






一、入门
1.1 简介
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的 列式存储 数据库(DBMS),使用 C++ 语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。
- 特点
- 分布式列式存储:统计操作更快、更容易进行数据压缩;
- 多样化引擎:把表级的存储引擎插件化,根据表的
不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类 20 多种引擎。 - 高吞吐与写入能力:ClickHouse 采用类 LSM Tree的结构,数据写入后
定期在后台 Compaction。通过类 LSM tree的结构,ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,在后台compaction 时也是多个段 merge sort 后顺序写回磁盘。 - 数据分区与线程级并行:ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index granularity(索引粒度),然后通过多个 CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,
单条 Query 就能利用整机所有 CPU。
- 使用场景
ClickHouse 的优势时大数量级的单张宽表的聚合查询分析。
- 绝大多数请求都是用于读访问,而且不是单点访问,都是范围查询或者全表扫描;
- 数据需要以大批次进行更新(大于1000行),而不是单行更新;或者没有更新操作;
- 读取数据时,会从数据库中提取大量的行,但只用到一小部分列;
- 表很 “宽”,即表中包含大量的列;
- 查询频率相对较低(通常每台服务器每秒查询数百次或更少);
- 对于简单查询,允许大约50毫秒延迟;
- 列的值是比较小的数值或短字符串(例如,每个URL只有60个字节);
- 在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行);
- 不需要事务;
- 数据一致性要求较低;
- 每次查询只会查询一个大表,其余都是小表;
- 查询结果显著小于数据源,即数据有过滤或聚合,返回结果不超过单个服务器内存大小。
1.2 单机部署
参考:https://clickhouse.tech/docs/en/getting-started/install/#from-rpm-packages
单机即可满足大部分学习场景,生产需要再考虑部署高可用或分布式集群(因为还会增添操作上的麻烦)。
sudo yum install yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
sudo yum install clickhouse-server clickhouse-client
sudo systemctl start clickhouse-server.service
clickhouse-client
[root@cloud-mn01 ~]# clickhouse-client
ClickHouse client version 21.7.5.29 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 21.7.5 revision 54449.
cloud-mn01 :) show databases;
SHOW DATABASES
Query id: 7efd3129-2076-4eff-8bac-2a314abf7b78
┌─name────┐
│ default │
│ system │
└─────────┘
2 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :) Bye.
[root@cloud-mn01 ~]# clickhouse-client --query "show databases"
default
system
[root@cloud-mn01 ~]#
1.3 高可用集群
- 副本写入流程
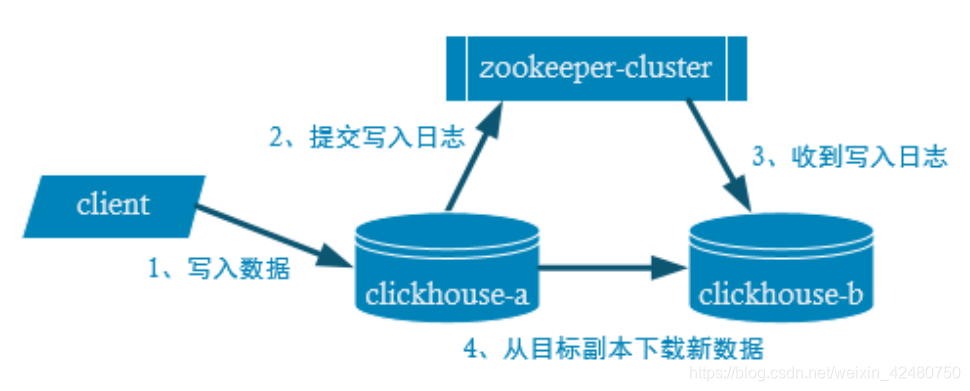
- 配置文件
/etc/clickhouse-server/config.xml
<zookeeper>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper>
- 建表
副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表。
ReplicatedMergeTree 中,第一个参数是分片的 zk_path 一般按照:/clickhouse/table/{shard}/{table_name} 的格式写,如果只有一个分片就写 01 即可。第二个参数是副本名称,相同的分片副本名称不能相同。
CREATE TABLE t_order_rep2
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/table/01/t_order_rep', 'rep_101')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
CREATE TABLE t_order_rep2
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/table/01/t_order_rep', 'rep_102')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
1.4 分布式集群
- 集群写入流程
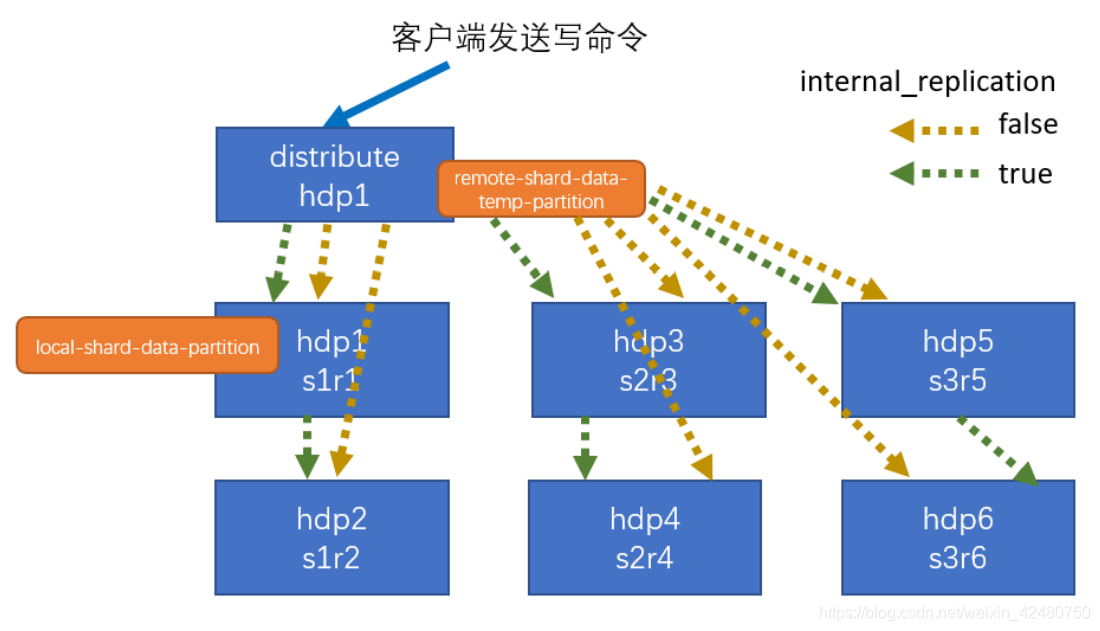
- 集群读取流程
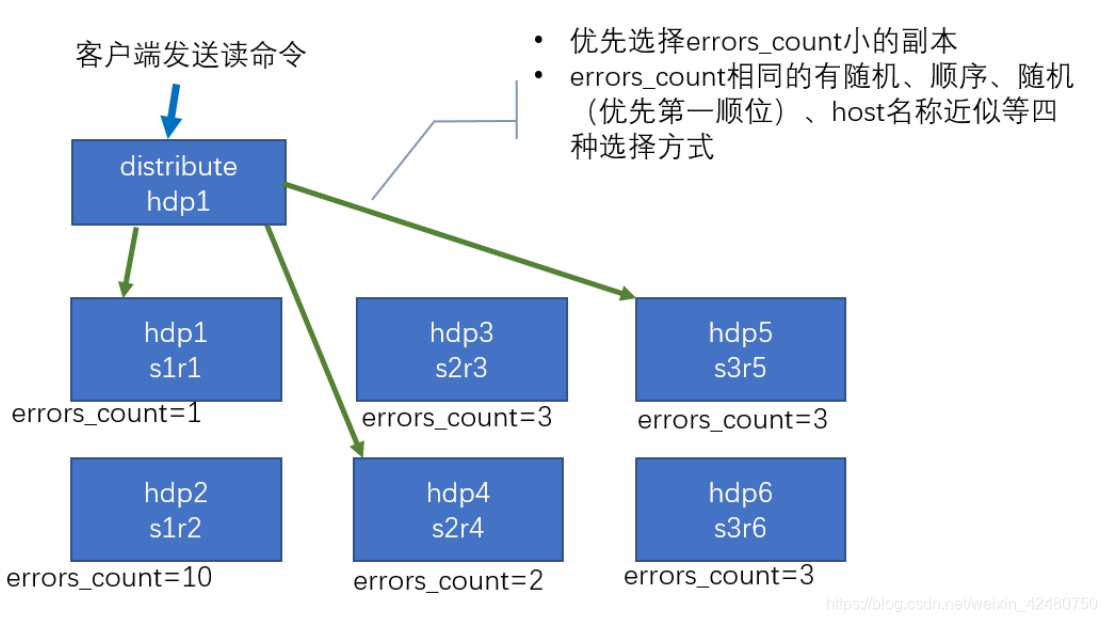
- 配置文件
/etc/clickhouse-server/config.xml
<remote_servers>
<gmall_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<!--该分片的第一个副本-->
<replica>
<host>hadoop101</host>
<port>9000</port>
</replica>
<!--该分片的第二个副本-->
<replica>
<host>hadoop102</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop103</host>
<port>9000</port>
</replica>
<replica> <!--该分片的第二个副本-->
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第三个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop105</host>
<port>9000</port>
</replica>
<replica> <!--该分片的第二个副本-->
<host>hadoop106</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
<zookeeper>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper>
<macros>
<shard>01</shard> <!--不同机器放的分片数不一样-->
<replica>rep_1_1</replica> <!--不同机器放的副本数不一样-->
</macros>
- 建表语句
- 数据表
此表中仅可以查到其分片中的数据
CREATE TABLE st_order_mt ON CLUSTER gmall_cluster
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt', '{replica}')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
- 分布式表
此表中可以查到所有的数据
CREATE TABLE st_order_mt_all2 ON CLUSTER gmall_cluster
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = Distributed(gmall_cluster, default, st_order_mt, hiveHash(sku_id))
1.5 数据类型
完整数据类型文档参考:https://clickhouse.tech/docs/en/sql-reference/data-types/#data_types
- 整型
| 类型 | 范围 |
|---|---|
| Int8 | [-128 : 127] |
| Int16 | [-32768 : 32767] |
| Int32 | [-2147483648 : 2147483647] |
| Int64 | [-9223372036854775808 : 9223372036854775807] |
| UInt8 | [0 : 255] |
| UInt16 | [0 : 65535] |
| UInt32 | [0 : 4294967295] |
| UInt64 | [0 : 18446744073709551615] |
- 浮点型
| 类型 | 说明 |
|---|---|
| Float32 | float |
| Float64 | double |
建议尽可能以整数形式存储数据,因为浮点型进行计算时可能引起四舍五入的误差。
cloud-mn01 :) select 1.0 - 0.9;
SELECT 1. - 0.9
Query id: ec6a31cf-42df-418e-bcd5-63b3732ecb44
┌──────minus(1., 0.9)─┐
│ 0.09999999999999998 │
└─────────────────────┘
1 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
- 布尔型
没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
- Decimal 型
有符号的浮点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。
| 类型 | 说明 |
|---|---|
| Decimal32(s) | 相当于 Decimal(9-s,s),有效位数为 1~9(s标识小数位数) |
| Decimal64(s) | 相当于 Decimal(18-s,s),有效位数为 1~18 |
| Decimal128(s) | 相当于 Decimal(38-s,s),有效位数为 1~38 |
- 字符串
- String
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
- FixedString(N)
固定长度 N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于 N 的字符串时候,通过在字符串末尾添加空字节来达到 N 字节长度。 当服务端读取长度大于 N 的字符串时候,将返回错误消息。
- 枚举类型
包括 Enum8 和 Enum16 类型。Enum 保存 ‘string’= integer 的对应关系。
# 使用 -m 选项可以支持换行
[root@cloud-mn01 ~]# clickhouse-client -m
ClickHouse client version 21.7.5.29 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 21.7.5 revision 54449.
