









前言
循环神经网络(RNN),长短期记忆网络(LSTM),门限循环单元(GRU)。
一、RNN

RNN原理:神经网络模块A,读取到某个输入x,并且输出一个值h,循环可以使得信息可以从当前一步传到下一步。RNN本质上是与序列和列表相关的。展开来看,RNN可以被看做是同一神经网络的多次复制,每一个神经网络模块都会把信息传递给下一个。展开上图的循环可以得到:
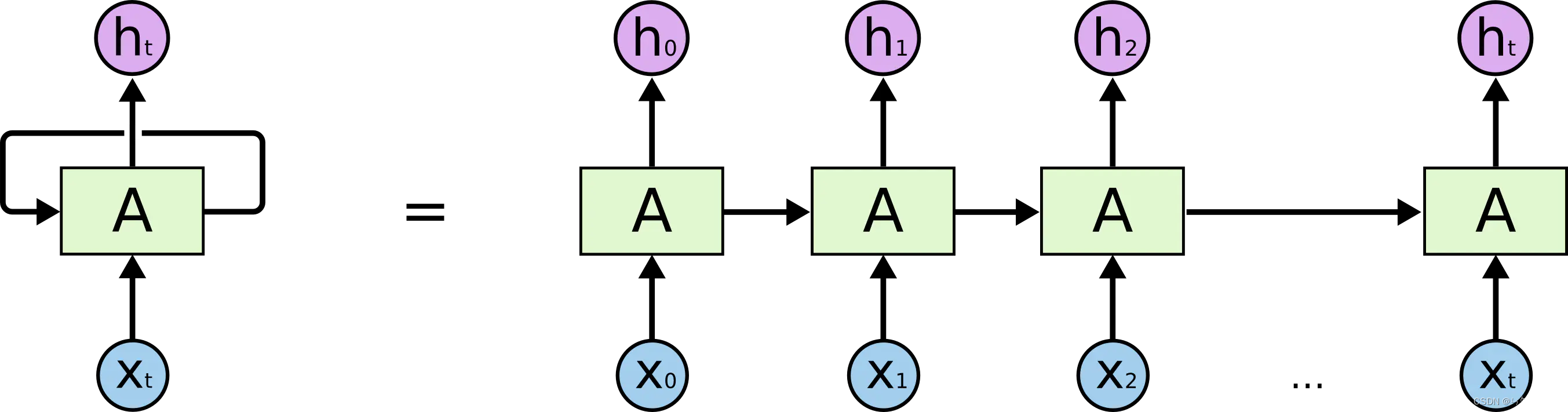
注意:每一个神经网络模块所用的权重参数都是共享的,即权重共享。
RNN的缺点:
1、受到短时记忆的影响,如果一条序列足够长,那它们将很难将信息从较早的时间步传送到后面的时间步,即长期依赖问题。
