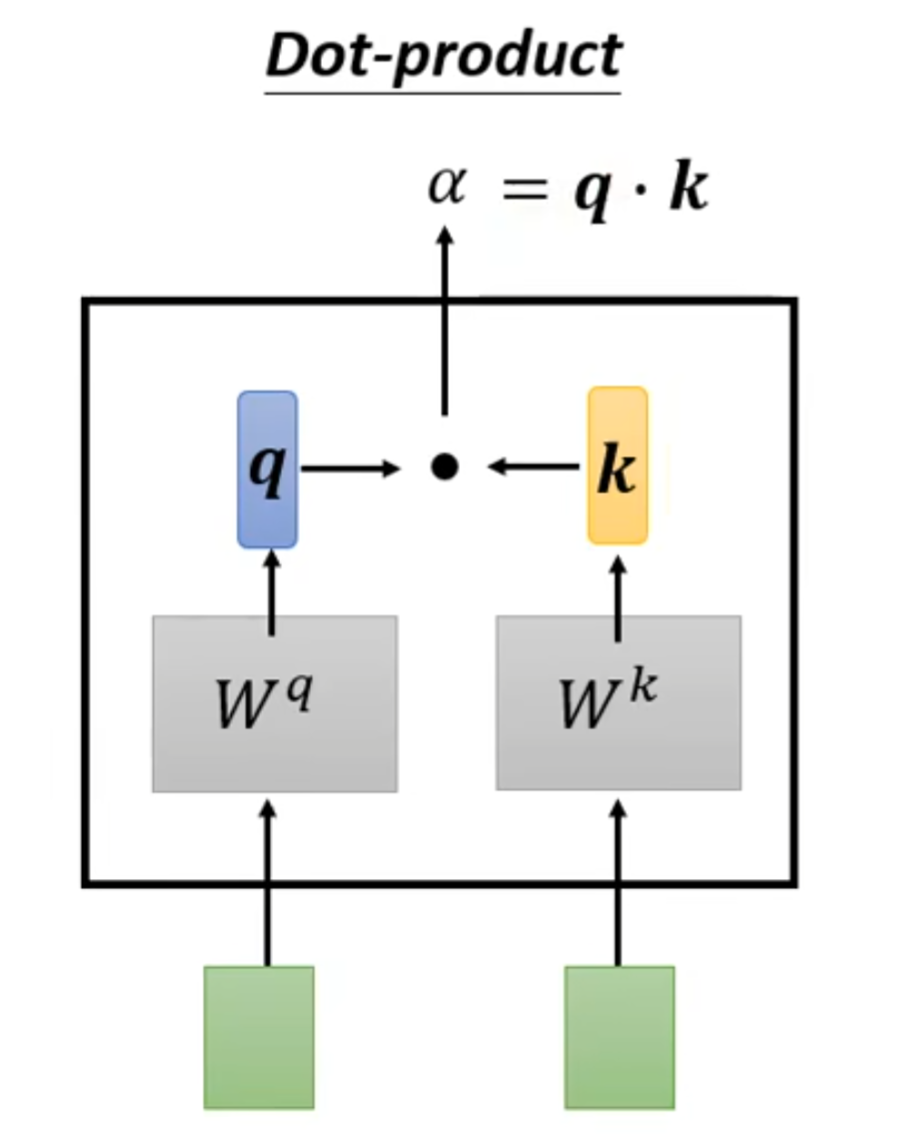
方法二: Additive
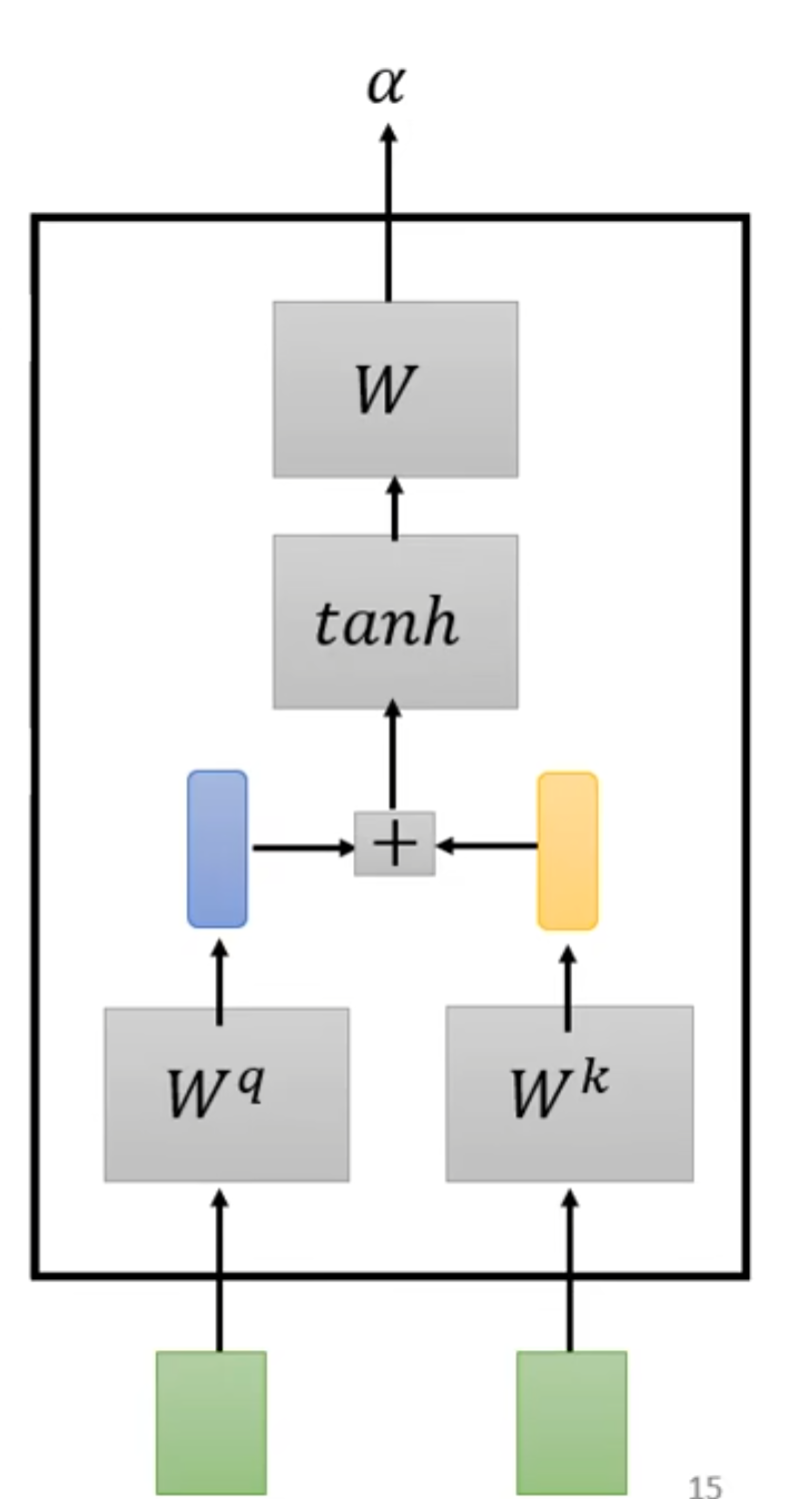
a1,2 等等就是a和其他的关联性,a1,1是自己和自己的关联性。
