








这次我们来说说关于数据预处理中的数据标准化及归一化的问题。主要以理论+实例的方式为大家展示。
本次实验也将会展示部分数据以及代码,有兴趣的小伙伴可以自己动手试试~
在本次实例过程中,我们使用的数据是:2010-2018年间广州市经济与环境的时间序列资料,数据来源为《广州市统计年鉴》及《国民经济和社会发展统计公报》,感兴趣的同学也可利用其它数据进行实例操作。(本次实验的Excel数据附在文后)
一、归一化(Normalization)
描述:
将数据映射到指定的范围,如:把数据映射到0~1或-1~1的范围之内处理。
作用:
- 1、数据映射到指定的范围内进行处理,更加便捷快速。
- 2、把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。经过归一化后,将有量纲的数据集变成纯量,还可以达到简化计算的作用。
常见做法:Min-Max归一化
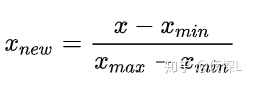
python实现:
(1)导入数据并删除我们不要的列:
import numpy as np
import pandas as pd
df=pd.read_excel('C://Users/Administrator/Desktop/data_py.xlsx',sheet_name='广州',encoding='utf-8')
df.drop(columns="时间",axis=1,inplace=True)
df.set_index([[2010,2011,2012,2013,2014,2015,2016,2017,2018]],inplace=True)
df.drop(columns=['第二产业产值占比' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