2、梯度可能会随着时间的推移不断下降减少,而梯度变的非常小的时候,就不会再继续学习,可能会发生梯度消失。
RNN神经网络模块内部结构:在标准RNN中,这个模块只有一个很简单的结构,例如tanh层。
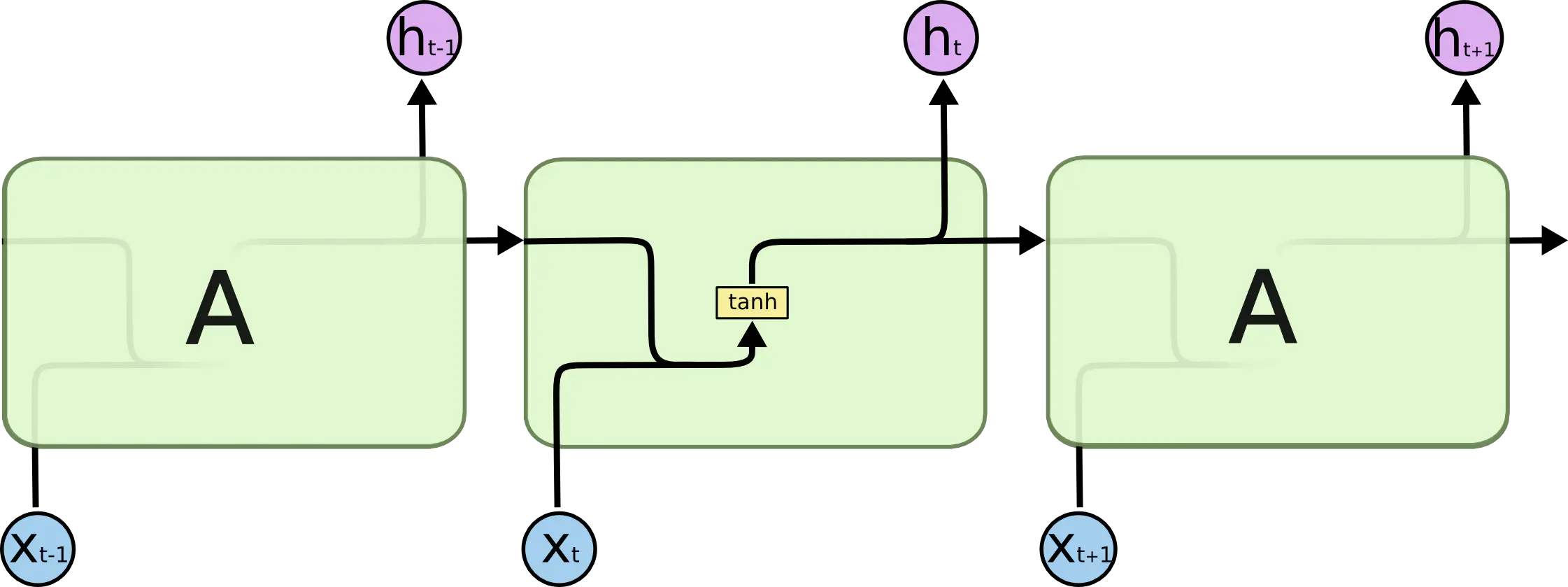
二、LSTM
LSTM定义:是一种RNN特殊的类型,通过刻意的结构设计来解决长期依赖问题。在传统RNN基础上引入了细胞状态,可以对输入信息进行选择和保存,这是LSTM的关键。
相比与RNN的优点:
1、弥补RNN短时记忆的缺点,可以有效保存很长时间之前的关联信息。
2、可以减少梯度消失和梯度爆炸问题。
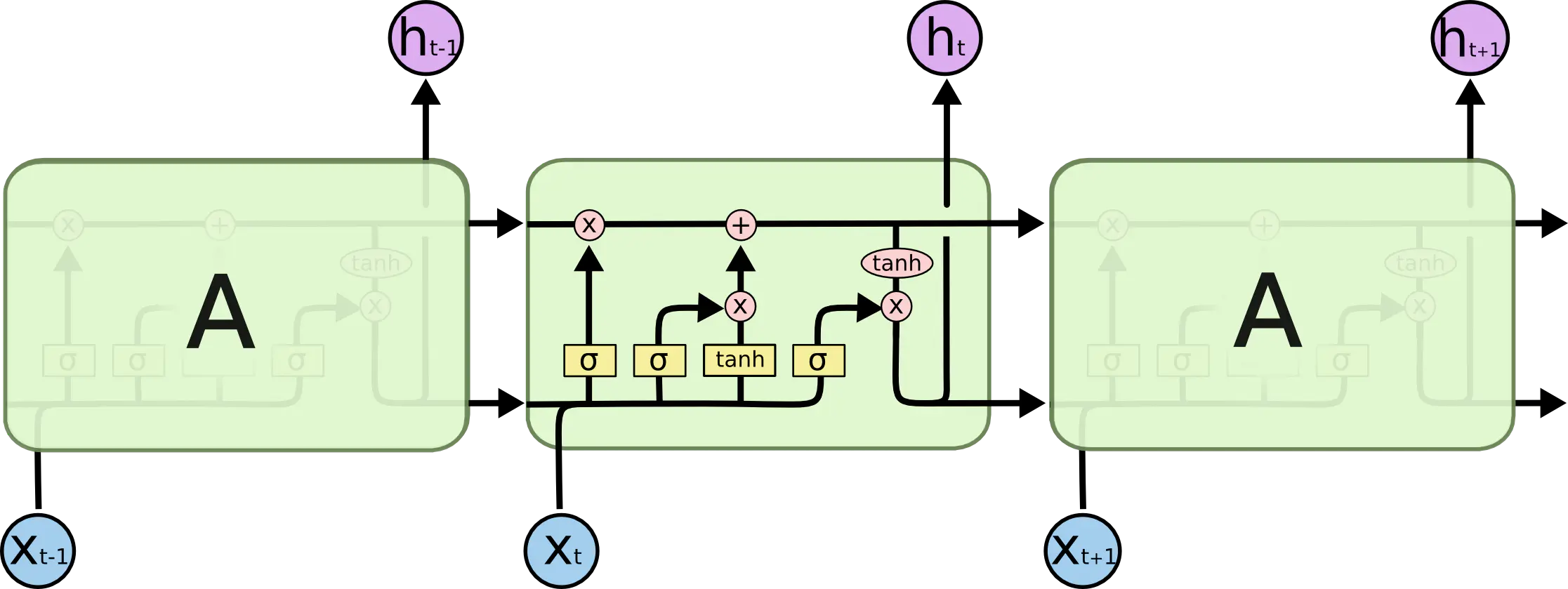
