







1、试着说明一下Top-5 top-1 的区别early-stop点?
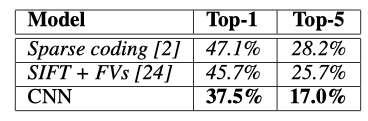
这里top-5和top-1指的是分类是否准确的一个阈值,比如大分类可以为车,而车则可以有自行车,轿车,公交车等等。top-5的阈值相对更大,因此错误率也更低。top-5错误率是指测试图像的正确标签不在模型认为的五个最可能的便签之中。
2、概括一下如何找到深度模型训练过程中的early-stop点神经网络处理图像分类?
基本含义是在训练中计算模型在验证集的表现,当模型在验证集上的表现开始下降的时候,停止训练,就能避免过拟合的问题。主要步骤如下:
1、将原始的训练数据集划分为训练集和验证集。
2、只在训练集是上进行训练,并每个周期计算模型在验证集上的误差,例如,每15次epoch
3、当模型在验证集上的误差比上一次训练结果差的时候停止训练
4、使用上一次迭代结果中的参数作为模型的最终参数
参考:https://blog.csdn.net/df19900725/article/details/82973049
3、简述Alexnet相较于Lenet性能提升的原因?
加入5层的卷积+maxpooling+3层全连接+softmax、加入了dropout提升模型泛化能力
LRN:卷积输出通道的是点的领域取值的归一化。
Overlapping Pooling:下采样,感知野在featuremap有重复区域的
4、罗列出不少于4条的深度学习模型调优方法?
(1)由小数据到大数据:
刚开始, 先上小规模数据, 模型往大了放, 只要不爆显存, 能用256个filter你就别用128个. 直接奔着过拟合去。目的:验证自己的训练脚本的流程对不对。如果小数据量下, 你这么粗暴的大网络奔着过拟合去都没效果. 那么, 你要开始反思自己了, 模型的输入输出是不是有问题? 要不要检查自己的代码(永远不要怀疑工具库, 除非你动过代码)? 模型解决的问题定义是不是有问题? 你对应用场景的理解是不是有错?
(2)loss设计要合理:
一般来说分类就是Softmax, 回归就是L2的loss. 但是要注意loss的错误范围(主要是回归), 你预测一个label是10000的值, 模型输出0, 你算算这loss多大, 这还是单变量的情况下. 一般结果都是nan. 所以不仅仅输入要做normalization, 输出也要这么弄.多任务情况下, 各loss想法限制在一个量级上, 或者最终限制在一个量级上, 初期可以着重一个任务的loss。
(3)观察loss胜于观察准确率:
LOSS下降时稳定的,而准确率有时是突变的,不能反映真实情况。给NN一点时间, 要根据任务留给NN的学习一定空间. 不能说前面一段时间没起色就不管了. 有些情况下就是前面一段时间看不出起色, 然后开始稳定学习.
(4)确认分类网络学习充分
分类网络就是学习类别之间的界限. 你会发现, 网络就是慢慢的从类别模糊到类别清晰的. 怎么发现? 看Softmax输出的概率的分布. 如果是二分类, 你会发现, 刚开始的网络预测都是在0.5上下, 很模糊. 随着学习过程, 网络预测会慢慢的移动到0,1这种极值附近. 所以, 如果你的网络预测分布靠中间, 再学习学习。
(5)学习率设置合理
太大: loss爆炸, 或者nan;太小: 半天loss没反映。当loss在当前LR下一路降了下来, 但是半天不再降了,就需要进一步降低了LR了。
(6)对比训练集和验证集的loss
判断过拟合, 训练是否足够, 是否需要early stop的依据, 这都是中规中矩的原则, 不多说了.
(7)清楚receptive field的大小
CV的任务, context window是很重要的. 所以你对自己模型的receptive field的大小要心中有数. 这个对效果的影响还是很显著的. 特别是用FCN, 大目标需要很大的receptive field. 不像有fully connection的网络, 好歹有个fc兜底, 全局信息都有。
(8)最后一层激活函数:分类softmax,回归的话一般不用,直接输出wx+b。
(9)训练数据增强:旋转、裁剪、亮度、色度、饱和度等变化等增加鲁棒性。
卷积后的featuremap大小计算:[(featuremap-kernaelsize)+(kernalsize-stride)] / stride +1














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