# 创建
cloud-mn01 :) CREATE TABLE t_enum
:-] (
:-] x Enum8('hello' = 1, 'world' = 2)
:-] )
:-] ENGINE = TinyLog;
CREATE TABLE t_enum
(
`x` Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog
Query id: b1bdb268-0cd1-4d1a-ad5a-59fc767bb85d
Ok.
0 rows in set. Elapsed: 0.008 sec.
# 插入
cloud-mn01 :) INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello');
INSERT INTO t_enum VALUES
Query id: 16a4ae7c-20a8-4a2c-a4f3-0201823740ca
Ok.
3 rows in set. Elapsed: 0.002 sec.
# 查看 enum 值对应的数字
cloud-mn01 :) SELECT CAST(x, 'Int8') FROM t_enum;
SELECT CAST(x, 'Int8')
FROM t_enum
Query id: f9a69904-c5ef-4157-940b-bd171c040063
┌─CAST(x, 'Int8')─┐
│ 1 │
│ 2 │
│ 1 │
└─────────────────┘
3 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
- 时间类型
| 类型 | 说明 |
|---|---|
| Date | 接受年-月-日的字符串比如 ‘2019-12-16’ |
| Datetime | 接受年-月-日 时:分:秒的字符串比如 ‘2019-12-16 20:50:10’ |
| Datetime64 | 接受年-月-日 时:分:秒.亚秒的字符串比如‘2019-12-16 20:50:10.66’ |
- 数组
Array(T):由 T 类型元素组成的数组。
# 创建数组方式 1,使用 array 函数
cloud-mn01 :) SELECT array(1, 2) AS x, toTypeName(x);
SELECT
[1, 2] AS x,
toTypeName(x)
Query id: 30ac6d4c-854e-49b2-bc19-ed1529aa0dde
┌─x─────┬─toTypeName(array(1, 2))─┐
│ [1,2] │ Array(UInt8) │
└───────┴─────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
# 创建数组方式 2:使用方括号
cloud-mn01 :) SELECT [1, 2] AS x, toTypeName(x);
SELECT
[1, 2] AS x,
toTypeName(x)
Query id: 9a6701df-9622-46a3-9a91-a0ad968f6f0a
┌─x─────┬─toTypeName([1, 2])─┐
│ [1,2] │ Array(UInt8) │
└───────┴────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- 空值
为了区别空值,clickhouse 额外要存储 masks 文件,相对普通值会消耗更多空间。尽量避免空值的使用,可以存储以业务侧无意义的值如 -1 标识空值。
二、表引擎
完整表引擎清单参见:https://clickhouse.tech/docs/en/engines/table-engines/#table_engines
- 简介
表引擎是 ClickHouse 的一大特色。可以说, 表引擎决定了如何存储表的数据。
- 数据的存储方式和位置,写到哪里以及从哪里读取数据。
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
2.1 Log
- TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试用。
cloud-mn01 :) show create table t_tinylog;
SHOW CREATE TABLE t_tinylog
Query id: 9f444ef0-6b2d-4cc7-af79-32e885db9c7a
┌─statement─────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.t_tinylog
(
`id` String,
`name` String
)
ENGINE = TinyLog │
└───────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
2.2 Integration
- MySQL
The MySQL engine allows you to perform SELECT and INSERT queries on data that is stored on a remote MySQL server.
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause'])
SETTINGS
[connection_pool_size=16, ]
[connection_max_tries=3, ]
[connection_auto_close=true ]
;
cloud-mn01 :) SHOW CREATE TABLE mysql;
SHOW CREATE TABLE mysql
Query id: 1d8f5ea0-0f46-4ad8-8033-aa96b8cdb2b1
┌─statement───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.mysql
(
`name` String,
`age` Int8
)
ENGINE = MySQL('127.0.0.1:3306', 'clickhouse', 'person', 'root', '')
SETTINGS connection_pool_size = 16, connection_max_tries = 3, connection_auto_close = 1 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :) SELECT * FROM mysql;
SELECT *
FROM mysql
Query id: 724bea04-d126-474b-b814-ab9162f41822
┌─name────┬─age─┐
│ rayslee │ 18 │
└─────────┴─────┘
1 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :) INSERT INTO mysql VALUES('lily', 19);
INSERT INTO mysql VALUES
Query id: 27d72eaa-4c10-461f-ace4-ffab589493a4
Ok.
1 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
2.3 Special
- Memory
- 内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。
- 读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过 10G/s)。
- 一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场景。
2.4 MergeTree
2.4.1 MergeTree
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]
cloud-mn01 :) SHOW CREATE TABLE t_order_mt;
SHOW CREATE TABLE t_order_mt
Query id: e8257846-ed21-40b8-854f-e91ecb6f5a02
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.t_order_mt
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.004 sec.
cloud-mn01 :)
- PARTITION BY
- 分区的目的主要是降低扫描的范围,优化查询速度;
- 分区后,面对涉及跨分区的查询统计,ClickHouse 会以 分区为单位并行处理。
- 数据写入与分区合并:任何一个批次的数据写入都会产生一个 临时分区,不会纳入任何一个已有的分区。写入
后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行 合并操作;
cloud-mn01 :) insert into t_order_mt values
:-] (101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
:-] (102,'sku_002',2000.00,'2020-06-01 11:00:00'),
:-] (102,'sku_004',2500.00,'2020-06-01 12:00:00'),
:-] (102,'sku_002',2000.00,'2020-06-01 13:00:00'),
:-] (102,'sku_002',12000.00,'2020-06-01 13:00:00'),
:-] (102,'sku_002',600.00,'2020-06-02 12:00:00');
INSERT INTO t_order_mt VALUES
Query id: 60cdb8e5-3f91-4a42-9d2c-14d93698b23e
Ok.
6 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: 96fb5d88-18a8-4bf5-89df-3e87cfaa301f
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
6 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :) insert into t_order_mt values
:-] (101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
:-] (102,'sku_002',2000.00,'2020-06-01 11:00:00'),
:-] (102,'sku_004',2500.00,'2020-06-01 12:00:00'),
:-] (102,'sku_002',2000.00,'2020-06-01 13:00:00'),
:-] (102,'sku_002',12000.00,'2020-06-01 13:00:00'),
:-] (102,'sku_002',600.00,'2020-06-02 12:00:00');
INSERT INTO t_order_mt VALUES
Query id: e58fb4bf-2d69-40e6-857e-d91b049a974d
Ok.
6 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: 98b097f3-489c-4cc7-81ff-d1fe77e21a50
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
12 rows in set. Elapsed: 0.004 sec.
cloud-mn01 :) optimize table t_order_mt final;
OPTIMIZE TABLE t_order_mt FINAL
Query id: 6c242f60-e096-4293-b936-9df17763ffb1
Ok.
0 rows in set. Elapsed: 0.005 sec.
