






前言
参考文献
参考张俊林老师的文章《放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较》梳理记录一下
一、NLP任务的特点
预测
特征抽取器:RNN、CNN、Transformer 等
NLP任务的特点和图像有极大的不同:
- 输入是一个以为线性序列
- 输入是不定长的,有长有短,模型处理增加了一些小麻烦
- 单词或子句的相对位置关系很重要,两个单词位置互换可能导致完全不同的意思
eg. “你欠我那一千万不用还了”和“我欠你那一千万不用还了” - 句子中的长距离特征对于理解语义也非常关键
eg.如果你愿意一层一层的剥开我的心…那么你会坐牢的我跟你说
上面这几个特点请记清,一个特征抽取器是否适配问题领域的特点,有时候决定了它的成败,而很多模型改进的方向,其实就是改造得使得它更匹配领域问题的特性。
二、NLP的四大类任务
- 序列标注:中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。
- 分类任务:文本分类,情感计算等。它的特点是不管文章有多长,总体给出一个分类类别即可。
- 句子关系判断:Entailment,QA,语义改写,自然语言推理等。它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系
- 生成式任务:机器翻译,文本摘要,写诗造句,看图说话等。它的特点是输入文本内容后,需要自主生成另外一段文字。
解决这些不同的任务,从模型角度来讲什么最重要?是特征抽取器的能力。因为深度学习最大的优点是“端到端(end to end)”,这里的意思是以前研发人员得考虑设计抽取哪些特征,而端到端时代后,这些你完全不用管,把原始输入扔给好的特征抽取器,它自己会把有用的特征抽取出来。
三、介绍三种主流的特征抽取器
1. RNN
优势所在:
RNN的结构天然适配解决NLP的问题,NLP的输入往往是个不定长的线性序列句子,而RNN本身结构就是个可以接纳不定长输入的由前向后进行信息线性传导的网络结构,而在LSTM引入三个门后,对于捕获长距离特征也是非常有效的。所以RNN特别适合NLP这种线形序列应用场景,这是RNN为何在NLP界如此流行的根本原因。
RNN 存在的问题:RNN很难具备高效的并行计算能力,也就说在工业界没有实际落地应用支撑其存在价值
RNN并行计算能力差的原因:T时刻隐层状态的计算,依赖两个输入,一个是T时刻的句子输入单词Xt,关键的是另外一个输入,T-1时刻的隐层状态S(t-1)的输出,最能体现RNN本质特征的一点。这样就形成了序列依赖关系,在这个角度上无法并行计算。

CNN和Transformer就不存在这种序列依赖问题,所以对于这两者来说并行计算能力就不是问题,每个时间步的操作可以并行一起计算。
两种改进思路:
- 隐层单元之间进行并行计算(SRU方法)
- 部分打断隐层之间的连接,通过层深来建立远距离特征之间的联系(Sliced RNN——简化版的CNN)
2.CNN

最初版的是Kim2014的CNN,一般而言,输入的字或者词用Word Embedding的方式表达,这样本来一维的文本信息输入就转换成了二维的输入结构,假设输入X包含n个字符,而每个字符的Word Embedding的长度为d,那么输入就是dn的二维向量。
卷积层本质上是个特征抽取层,可以设定超参数F来指定卷积层包含多少个卷积核(Filter)。对于某个Filter来说,可以想象有一个dk大小的移动窗口从输入矩阵的第一个字开始不断往后移动,其中k是Filter指定的窗口大小,d是Word Embedding长度。
对于某个时刻的窗口,通过神经网络的非线性变换,将这个窗口内的输入值转换为某个特征值,随着窗口不断往后移动,这个Filter对应的特征值不断产生,形成这个Filter的特征向量。这就是卷积核抽取特征的过程。卷积层内每个Filter都如此操作,就形成了不同的特征序列。
Pooling 层则对Filter的特征进行降维操作,形成最终的特征。一般在Pooling层之后连接全联接层神经网络,形成最后的分类过程。
Kim2014的CNN存在的问题:
- CNN捕获的特征体现在卷积核覆盖的滑动窗口里,单卷积层无法捕获远距离特征。
—— 解决方法:
- 单个卷积层,卷积核窗口不覆盖连续区域(Dilated CNN)
- 叠加卷积层:第一层卷积层,假设滑动窗口大小k是3,如果再往上叠一层卷积层,假设滑动窗口大小也是3,但是第二层窗口覆盖的是第一层窗口的输出特征,所以它其实能覆盖输入的距离达到了5。(加深CNN网络)