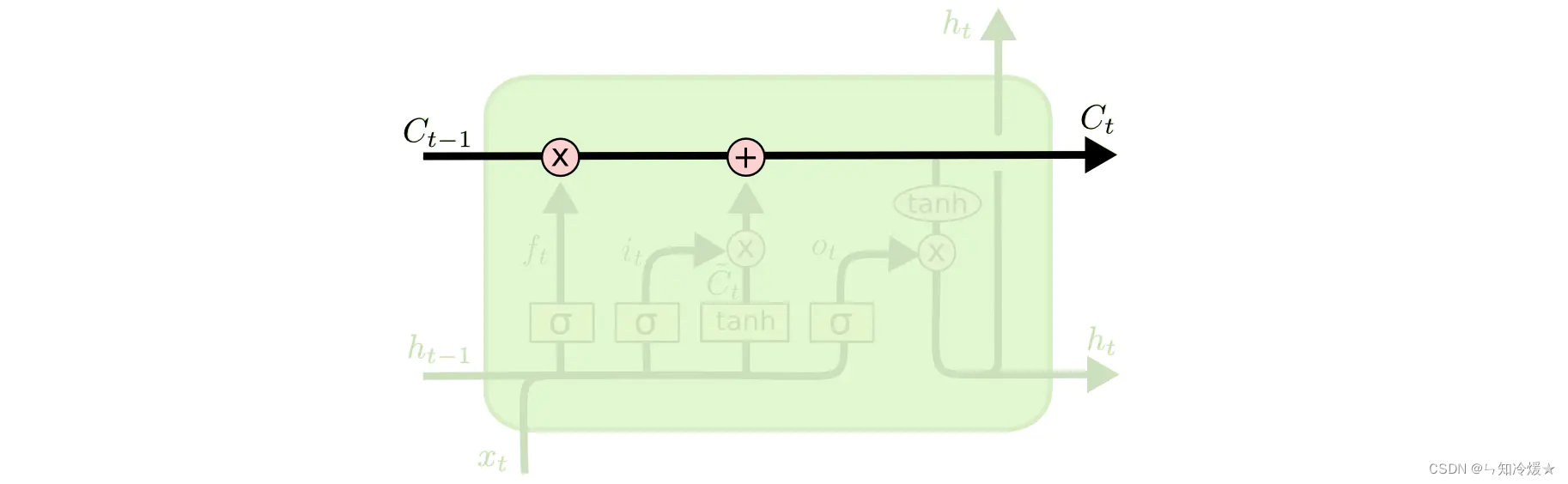
细胞状态:细胞状态类似于传送带,直接在整个链上运行,交互较少,信息在上面流传保持不变会比较容易。
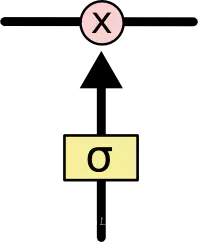
门结构:LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个按位的乘法操作。Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!LSTM 拥有三个门,来保护和控制细胞状态。
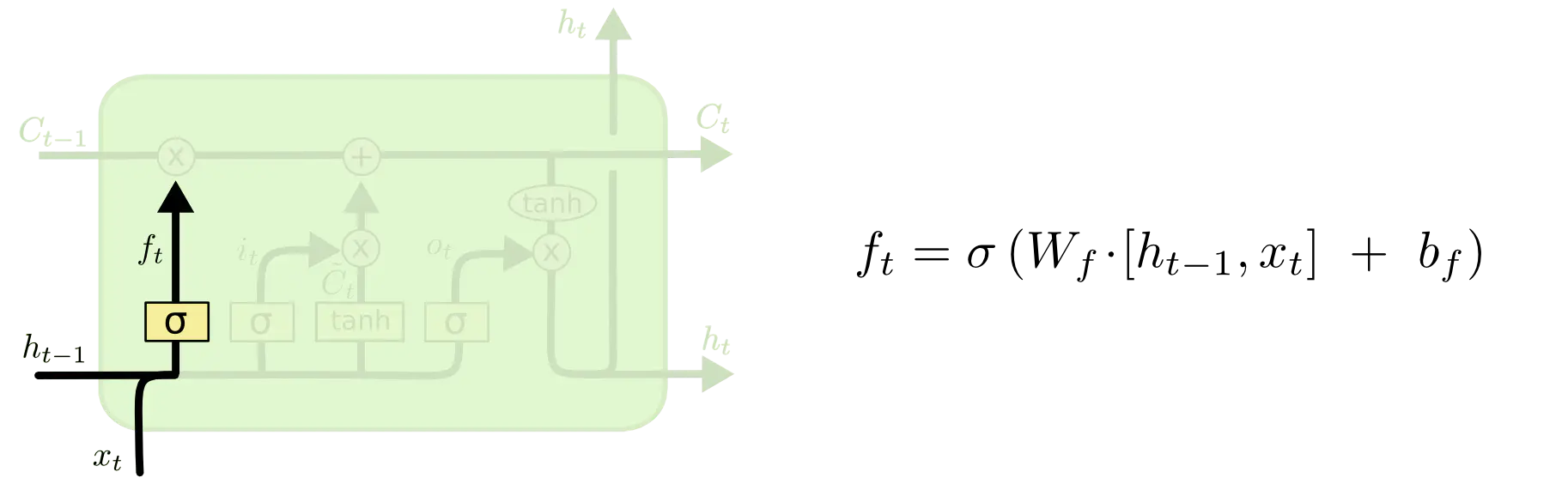