cloud-mn01 :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: 670d8871-bec7-43d4-9141-1347602ed24a
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │
│ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │
│ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
│ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
12 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
# 例20200602_2_4_1 = PartitionId_MinBlockNum_MaxBlockNum_Level
# =》PartitionId
# 分区值
# =》MinBlockNum
# 最小分区块编号,自增类型,从1开始向上递增。每产生一个新的目录分区就向上递增一个数字。
# =》MaxBlockNum
# 最大分区块编号,新创建的分区MinBlockNum等于MaxBlockNum的编号。
# =》Level
# 合并的层级,被合并的次数。合并次数越多,层级值越大。
[root@cloud-mn01 t_order_mt]# pwd
/var/lib/clickhouse/data/default/t_order_mt
[root@cloud-mn01 t_order_mt]# ll
total 4
drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:32 20200601_1_1_0
drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:34 20200601_1_3_1
drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:33 20200601_3_3_0
drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:32 20200602_2_2_0
drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:34 20200602_2_4_1
drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:33 20200602_4_4_0
drwxr-x--- 2 clickhouse clickhouse 6 Aug 1 12:29 detached
-rw-r----- 1 clickhouse clickhouse 1 Aug 1 12:29 format_version.txt
[root@cloud-mn01 t_order_mt]#
- PRIMARY KEY
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。 这就意味着是可以存在相同 primary key 的数据的。
- index_granularity
- 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。
- ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
- 稀疏索引的好处就是可以 用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描。
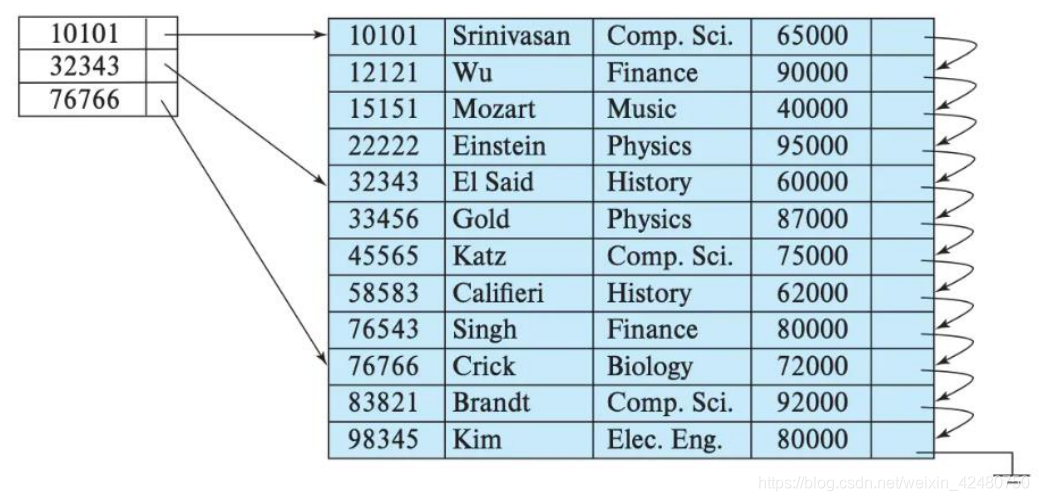
- ORDER BY
- order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
- order by 是 MergeTree 中唯一一个 必填项,甚至比 primary key 还重要,因为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理。
- 主键必须是 order by 字段的前缀字段。比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)。
- 二级索引
二级索引能够为非主键字段的查询发挥作用。
GRANULARITY N 是设定二级索引对于一级索引粒度的粒度,即 N * index_granularity 行生成一个索引。
cloud-mn01 :) SHOW CREATE TABLE t_order_mt2;
SHOW CREATE TABLE t_order_mt2
Query id: d23601cf-3f9a-44f6-bde1-51735d7c31a4
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.t_order_mt2
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime,
INDEX a total_amount TYPE minmax GRANULARITY 5
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- TTL
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能。
- 列级
# 创建时指定
CREATE TABLE example_table
(
d DateTime,
a Int TTL d + INTERVAL 1 MONTH,
b Int TTL d + INTERVAL 1 MONTH,
c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
# 创建后指定
ALTER TABLE example_table
MODIFY COLUMN
c String TTL d + INTERVAL 1 DAY;
- 表级
# 创建时指定
CREATE TABLE example_table
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH [DELETE],
d + INTERVAL 1 WEEK TO VOLUME 'aaa',
d + INTERVAL 2 WEEK TO DISK 'bbb';
# 创建后指定
ALTER TABLE example_table
MODIFY TTL d + INTERVAL 1 DAY;
2.4.2 ReplacingMergeTree
- 简介
- ReplacingMergeTree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是多了一个 分区去重 的功能。
- 数据的去重只会在 第一次批量插入 及 分区合并 的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。
- 如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。
- 使用
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
- ReplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的。
- 如果不填版本字段,默认按照插入顺序保留最后一条。
- 使用 order by 字段作为唯一键。
2.4.3 SummingMergeTree
分区 “预聚合” 的引擎 SummingMergeTree
create table t_order_smt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =SummingMergeTree(total_amount)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id );
- 以 SummingMergeTree()中指定的列作为汇总数据列
- 可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数据列
- 以 order by 的列为准,作为维度列
- 其他的列按插入顺序保留第一行
- 不在一个分区的数据不会被聚合
- 只有在同一批次插入(新版本)或分片合并时才会进行聚合
三、SQL 操作
- DDL 数据定义语言
- DCL 数据控制语言
- DML 数据操作语言
- DQL 数据查询语言
3.1 DML
- 简介
- ClickHouse 提供了 Delete 和 Update 的能力,这类操作被称为 Mutation 查询,它可以看做 Alter 的一种。
- 虽然可以实现修改和删除,但是和一般的 OLTP 数据库不一样,Mutation 语句是一种很“重”的操作,而且 不支持事务。
- “重”的原因主要是 每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。所以尽量做批量的变更,不要进行频繁小数据的操作。
- 由于操作比较“重”,所以 Mutation 语句分两步执行,同步执行的部分其实只是进行新增数据新增分区和并把旧分区打上逻辑上的失效标记。直到触发分区合并的时候,才会删除旧数据释放磁盘空间。
- 删除
alter table t_order_smt delete where sku_id =‘sku_001’;
- 更新
alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id = 102;
3.2 DQL
- Group By
GROUP BY 操作增加了 with rollup\with cube\with total 用来计算小计和总计。
cloud-mn01 :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: be6ba693-9ad0-45e9-9b05-9cb0aeba1213
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 105 │ sku_003 │ 600.00 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │
│ 101 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │
│ 103 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
│ 104 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │
│ 110 │ sku_003 │ 600.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 106 │ sku_001 │ 1000.00 │ 2020-06-04 12:00:00 │
│ 107 │ sku_002 │ 2000.00 │ 2020-06-04 12:00:00 │
│ 108 │ sku_004 │ 2500.00 │ 2020-06-04 12:00:00 │
│ 109 │ sku_002 │ 2000.00 │ 2020-06-04 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
10 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- with rollup:从右至左去掉维度进行小计
cloud-mn01 :) select id , sku_id,sum(total_amount) from t_order_mt group by
:-] id,sku_id with rollup;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH ROLLUP
Query id: a43fba98-5bcf-4bf2-96d1-cf2a41b2891d
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600.00 │
│ 109 │ sku_002 │ 2000.00 │
│ 107 │ sku_002 │ 2000.00 │
│ 106 │ sku_001 │ 1000.00 │
│ 104 │ sku_002 │ 2000.00 │
│ 101 │ sku_002 │ 2000.00 │
│ 103 │ sku_004 │ 2500.00 │
│ 108 │ sku_004 │ 2500.00 │
│ 105 │ sku_003 │ 600.00 │
│ 101 │ sku_001 │ 1000.00 │
└─────┴─────────┴───────────────────┘
┌──id─┬─sku_id─┬─sum(total_amount)─┐
│ 110 │ │ 600.00 │
│ 106 │ │ 1000.00 │
│ 105 │ │ 600.00 │
│ 109 │ │ 2000.00 │
│ 107 │ │ 2000.00 │
│ 104 │ │ 2000.00 │
│ 103 │ │ 2500.00 │
│ 108 │ │ 2500.00 │
│ 101 │ │ 3000.00 │
└─────┴────────┴───────────────────┘
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200.00 │
└────┴────────┴───────────────────┘
20 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- with cube : 从右至左去掉维度进行小计,再从左至右去掉维度进行小计
cloud-mn01 :) select id , sku_id,sum(total_amount) from t_order_mt group by
:-] id,sku_id with cube;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH CUBE
Query id: df7b72c9-5e06-4ddf-a8f1-5ad1e3e195ad
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600.00 │
│ 109 │ sku_002 │ 2000.00 │
│ 107 │ sku_002 │ 2000.00 │
│ 106 │ sku_001 │ 1000.00 │
│ 104 │ sku_002 │ 2000.00 │
│ 101 │ sku_002 │ 2000.00 │
│ 103 │ sku_004 │ 2500.00 │
│ 108 │ sku_004 │ 2500.00 │
│ 105 │ sku_003 │ 600.00 │
│ 101 │ sku_001 │ 1000.00 │
└─────┴─────────┴───────────────────┘
┌──id─┬─sku_id─┬─sum(total_amount)─┐
│ 110 │ │ 600.00 │
│ 106 │ │ 1000.00 │
│ 105 │ │ 600.00 │
│ 109 │ │ 2000.00 │
│ 107 │ │ 2000.00 │
│ 104 │ │ 2000.00 │
│ 103 │ │ 2500.00 │
│ 108 │ │ 2500.00 │
│ 101 │ │ 3000.00 │
└─────┴────────┴───────────────────┘
┌─id─┬─sku_id──┬─sum(total_amount)─┐
│ 0 │ sku_003 │ 1200.00 │
│ 0 │ sku_004 │ 5000.00 │
│ 0 │ sku_001 │ 2000.00 │
│ 0 │ sku_002 │ 8000.00 │
└────┴─────────┴───────────────────┘
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200.00 │
└────┴────────┴───────────────────┘
24 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
- with totals: 只计算合计
cloud-mn01 :) select id , sku_id,sum(total_amount) from t_order_mt group by
:-] id,sku_id with totals;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH TOTALS
Query id: 0e5d8a29-253e-4f5d-90a1-73c81122837f
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600.00 │
│ 109 │ sku_002 │ 2000.00 │
│ 107 │ sku_002 │ 2000.00 │
│ 106 │ sku_001 │ 1000.00 │
│ 104 │ sku_002 │ 2000.00 │
│ 101 │ sku_002 │ 2000.00 │
│ 103 │ sku_004 │ 2500.00 │
│ 108 │ sku_004 │ 2500.00 │
│ 105 │ sku_003 │ 600.00 │
│ 101 │ sku_001 │ 1000.00 │
└─────┴─────────┴───────────────────┘
Totals:
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200.00 │
└────┴────────┴───────────────────┘
10 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- 数据导出
clickhouse-client --query “select * from t_order_mt where create_time=‘2020-06-01 12:00:00’” --format CSVWithNames> /opt/module/data/rs1.csv
3.3 DDL
- 新增字段
alter table tableName add column newcolname String after col1;
- 修改字段
alter table tableName modify column newcolname String;
- 删除字段
alter table tableName drop column newcolname;
四、优化
4.1 建表优化
4.1.1 数据类型
- 时间字段
- 建表时能用数值型或日期时间型表示的字段就不要用字符串;
- 虽然 ClickHouse 底层将 DateTime 存储为时间戳 Long 类型,但不建议存储 Long 类型;
- DateTime 不需要经过函数转换处理,执行效率高、可读性好。
CREATE TABLE t_type2
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Int32
)
ENGINE = ReplacingMergeTree(create_time)
PARTITION BY toYYYYMMDD(toDate(create_time)) --需要转换一次,否则报错
PRIMARY KEY id
ORDER BY (id, sku_id)
- 空值
- Nullable 类型几乎总是会拖累性能,因为存储 Nullable 列时需要创建一个额外的文件来存储 NULL 的标记,并且 Nullable 列无法被索引;
- 除非极特殊情况,应直接使用字段默认值表示空,或者自行指定一个在业务中无意义的值;
CREATE TABLE t_null
(
`x` Int8,
`y` Nullable(Int8)
)
ENGINE = TinyLog
[root@cloud-mn01 t_null]# pwd
/var/lib/clickhouse/data/default/t_null
[root@cloud-mn01 t_null]#
[root@cloud-mn01 t_null]# ll
total 16
-rw-r----- 1 clickhouse clickhouse 91 Aug 10 09:21 sizes.json
-rw-r----- 1 clickhouse clickhouse 28 Aug 10 09:21 x.bin
-rw-r----- 1 clickhouse clickhouse 28 Aug 10 09:21 y.bin
-rw-r----- 1 clickhouse clickhouse 28 Aug 10 09:21 y.null.bin
[root@cloud-mn01 t_null]#
4.1.2 分区和索引
- 分区粒度根据业务特点决定,不宜过粗或过细,一般选择按天分区,也可以指定为 Tuple(),以单表一亿数据为例,分区大小控制在 10-30 个为最佳;
- 必须指定索引列,ClickHouse 中的索引列即排序列,通过 order by 指定,一般在查询条件中 经常被用来充当筛选条件的属性 被纳入进来;
- 可以是单一维度,也可以是组合维度的索引;通常需要满足 高级列在前、查询频率大的在前 原则;
- 还有 基数特别大的不适合做索引列,如用户表的 userid 字段;通常筛选后的数据满足在百万以内为最佳。
-- 官方 hits_v1
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
-- 官方 visits_v1
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
4.1.3 表参数
- Index_granularity 是用来控制索引粒度的,默认是 8192,如非必须不建议调整。
- 如果表中不是必须保留全量历史数据,建议指定 TTL(生存时间值);
4.1.4 写入和删除
- 原则
- 尽量不要执行单条或小批量删除和插入操作,这样会产生小分区文件,给后台Merge 任务带来巨大压力;
- 不要一次写入太多分区,或数据写入太快,数据写入太快会导致 Merge 速度跟不上而报错;