- Max Pooling层丢失信息
CNN的卷积核是能保留特征之间的相对位置的,但是如果卷积层后面立即接上Pooling层的话,Max Pooling的操作逻辑是:从一个卷积核获得的特征向量里只选中并保留最强的那一个特征,所以到了Pooling层,位置信息就被扔掉了,这在NLP里其实是有信息损失的。所以在NLP领域里,目前CNN的一个发展趋势是抛弃Pooling层,靠全卷积层来叠加网络深度(当然图像领域也是这个趋势)。
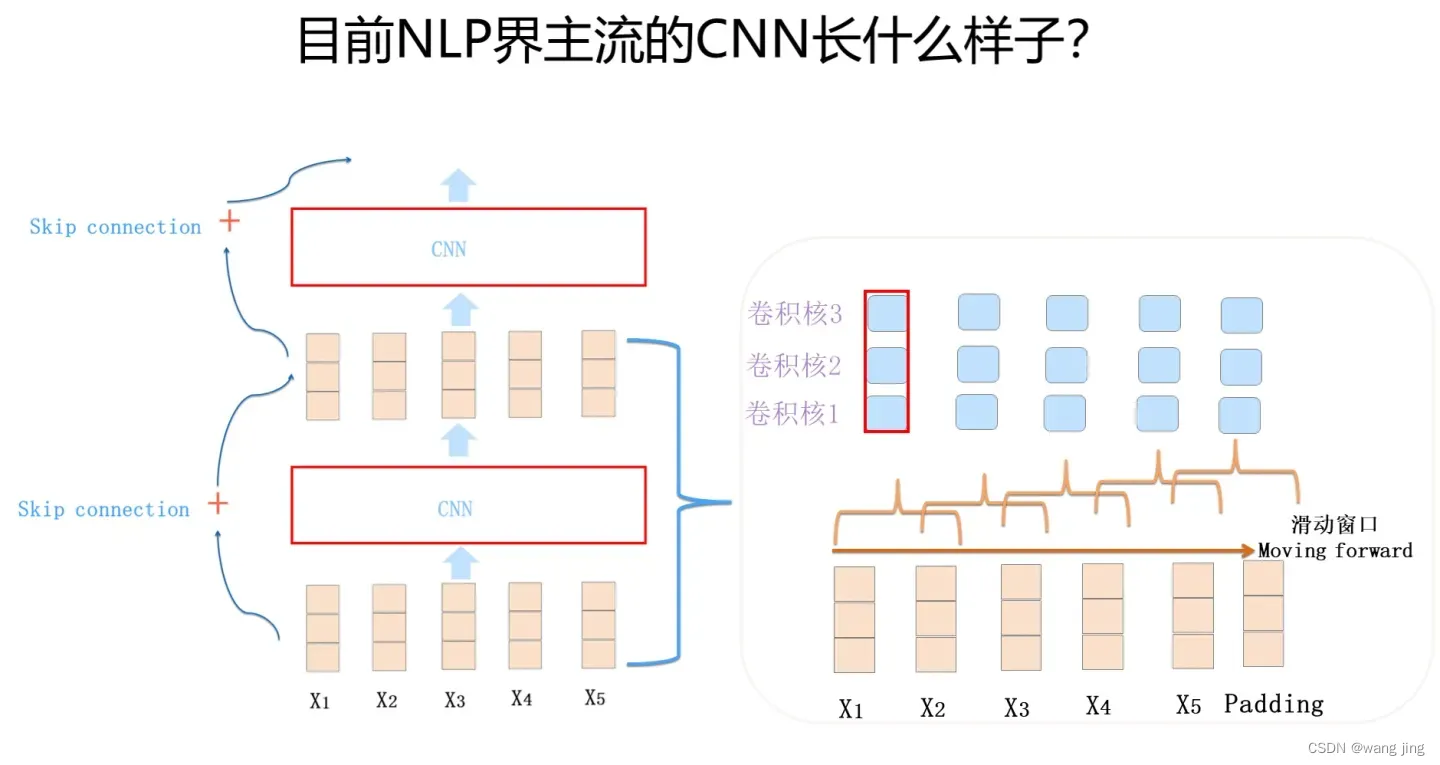 通常由1-D卷积层来叠加深度,使用Skip Connection来辅助优化,也可以引入Dilated CNN等手段。比如ConvS2S主体就是上图所示结构,Encoder包含 15个卷积层,卷积核kernel size=3,覆盖输入长度为25。当然对于ConvS2S来说,卷积核里引入GLU门控非线性函数也有重要帮助,限于篇幅,这里不展开说了,GLU貌似是NLP里CNN模型必备的构件,值得掌握。
通常由1-D卷积层来叠加深度,使用Skip Connection来辅助优化,也可以引入Dilated CNN等手段。比如ConvS2S主体就是上图所示结构,Encoder包含 15个卷积层,卷积核kernel size=3,覆盖输入长度为25。当然对于ConvS2S来说,卷积核里引入GLU门控非线性函数也有重要帮助,限于篇幅,这里不展开说了,GLU貌似是NLP里CNN模型必备的构件,值得掌握。
CNN的卷积核是能保留特征之间的相对位置的,道理很简单,滑动窗口从左到右滑动,捕获到的特征也是如此顺序排列,所以它在结构上已经记录了相对位置信息了。
CNN的并行计算能力,那是非常强的,这其实很好理解。我们考虑单层卷积层,首先对于某个卷积核来说,每个滑动窗口位置之间没有依赖关系,所以完全可以并行计算;另外,不同的卷积核之间也没什么相互影响,所以也可以并行计算。CNN的并行度是非常自由也非常高的,这是CNN的一个非常好的优点。
3.Transformer