遗忘门:该门的作用是将上一个细胞的输出
h
t
−
1
h_{t-1}
ht−1和当前细胞的输入
x
t
x_t
xt,经过线性变换(
h
t
−
1
h_{t-1}
ht−1和
x
t
x_t
xt分别与
W
f
W_f
Wf相乘然后相加)再经过sifmoid层输出一个0到1之间的数值。1表示完全保留,0表示完全舍弃。我们可能希望忘记一些旧的主语,并且记住一些新的主语,这时候遗忘门就起到了作用。
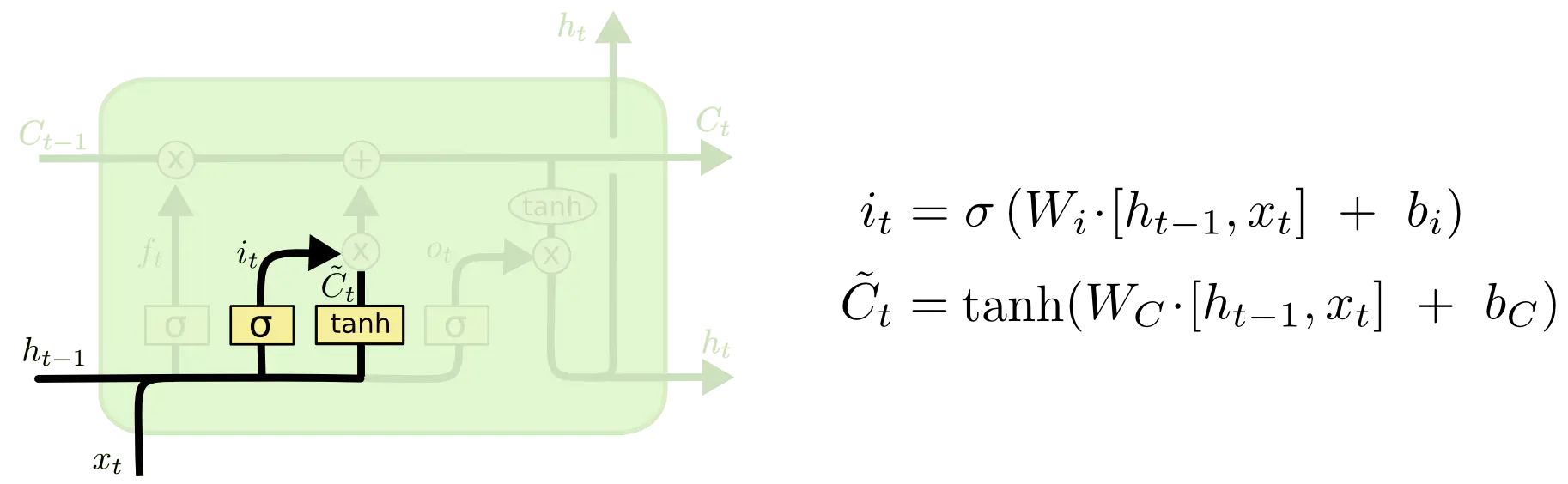
输入门:确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,会被加入到状态中。