- 一般建议每秒钟发起 2-3 次写入操作,每次操作写入 2w~5w 条数据(依服务器性能而定)。
- 写入过快
-- 使用 WAL 预写日志,提高写入性能(in_memory_parts_enable_wal 默认为 true)。
1. Code: 252, e.displayText() = DB::Exception: Too many parts(304).
Merges are processing significantly slower than inserts
-- 在服务器内存充裕的情况下增加内存配额,一般通过 max_memory_usage 来实现
-- 在服务器内存不充裕的情况下,建议将超出部分内容分配到系统硬盘上,但会降低执行速度,一般通过
-- max_bytes_before_external_group_by、max_bytes_before_external_sort 参数来实现。
2. Code: 241, e.displayText() = DB::Exception: Memory limit (for query)
exceeded:would use 9.37 GiB (attempt to allocate chunk of 301989888
bytes), maximum: 9.31 GiB
4.1.5 常见配置
| 配置 | 描述 |
|---|---|
| background_pool_size | 后台线程池的大小,merge 线程就是在该线程池中执行,该线程池不仅仅是给 merge 线程用的,默认值 16,允许的前提下建议改成 cpu 个数的 2 倍(线程数)。 |
| background_schedule_pool_size | 执行后台任务(复制表、Kafka 流、DNS 缓存更新)的线程数。默认 128,建议改成 cpu 个数的 2 倍(线程数)。 |
| background_distributed_schedule_pool_size | 设置为分布式发送执行后台任务的线程数,默认 16,建议改成 cpu 个数的 2 倍(线程数)。 |
| max_concurrent_queries | 最大并发处理的请求数(包含 select,insert 等),默认值 100,推荐 150(不够再加)~300。 |
| max_threads | 设置单个查询所能使用的最大 cpu 个数,默认是 cpu 核数 |
| max_memory_usage | 此参数在 users.xml 中,表示单次 Query 占用内存最大值,该值可以设置的比较大,这样可以提升集群查询的上限。保留一点给 OS,比如 128G 内存的机器,设置为 100GB。 |
| max_bytes_before_external_group_by | 一般按照 max_memory_usage 的一半设置内存,当 group 使用内存超过阈值后会刷新到磁盘进行。因为 clickhouse 聚合分两个阶段:查询并及建立中间数据、合并中间数据,结合上一项,建议 50GB。 |
| max_bytes_before_external_sort | 当 order by 已使用 max_bytes_before_external_sort 内存就进行溢写磁盘(基于磁盘排序),如果不设置该值,那么当内存不够时直接抛错,设置了该值 order by 可以正常完成,但是速度相对存内存来说肯定要慢点(实测慢的非常多,无法接受)。 |
| max_table_size_to_drop | 此参数在 config.xml 中,应用于需要删除表或分区的情况,默认是50GB,意思是如果删除 50GB 以上的分区表会失败。建议修改为 0,这样不管多大的分区表都可以删除。 |
4.2 语法优化
4.2.1 EXPLAIN
- EXPLAIN
EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, …] SELECT … [FORMAT …]
- PLAN:用于查看执行计划,默认值。
1.1 header 打印计划中各个步骤的 head 说明,默认关闭,默认值 0;
1.2 description 打印计划中各个步骤的描述,默认开启,默认值 1;
1.3 actions 打印计划中各个步骤的详细信息,默认关闭,默认值 0。 - AST :用于查看语法树;
- SYNTAX:用于优化语法;
- PIPELINE:用于查看 PIPELINE 计划。
4.1 header 打印计划中各个步骤的 head 说明,默认关闭;
4.2 graph 用 DOT 图形语言描述管道图,默认关闭,需要查看相关的图形需要配合graphviz 查看;
4.3 actions 如果开启了 graph,紧凑打印打,默认开启。
EXPLAIN
SELECT number
FROM system.numbers
LIMIT 10
Query id: bbc68c47-0848-4219-ae39-ba0a744df1dd
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ Limit (preliminary LIMIT) │
│ ReadFromStorage (SystemNumbers) │
└───────────────────────────────────────────────────────────────────────────┘
EXPLAIN header = 1, actions = 1, description = 1
SELECT number
FROM system.numbers
LIMIT 10
Query id: 4d53ac26-5d3e-4217-9ee2-bd798413c1f6
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Header: number UInt64 │
│ Actions: INPUT :: 0 -> number UInt64 : 0 │
│ Positions: 0 │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ Header: number UInt64 │
│ Limit (preliminary LIMIT) │
│ Header: number UInt64 │
│ Limit 10 │
│ Offset 0 │
│ ReadFromStorage (SystemNumbers) │
│ Header: number UInt64 │
└───────────────────────────────────────────────────────────────────────────┘
- SYNTAX 语法优化
-- 需开启三元运算符优化
SET optimize_if_chain_to_multiif = 1;
EXPLAIN SYNTAX
SELECT if(number = 1, 'hello', if(number = 2, 'world', 'atguigu'))
FROM numbers(10)
Query id: d4bd3df8-6a70-4831-8c19-cdfc0ed9da25
┌─explain─────────────────────────────────────────────────────────────┐
│ SELECT multiIf(number = 1, 'hello', number = 2, 'world', 'atguigu') │
│ FROM numbers(10) │
└─────────────────────────────────────────────────────────────────────┘
4.2.2 优化规则
- 准备测试数据
[root@cloud-mn01 ~]# ll
total 1792572
-rw-r--r-- 1 root root 1271623680 Aug 10 09:58 hits_v1.tar
-rw-r--r-- 1 root root 563968000 Aug 10 09:58 visits_v1.tar
[root@cloud-mn01 ~]# tar -xf hits_v1.tar -C /var/lib/clickhouse # hits_v1 表有 130 多个字段,880 多万条数据
[root@cloud-mn01 ~]# tar -xf visits_v1.tar -C /var/lib/clickhouse # visits_v1 表有 180 多个字段,160 多万条数据
[root@cloud-mn01 ~]# systemctl restart clickhouse-server.service
[root@cloud-mn01 ~]#
- COUNT 优化
在调用 count 函数时,如果使用的是 count() 或者 count(*),且没有 where 条件,则会直接使用 system.tables 的 total_rows
cloud-mn01 :) EXPLAIN SELECT count()FROM datasets.hits_v1;
EXPLAIN
SELECT count()
FROM datasets.hits_v1
Query id: 6ac410cd-81f1-4d96-bd35-2d45bbfb276d
┌─explain──────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ MergingAggregated │
│ ReadFromPreparedSource (Optimized trivial count) │
└──────────────────────────────────────────────────────┘
3 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
如果 count 具体的列字段,则不会使用此项优化
cloud-mn01 :) EXPLAIN SELECT count(CounterID)FROM datasets.hits_v1;
EXPLAIN
SELECT count(CounterID)
FROM datasets.hits_v1
Query id: be5182bb-4808-4e8f-a395-1fedd1bdd0be
┌─explain───────────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromMergeTree │
└───────────────────────────────────────────────────────────────────────────────┘
5 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- 谓词下推
当 group by 有 having 子句,但是没有 with cube、with rollup 或者 with totals 修饰的时候,having 过滤会下推到 where 提前过滤。
EXPLAIN SYNTAX
SELECT UserID
FROM datasets.hits_v1
GROUP BY UserID
HAVING UserID = '8585742290196126178'
Query id: 1ecd2b6b-6a0d-400a-aca1-3e9eac0b7874
┌─explain──────────────────────────────┐
│ SELECT UserID │
│ FROM datasets.hits_v1 │
│ WHERE UserID = '8585742290196126178' │
│ GROUP BY UserID │
└──────────────────────────────────────┘
子查询也支持谓词下推
EXPLAIN SYNTAX
SELECT *
FROM
(
SELECT UserID
FROM datasets.visits_v1
)
WHERE UserID = '8585742290196126178'
Query id: 4cece210-36f7-45c3-95a3-acb75a72ad09
┌─explain──────────────────────────────────┐
│ SELECT UserID │
│ FROM │
│ ( │
│ SELECT UserID │
│ FROM datasets.visits_v1 │
│ WHERE UserID = '8585742290196126178' │
│ ) │
│ WHERE UserID = '8585742290196126178' │
└──────────────────────────────────────────┘
- 聚合计算外推
EXPLAIN SYNTAX
SELECT sum(UserID * 2)
FROM datasets.visits_v1
Query id: bf6d9094-9c2a-4c70-acc4-574dee713e9a
┌─explain─────────────────┐
│ SELECT sum(UserID) * 2 │
│ FROM datasets.visits_v1 │
└─────────────────────────┘
- 聚合函数消除
如果对聚合键,也就是 group by key 使用 min、max、any 聚合函数,则将函数消除
EXPLAIN SYNTAX
SELECT
sum(UserID * 2),
max(VisitID),
max(UserID)
FROM visits_v1
GROUP BY UserID
Query id: 88dc8579-e110-433b-bc52-46d90078b187
┌─explain──────────────┐
│ SELECT │
│ sum(UserID) * 2, │
│ max(VisitID), │
│ UserID │
│ FROM visits_v1 │
│ GROUP BY UserID │
└──────────────────────┘
- 标量替换
如果子查询只返回一行数据,在被引用的时候用标量替换
EXPLAIN SYNTAX
WITH (
SELECT sum(bytes)
FROM system.parts
WHERE active
) AS total_disk_usage
SELECT