Transformer Encoder部分(红框内整体)就是由若干个相同的Transformer Block堆叠成的。 这个Transformer Block其实才是Transformer最关键的地方

针对NLP任务的特点来说下Transformer的对应解决方案:
输入不定长:Transformer做法跟CNN是类似的,一般设定输入的最大长度,如果句子没那么长,则用Padding填充。
保留位置信息编码:因为输入的第一层网络是Muli-head self attention层,Self attention会让当前输入单词和句子中任意单词发生关系,然后集成到一个embedding向量里,但是当所有信息到了embedding后,位置信息并没有被编码进去。所以,Transformer不像RNN或CNN,必须明确的在输入端将Positon信息编码,Transformer是用位置函数来进行位置编码的,而Bert等模型则给每个单词一个Position embedding,将单词embedding和单词对应的position embedding加起来形成单词的输入embedding。
NLP句子中长距离依赖特征的问题:Self attention天然就能解决这个问题,因为在集成信息的时候,当前单词和句子中任意单词都发生了联系,所以一步到位就把这个事情做掉了。(不像RNN需要通过隐层节点序列往后传,也不像CNN需要通过增加网络深度来捕获远距离特征)
Transformer有两个版本:Transformer base和Transformer Big。两者结构其实是一样的,主要区别是包含的Transformer Block数量不同,Transformer base包含12个Block叠加,而Transformer Big则扩张一倍,包含24个Block。
4.三大特征抽取器比较
参考笔记:三大特征提取器














 3877
3877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