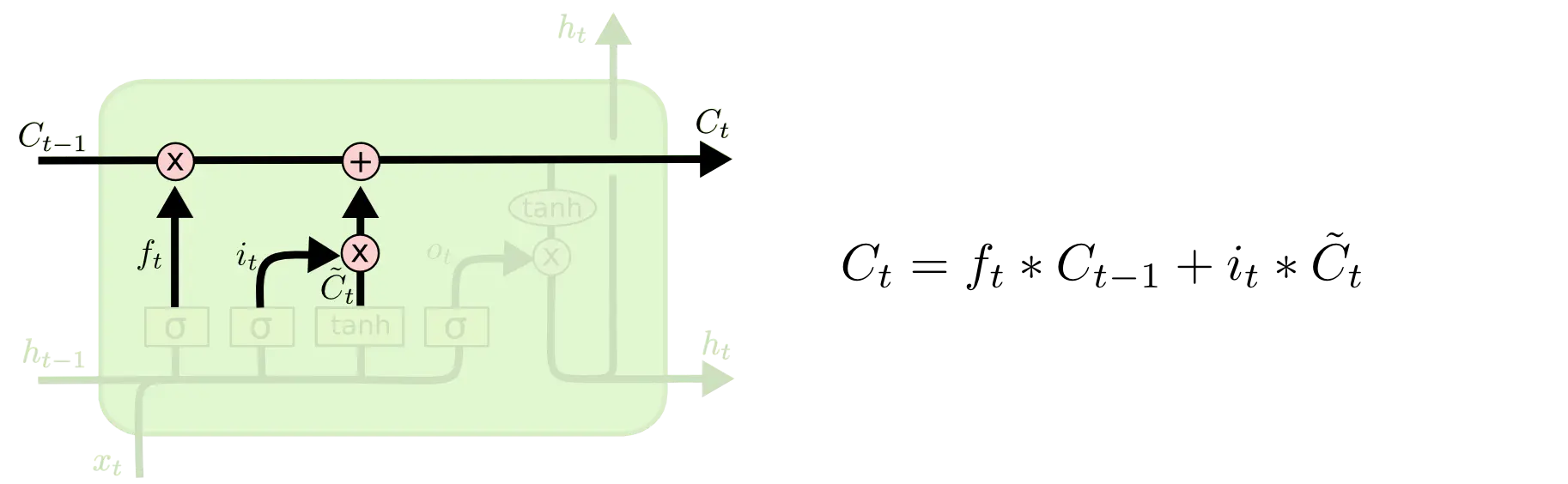
细胞状态更新:更新细胞状态,使用上一个细胞状态
C
t
−
1
C_{t-1}
Ct−1,遗忘门的输出、输入门的输出,经过点击、相加等操作,
C
t
−
1
C_{t-1}
Ct−1更新为
C
t
C_{t}
Ct。
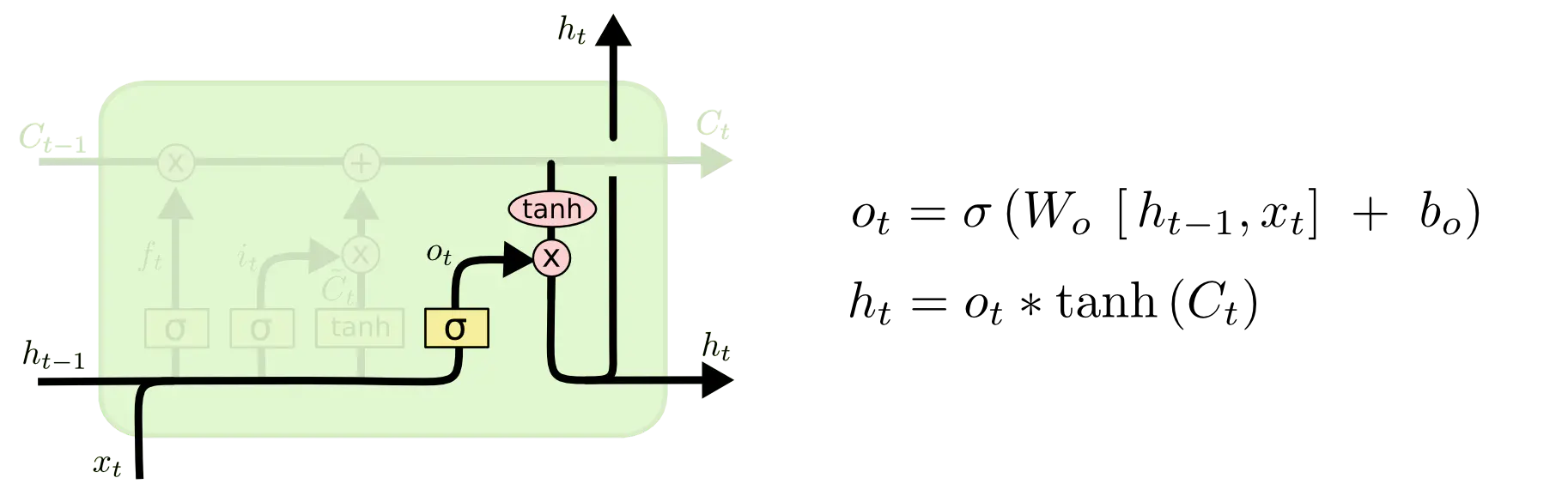
输出门:确定输出值,即过滤后的一个版本。(首先上一个细胞状态
h
t
−
1
h_{t-1}
ht−1和该细胞的输入
x
t
x_t
xt通过线性变换,再经过sigmoid层来确定将哪个部分输出,即
o
t
o_t
ot,接着我们把细胞状态
C
t
−
1
C_{t-1}
Ct−1通过tanh进行处理,得到一个-1到1之间的值,并将它和sigmoid门的输出
o
t
o_t
ot相乘,得到最终的输出
h
t
h_t
ht。)
三、GRU
GRU定义:GRU是LSTM的一个变体,保持了LSTM效果的同时又使得结构更加简单。将遗忘门和输入们合并成为了一个单一的更新门。并且GRU没有细胞状态,大大简化了结构,相比于LSTM,GRU有更少的参数,训练的时候过拟合问题没有那么严重。

参考文章:
理解 LSTM 网络.
LSTM网络的变体之GRU网络.
总结
好热,烤熟了。



















 2574
2574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