(sum(bytes) / total_disk_usage) * 100 AS table_disk_usage,
table
FROM system.parts
GROUP BY table
ORDER BY table_disk_usage DESC
LIMIT 10
Query id: dd48033c-d21b-41f2-87f0-78f3c529dc6b
┌─explain─────────────────────────────────────────────────────────────────────────┐
│ WITH identity(CAST(0, 'UInt64')) AS total_disk_usage │
│ SELECT │
│ (sum(bytes_on_disk AS bytes) / total_disk_usage) * 100 AS table_disk_usage, │
│ table │
│ FROM system.parts │
│ GROUP BY table │
│ ORDER BY table_disk_usage DESC │
│ LIMIT 10 │
└─────────────────────────────────────────────────────────────────────────────────┘
- 三元运算优化
如果开启了 optimize_if_chain_to_multiif 参数,三元运算符会被替换成 multiIf 函数
EXPLAIN SYNTAX
SELECT if(number = 1, 'hello', if(number = 2, 'world', 'atguigu'))
FROM numbers(10)
SETTINGS optimize_if_chain_to_multiif = 1
Query id: e1cb685f-a2b9-4121-bd8e-374b0c76d735
┌─explain─────────────────────────────────────────────────────────────┐
│ SELECT multiIf(number = 1, 'hello', number = 2, 'world', 'atguigu') │
│ FROM numbers(10) │
│ SETTINGS optimize_if_chain_to_multiif = 1 │
└─────────────────────────────────────────────────────────────────────┘
4.3 查询优化
4.3.1 单表
- PreWhere
- Prewhere 和 where 语句的作用相同,用来过滤数据。
- 不同之处在于 prewhere 只支持 *MergeTree 族系列引擎的表,首先会读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取 select 声明的列字段来补全其余属性。
- 当查询列明显多于筛选列时使用 Prewhere 可十倍提升查询性能,Prewhere 会自动优化执行过滤阶段的数据读取方式,降低 io 操作。
- 某些场景需要手工指定 prewhere
4.1 使用常量表达式
4.2 使用默认值为 alias 类型的字段
4.3 包含了 arrayJOIN,globalIn,globalNotIn 或者 indexHint 的查询
4.4 select 查询的列字段和 where 的谓词相同
4.5 使用了主键字段
- 采样
采样修饰符只有在 MergeTree engine 表中才有效,且在创建表时需要指定采样策略。
CREATE TABLE datasets.hits_v1
(
`WatchID` UInt64,
`JavaEnable` UInt8,
...
`RequestTry` UInt8
)
ENGINE = MergeTree
...
SAMPLE BY intHash32(UserID)
...
SELECT
Title,
count(*) AS PageViews
FROM hits_v1
SAMPLE 0.1 -- 代表采样 10%的数据,也可以是具体的条数
WHERE CounterID = 57
GROUP BY Title
ORDER BY PageViews DESC
LIMIT 1000
Query id: 269e0b6b-4e78-4282-8e35-f5bdc73c69c3
┌─Title────────────────────────────────────────────────────────────────┬─PageViews─┐
│ │ 77 │
│ Фильмы онлайн на сегодня │ 6 │
│ Сбербанка «Работа, мебель обувь бензор.НЕТ « Новости, аксессионально │ 6 │
└──────────────────────────────────────────────────────────────────────┴───────────┘
- 去重
- uniqCombined 替代 distinct 性能可提升 10 倍以上;
- uniqCombined 底层采用类似 HyperLogLog 算法实现,存在 2% 左右的数据误差,可直接使用这种去重方式提升查询性能;
- Count(distinct )会使用 uniqExact精确去重;
- 不建议在千万级不同数据上执行 distinct 去重查询,改为近似去重 uniqCombined。
cloud-mn01 :) select count(distinct rand()) from hits_v1;
SELECT countDistinct(rand())
FROM hits_v1
Query id: 4c17ea01-14f6-4c83-9990-450bb30a2f59
┌─uniqExact(rand())─┐
│ 8864520 │
└───────────────────┘
1 rows in set. Elapsed: 0.483 sec. Processed 8.87 million rows, 80.31 MB (18.37 million rows/s., 166.26 MB/s.)
cloud-mn01 :) SELECT uniqCombined(rand()) from datasets.hits_v1 ;
SELECT uniqCombined(rand())
FROM datasets.hits_v1
Query id: 63912054-e9ed-47d1-a4db-1923a5c8f9c1
┌─uniqCombined(rand())─┐
│ 8878876 │
└──────────────────────┘
1 rows in set. Elapsed: 0.102 sec. Processed 8.87 million rows, 80.31 MB (86.86 million rows/s., 786.11 MB/s.)
cloud-mn01 :)
- 注意事项
- 查询熔断:为了避免因个别慢查询引起的服务雪崩的问题,除了可以为单个查询设置超时以外,还可以配置周期熔断,在一个查询周期内,如果用户频繁进行慢查询操作超出规定阈值后将无法继续进行查询操作。
- 关闭虚拟内存:物理内存和虚拟内存的数据交换,会导致查询变慢,资源允许的情况下关闭虚拟内存。
- 配置 join_use_nulls:为每一个账户添加 join_use_nulls 配置,左表中的一条记录在右表中不存在,右表的相应字段会返回该字段相应数据类型的默认值,而不是标准 SQL 中的 Null 值。
- 批量写入时先排序:批量写入数据时,必须控制每个批次的数据中涉及到的分区的数量,在写入之前最好对需要导入的数据进行排序。无序的数据或者涉及的分区太多,会导致 ClickHouse 无法及时对新导入的数据进行合并,从而影响查询性能。
- 关注 CPU:cpu 一般在 50%左右会出现查询波动,达到 70%会出现大范围的查询超时,cpu 是最关键的指标,要非常关注。
4.3.2 多表
- 用 IN 代替 JOIN:当多表联查时,查询的数据仅从其中一张表出时,可考虑用 IN 操作而不是 JOIN;
- 大小表 JOIN:多表 join 时要满足小表在右的原则,右表关联时被加载到内存中与左表进行比较;
- 注意谓词下推:ClickHouse 在 join 查询时不会主动发起谓词下推的操作,需要每个子查询提前完成过滤操作;
- 分布式表使用 GLOBAL:两张分布式表上的 IN 和 JOIN 之前必须加上 GLOBAL 关键字,右表只会在接收查询请求的那个节点查询一次,并将其分发到其他节点上。如果不加 GLOBAL 关键字的话,每个节点都会单独发起一次对右表的查询,而右表又是分布式表,就导致右表一共会被查询 N²次(N是该分布式表的分片数量),这就是查询放大,会带来很大开销。
五、高级
5.1 数据一致性
ReplacingMergeTree、SummingMergeTree 只是保证最终一致性,更新表数据后的一段时间会出现短暂数据不一致的情况。
- 环境准备
-- user_id 是数据去重更新的标识;
-- create_time 是版本号字段,每组数据中 create_time 最大的一行表示最新的数据;
-- deleted 是自定的一个标记位,比如 0 代表未删除,1 代表删除数据。
CREATE TABLE test_a
(
`user_id` UInt64,
`score` String,
`deleted` UInt8 DEFAULT 0,
`create_time` DateTime DEFAULT toDateTime(0)
)
ENGINE = ReplacingMergeTree(create_time)
ORDER BY user_id
INSERT INTO test_a (user_id, score) WITH (
SELECT ['A', 'B', 'C', 'D', 'E', 'F', 'G']
) AS dict
SELECT
number AS user_id,
dict[(number % 7) + 1]
FROM numbers(100000)
- 通过 FINAL 去重
在查询语句后增加 FINAL 修饰符,这样在查询的过程中将会执行 Merge 的特殊逻辑(例如数据去重,预聚合等)。
-- 更新数据
INSERT INTO test_a (user_id, score, create_time) WITH (
SELECT ['AA', 'BB', 'CC', 'DD', 'EE', 'FF', 'GG']
) AS dict
SELECT
number AS user_id,
dict[(number % 7) + 1],
now() AS create_time
FROM numbers(5000)
-- 普通查询
SELECT COUNT()
FROM test_a
WHERE user_id < 5000
┌─count()─┐
│ 10000 │
└─────────┘
-- 通过 FINAL 查询
SELECT COUNT()
FROM test_a
FINAL
WHERE user_id < 5000
┌─count()─┐
│ 5000 │
└─────────┘
- 通过 GROUP BY 去重
-- argMax(field1,field2):按照 field2 的最大值取 field1 的值。
-- 当我们更新数据时,会写入一行新的数据,例如上面语句中,通过查询最大的create_time 得到修改后的 score 字段值。
SELECT
user_id ,
argMax(score, create_time) AS score,
argMax(deleted, create_time) AS deleted,
max(create_time) AS ctime
FROM test_a
GROUP BY user_id
HAVING deleted = 0;
-- 创建视图,方便测试
CREATE VIEW view_test_a AS
SELECT
user_id,
argMax(score, create_time) AS score,
argMax(deleted, create_time) AS deleted,
max(create_time) AS ctime
FROM test_a
GROUP BY user_id
HAVING deleted = 0
-- 更新数据
INSERT INTO test_a (user_id, score, create_time) VALUES
-- 查询视图,去重
SELECT *
FROM view_test_a
WHERE user_id = 0
Query id: a11e2648-cba4-4fde-9e95-3a6896f0adca
┌─user_id─┬─score─┬─deleted─┬───────────────ctime─┐
│ 0 │ AAAA │ 0 │ 2021-08-10 11:17:49 │
└─────────┴───────┴─────────┴─────────────────────┘
-- 查询原表,所有记录都在
SELECT *
FROM test_a
WHERE user_id = 0
Query id: 55af213a-f8b7-4238-8456-bc5df1b62562
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ AAAA │ 0 │ 2021-08-10 11:17:49 │
└─────────┴───────┴─────────┴─────────────────────┘
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ A │ 0 │ 1970-01-01 08:00:00 │
└─────────┴───────┴─────────┴─────────────────────┘
-- 删除数据
INSERT INTO test_a (user_id, score, deleted, create_time) VALUES
-- 查询视图,记录消失
SELECT *
FROM view_test_a
WHERE user_id = 0
Query id: c6157128-84ac-4e86-92a9-68aad99b539d
Ok.
