







集合的流操作和函数式编程都是JDK8的新特性,重语法,记住就行,记不住的就多用几遍,用习惯了开发效率会提高不少。
试试这些新特性前先做了数据初始化的准备工作,接下来的例子都是用这几个集合,如下:
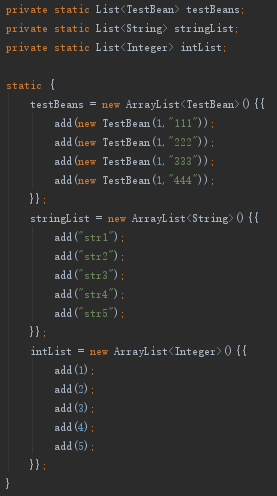
准备好了那就一个一个来了。
1.match
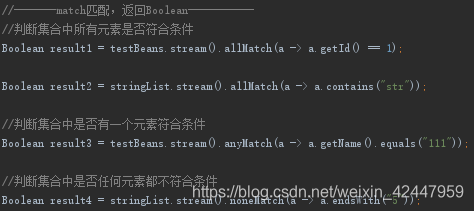
a即为集合中元素的变量,记住a -> 这种写法就行,返回布尔型。
2.find
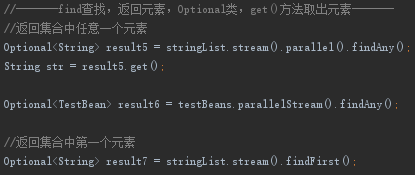
findFirst()返回第一个元素这没啥可说的。有意思的是findAny(),是个挂羊头卖狗肉的方法,看上去是返回任意一个元素,其实是返回线程最快处理完的那个数据。但是因为List是有序的 ,且stream()拿到的是一个串行流,就一个线程在处理,所以串行流中findAny()返回的必然是第一个元素,在并行流中就不是了。
并行流就是把数据分割成多个数据块,每个数据块对应一个流,然后多线程分别处理各个数据块中的流,而findAny()返回的是最快处理完成的那个数据,那理论上并行流中findAny()返回的元素应该是随机的呀。我试了一下,居然也是固定的,而且还和集合的长度有关,大胆的猜测下这应该和并行流如何分块有关,即和集合的长度有关系。如上图有两种可以拿到并行流:list.stream().parallel()或者直接list.parallelStream()。
还要注意一下find处理后返回的是Optional类,这也是jdk8的新特性,用来处理烦人的空指针的,其get()方法可以返回元素。
3.reduce
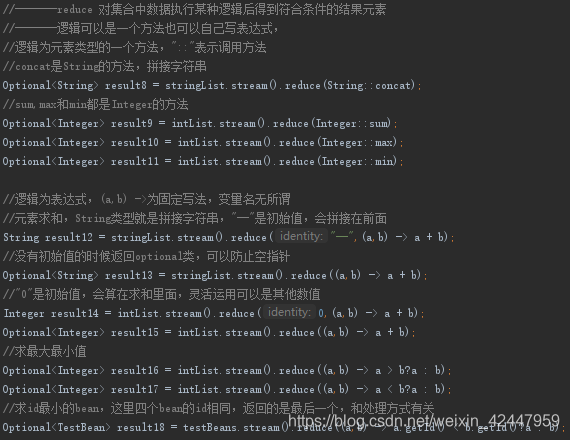
reduce记住语法就行了,(a,b)-> 表达式 执行表达式中的逻辑,::是函数式编程的调用方法,理解一下记住就行了。
4.map

这个flatMap流的扁平化我想画个图:
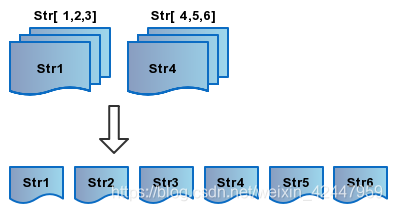
理解一下,扁平化就是将堆叠在一起的流元素铺平。
5.其他
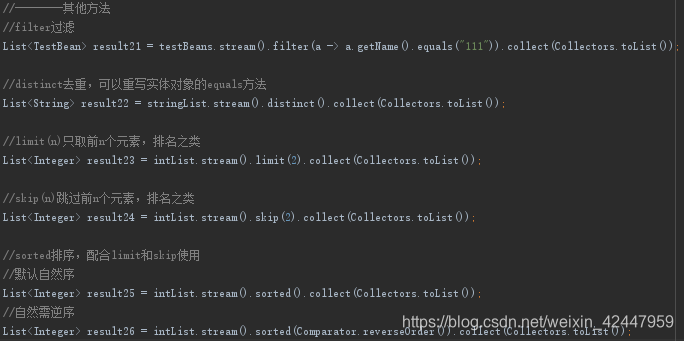
sorted如何想用自定义规则排序,集合元素必须实现Comparable接口并重写compareTo()方法,即可排序的。















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