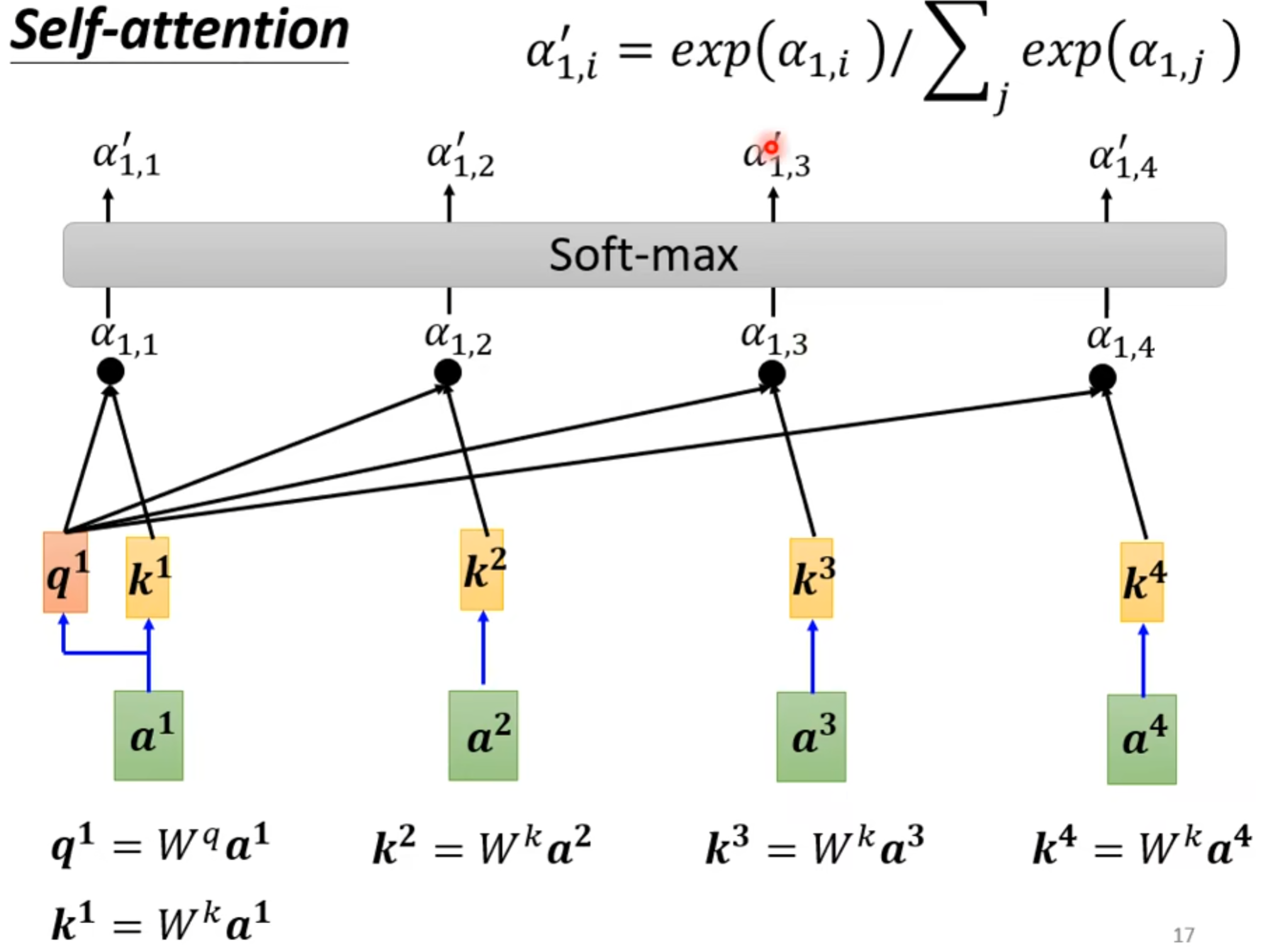
公式如下:
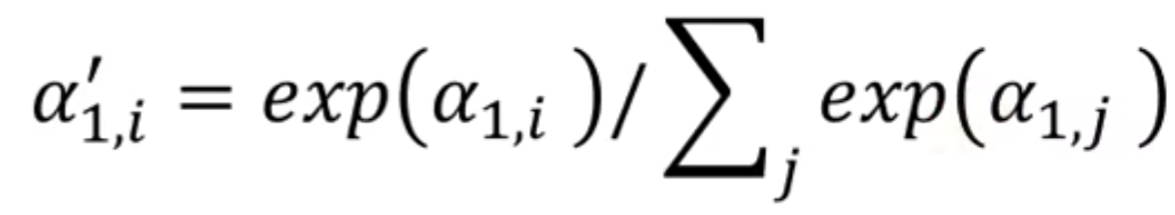
(3).怎么抽取重要的咨询
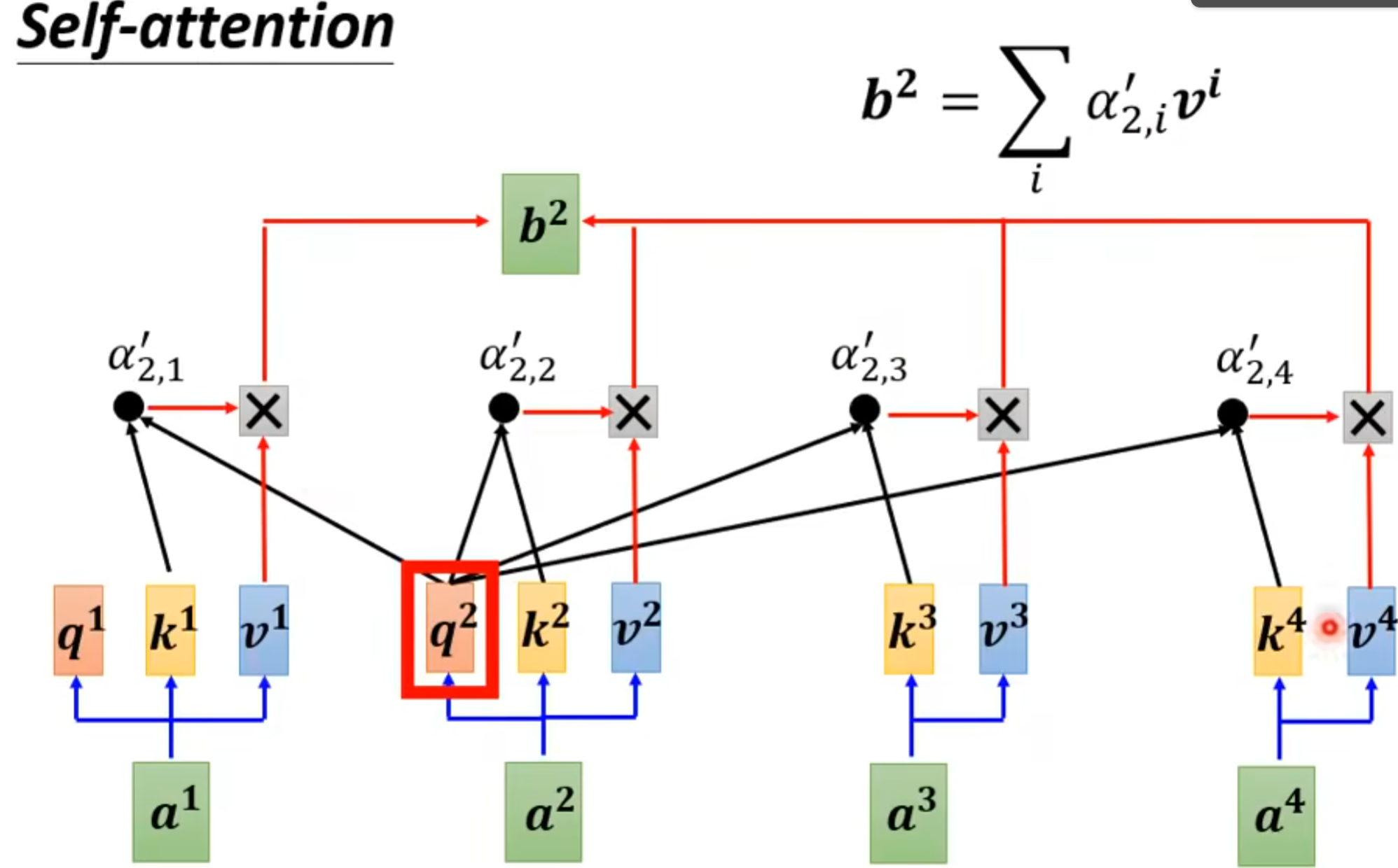
(3).怎么产生q k v矩阵
- q的产生
因为
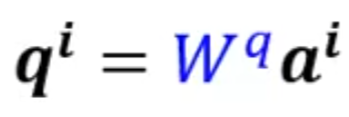
所以

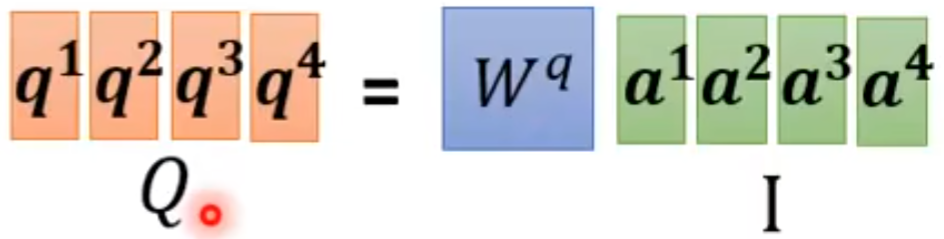
- k的产生
因为
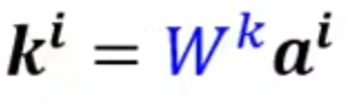
所以

- v的产生</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