0 rows in set. Elapsed: 0.006 sec. Processed 8.19 thousand rows, 188.47 KB (1.47 million rows/s., 33.80 MB/s.)
-- 查询原表,数据都在
SELECT *
FROM test_a
WHERE user_id = 0
Query id: 482cbcdb-f2d1-45b4-ba05-7153c0e0a6ef
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ AAAA │ 0 │ 2021-08-10 11:17:49 │
└─────────┴───────┴─────────┴─────────────────────┘
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ AAAA │ 1 │ 2021-08-10 11:19:10 │
└─────────┴───────┴─────────┴─────────────────────┘
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ A │ 0 │ 1970-01-01 08:00:00 │
└─────────┴───────┴─────────┴─────────────────────┘
5.2 物化视图
- 简介
- 普通视图不保存数据,保存的仅仅是查询语句,而ClickHouse 的物化视图是一种 查询结果的持久化;
- 用户查起来跟表没有区别,它就是一张表,它也像是一张 时刻在预计算的表;
- 优点:查询速度快;
- 缺点:它的本质是一个流式数据的使用场景,是累加式的技术,不太适用于对历史数据进行去重分析;如果一张表加了好多物化视图,在写这张表的时候,就会消耗很多机器的资源。
- 语法
也是 create 语法,会创建一个隐藏的目标表来保存视图数据。也可以 TO 表名,保存到
一张显式的表。没有加 TO 表名,表名默认就是 .inner.物化视图名
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name]
[ENGINE = engine] [POPULATE] AS SELECT ...
- 必须指定物化视图的 engine 用于数据存储;
- TO [db].[table]语法的时候,不得使用 POPULATE;
- POPULATE 关键字决定了物化视图的 更新策略:+ 对历史数据进行查询,- 仅应用于新插入的数据;
- 物化视图 不支持同步删除,若源表的数据不存在(删除了)则物化视图的数据仍然保留。
- 演示
-- 创建原始表
CREATE TABLE hits_test
(
`EventDate` Date,
`CounterID` UInt32,
`UserID` UInt64,
`URL` String,
`Income` UInt8
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192
-- 插入数据
INSERT INTO hits_test SELECT
EventDate,
CounterID,
UserID,
URL,
Income
FROM datasets.hits_v1
LIMIT 10000
-- 创建物化视图
CREATE MATERIALIZED VIEW hits_mv
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(EventDate)
ORDER BY (EventDate, intHash32(UserID)) AS
SELECT
UserID,
EventDate,
count(URL) AS ClickCount,
sum(Income) AS IncomeSum
FROM hits_test
WHERE EventDate >= '2014-03-20'
GROUP BY
UserID,
EventDate
-- 查看生成的 inner 表
SHOW TABLES
┌─name───────────────────────────────────────────┐
│ .inner_id.069f7d89-bd86-4ae6-869f-7d89bd86fae6 │
│ hits_mv │
│ hits_test │
└────────────────────────────────────────────────┘
-- 导入增量数据
INSERT INTO hits_test SELECT
EventDate,
CounterID,
UserID,
URL,
Income
FROM datasets.hits_v1
WHERE EventDate >= '2014-03-23'
LIMIT 10
-- 查询物化视图
SELECT *
FROM hits_mv
Query id: 9af4d8b2-7e9d-48d1-b950-a923e95a047c
┌──────────────UserID─┬──EventDate─┬─ClickCount─┬─IncomeSum─┐
│ 8585742290196126178 │ 2014-03-23 │ 8 │ 16 │
│ 1095363898647626948 │ 2014-03-23 │ 2 │ 0 │
└─────────────────────┴────────────┴────────────┴───────────┘
2 rows in set. Elapsed: 0.002 sec.
5.3 MaterializeMySQL 引擎
- 简介
- MaterializeMySQL 的 database 引擎能 映射到 MySQL 中的某个 database,并自动在 ClickHouse 中创建对应的 ReplacingMergeTree;
- ClickHouse 服务做为 MySQL 副本,读取 Binlog 并执行 DDL 和 DML 请求,实现了基于 MySQL Binlog 机制的业务数据库 实时同步 功能;
- MaterializeMySQL 同时支持 全量和增量 同步,在 database 创建之初会全量同步 MySQL 中的表和数据,之后则会通过 binlog 进行增量同步;
- MaterializeMySQL database 为其所创建的每张 ReplacingMergeTree 自动增加了 _sign 和 _version 字段;
- ClickHouse 数据库表会自动将 MySQL 主键和索引子句转换为 ORDER BY 元组。
- _sign + _version
_version 用作版本参数,每当监听到 insert、update 和 delete 事件时,在 databse 内全局自增;而 _sign 则用于标记是否被删除,取值 1 或者 -1。
- MYSQL_WRITE_ROWS_EVENT: _sign = 1,_version ++
- MYSQL_DELETE_ROWS_EVENT: _sign = -1,_version ++
- MYSQL_UPDATE_ROWS_EVENT: 新数据 _sign = 1,_version ++
- MYSQL_QUERY_EVENT: 支持 CREATE TABLE 、DROP TABLE 、RENAME TABLE 等。
- MySQL 配置
需开启 binlog 和 GTID 模式
[root@cloud-dn02 ~]# cat /etc/my.cnf
[mysqld]
user=root
basedir=/opt/module/mysql
datadir=/opt/module/mysql/data
socket=/tmp/mysql.sock
port=3306
# 确保 MySQL 开启了 binlog 功能,且格式为 ROW
server_id=6
log-bin=mysql-bin
binlog_format=ROW
# 开启 GTID 模式, 这种方式在 mysql 主从模式下可以确保数据同步的一致性(主从切换时)。
gtid-mode=on
enforce-gtid-consistency=1
log-slave-updates=1
# the MaterializeMySQL engine requires default_authentication_plugin='mysql_native_password'.
default_authentication_plugin=mysql_native_password
[mysql]
socket=/tmp/mysql.sock
[root@cloud-dn02 ~]#
- 展示
- 创建 MySQL 表及插入数据
CREATE DATABASE testck;
CREATE TABLE `testck`.`t_organization` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` int NOT NULL,
`name` text DEFAULT NULL,
`updatetime` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY (`code`)
) ENGINE=InnoDB;
INSERT INTO testck.t_organization (code, name,updatetime) VALUES(1000,'Realinsight',NOW());
INSERT INTO testck.t_organization (code, name,updatetime) VALUES(1001, 'Realindex',NOW());
INSERT INTO testck.t_organization (code, name,updatetime) VALUES(1002,'EDT',NOW());
CREATE TABLE `testck`.`t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` int,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
INSERT INTO testck.t_user (code) VALUES(1);
- 创建 ClickHouse 同步数据库
SET allow_experimental_database_materialize_mysql = 1
CREATE DATABASE test_binlog
ENGINE = MaterializeMySQL('cloud-dn02:3306', 'testck', 'rayslee', 'abcd1234..')
# 注意使用 root 用户可能存在未知错误:Code: 100. DB::Exception: Received from localhost:9000. DB::Exception: Access denied for user root.
cloud-mn01 :) show tables;
SHOW TABLES
Query id: 95891aee-ffbc-4b0c-abc1-881266785c86
┌─name───────────┐
│ t_organization │
│ t_user │
└────────────────┘
2 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :) select * from t_user;
SELECT *
FROM t_user
Query id: 9fa08f8a-4cd3-4c85-a71d-e3a92237caa8
┌─id─┬─code─┐
│ 1 │ 1 │
└────┴──────┘
1 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :) select * from t_organization;
SELECT *
FROM t_organization
Query id: eb1662db-101e-4132-aa7c-0326099ed084
┌─id─┬─code─┬─name────────┬──────────updatetime─┐
│ 1 │ 1000 │ Realinsight │ 2021-08-11 11:22:34 │
│ 2 │ 1001 │ Realindex │ 2021-08-11 11:22:34 │
│ 3 │ 1002 │ EDT │ 2021-08-11 11:22:34 │
└────┴──────┴─────────────┴─────────────────────┘
3 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
5.4 集群监控
- 安装监控
- 安装 prometheus
[root@cloud-mn01 ~]# tar -zxf /opt/soft/prometheus-2.26.0.linux-amd64.tar.gz -C /opt/module/
[root@cloud-mn01 ~]# ln -s /opt/module/prometheus-2.26.0.linux-amd64 /opt/module/prometheus
[root@cloud-mn01 ~]# vi /opt/module/prometheus/prometheus.yml
[root@cloud-mn01 ~]# tail /opt/module/prometheus/prometheus.yml
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# 添加 clickhouse 监控
- job_name: 'clickhouse'
static_configs:
- targets: ['cloud-mn01:9363']
[root@cloud-mn01 ~]# nohup /opt/module/prometheus/prometheus --config.file=/opt/module/prometheus/prometheus.yml &>> /var/log/prometheus.log &
[1] 1683
[root@cloud-mn01 ~]#
http://192.168.1.101:9090/targets
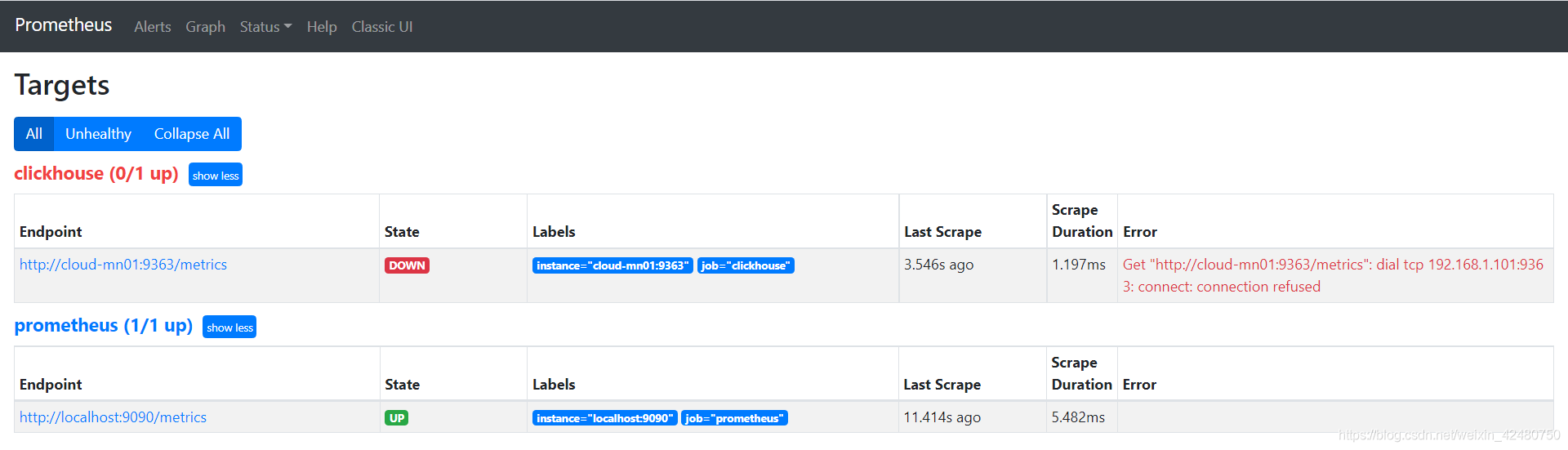
- 安装 grafana
[root@cloud-mn01 ~]# tar -zxf /opt/soft/grafana-7.5.2.linux-amd64.tar.gz -C /opt/module/
[root@cloud-mn01 ~]# ln -s /opt/module/grafana-7.5.2 /opt/module/grafana
[root@cloud-mn01 ~]# cd /opt/module/grafana
# 注意:必须进到 Grafana 家目录执行
[root@cloud-mn01 grafana]# nohup ./bin/grafana-server web &>> /var/log/grafana-server.log &
[2] 1748
[root@cloud-mn01 grafana]#
http://192.168.1.101:3000/ 默认用户名密码 admin/admin
- Clickhouse 适配
[root@cloud-mn01 ~]# vim /etc/clickhouse-server/config.xml
# 打开外部访问
<listen_host>::</listen_host>
# 打开监控指标
<prometheus>
<endpoint>/metrics</endpoint>
<port>9363</port>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
<status_info>true</status_info>
</prometheus>
[root@cloud-mn01 ~]# systemctl restart clickhouse-server.service
[root@cloud-mn01 ~]#
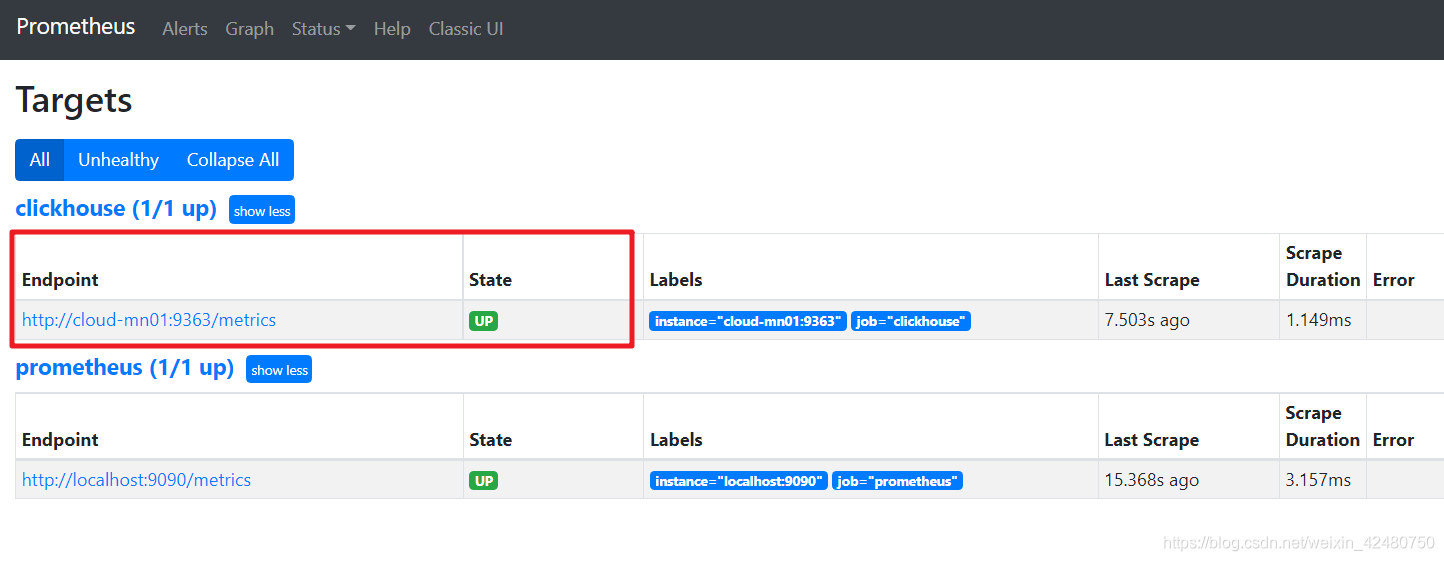
- 添加监控
- 添加数据源
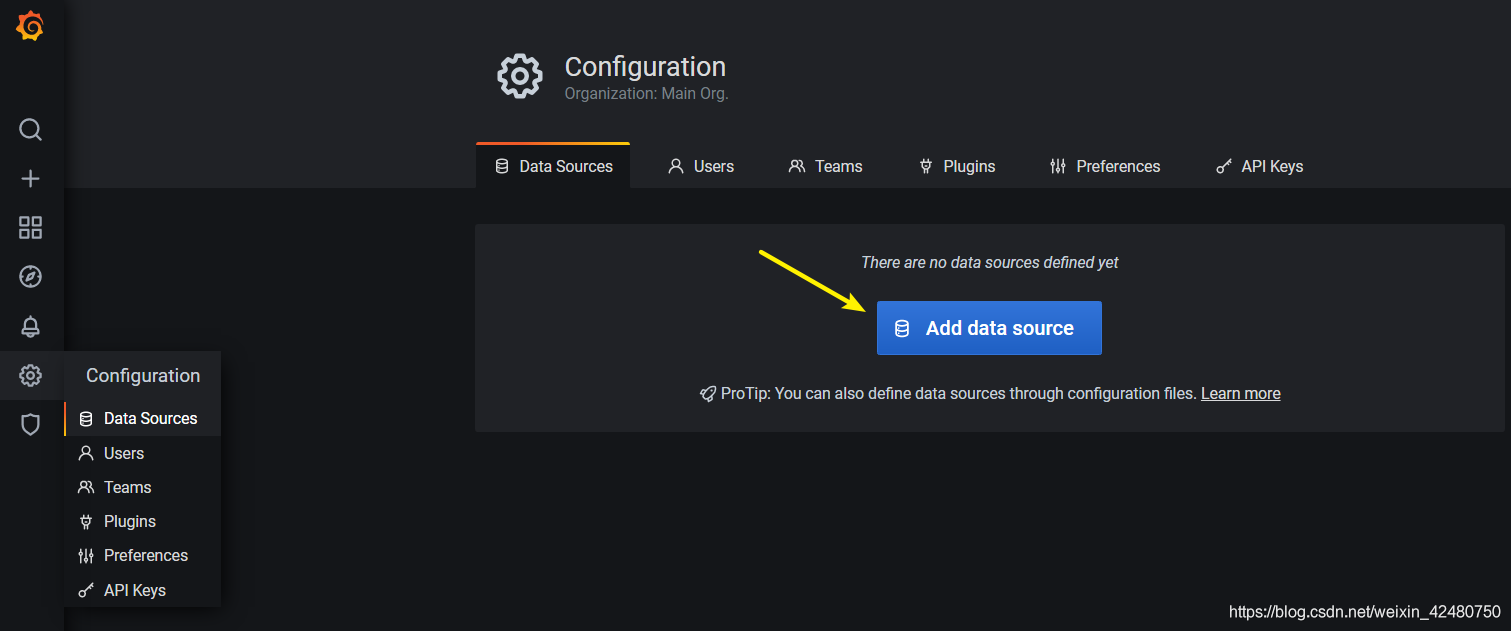
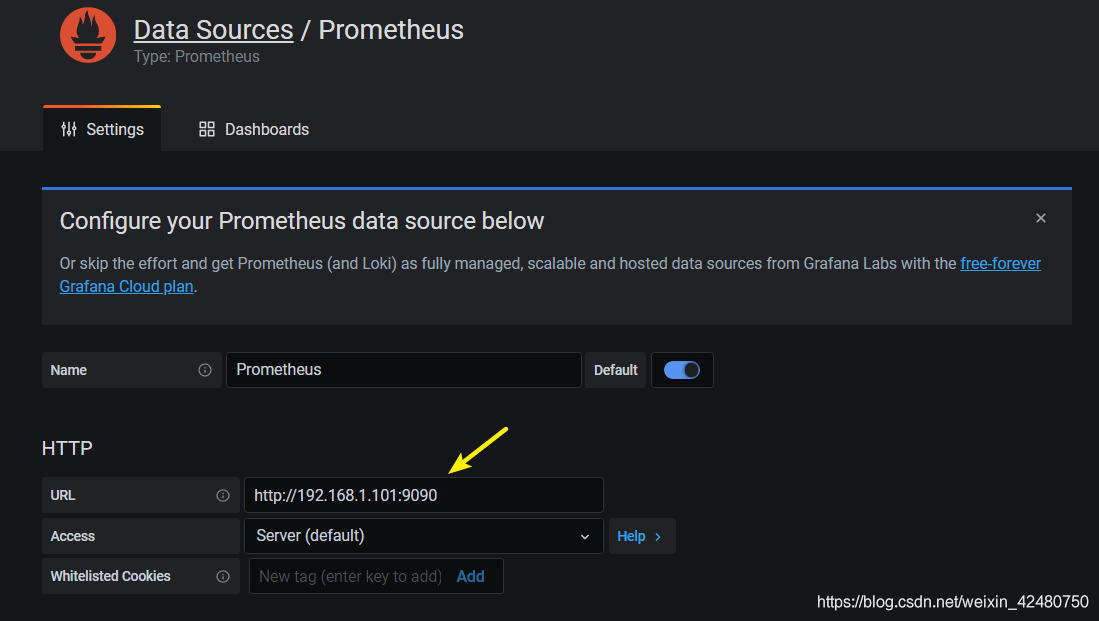
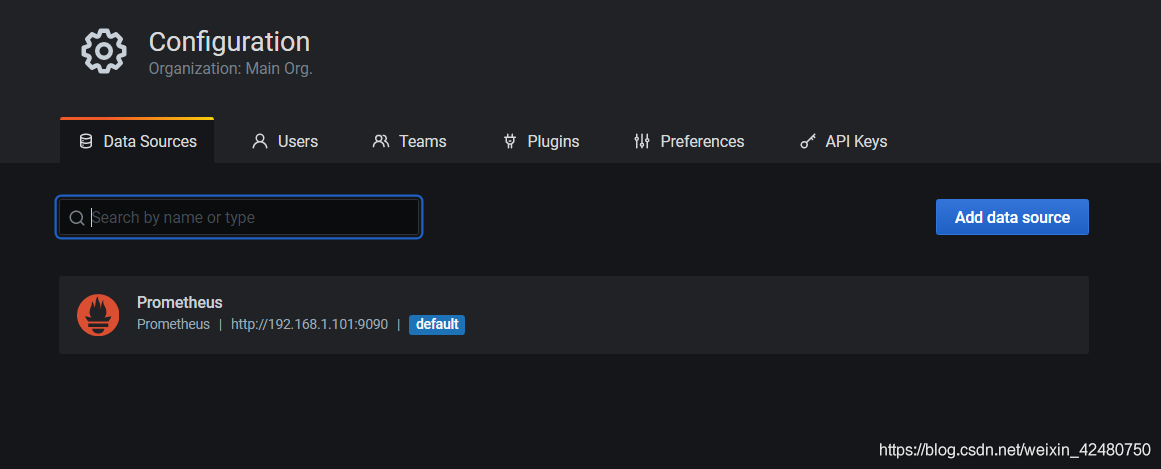
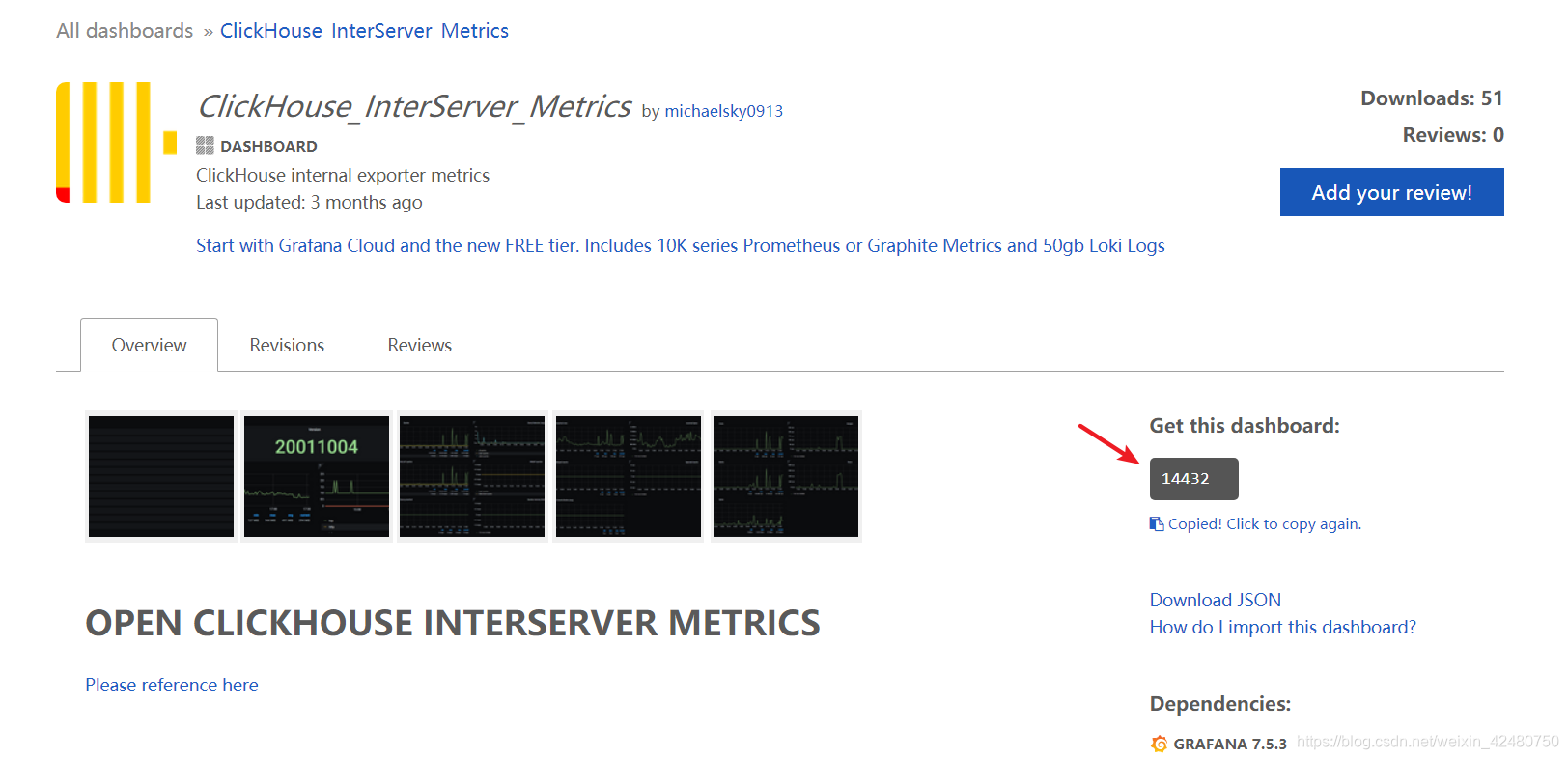
- 选择监控指标模板
https://grafana.com/grafana/dashboards/14432
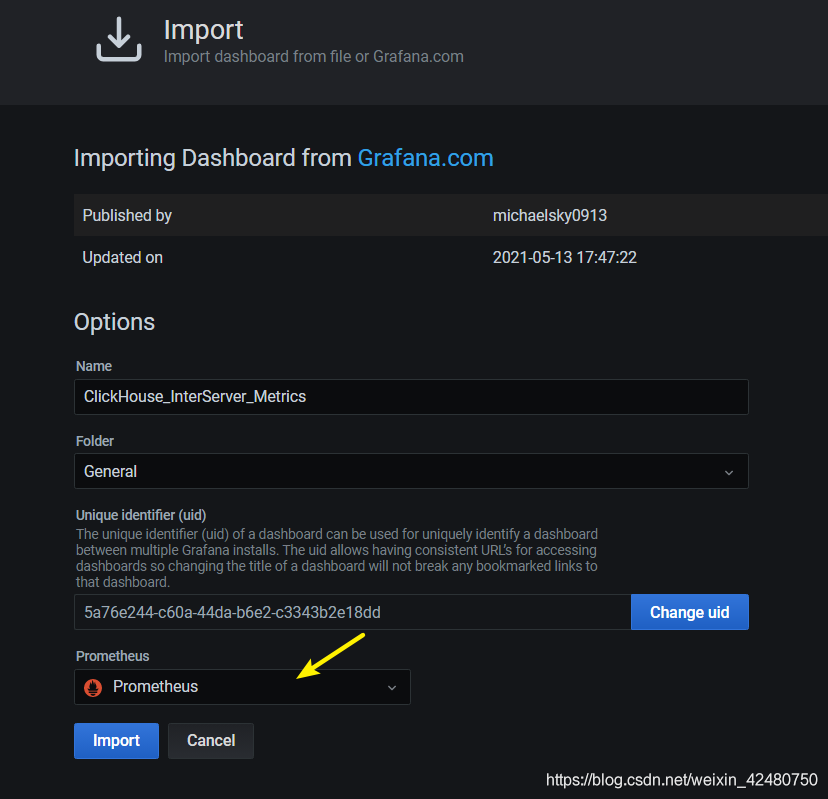
- 导入模板
‘+’ =》 Import
- 查看监控效果
5.5 备份恢复
https://github.com/AlexAkulov/clickhouse-backup/releases/tag/v1.0.0
## 该工具目前暂时存在版本兼容性问题(clickhouse 最新版 7 月份发布,该工具最新 6 月份发布)
[root@cloud-mn01 soft]# rpm -ivh clickhouse-backup-1.0.0-1.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:clickhouse-backup-1.0.0-1 ################################# [100%]
[root@cloud-mn01 soft]# cd /etc/clickhouse-backup/
[root@cloud-mn01 clickhouse-backup]# ll
total 4
-rw-r--r-- 1 root root 1682 Jun 17 00:49 config.yml.example
[root@cloud-mn01 clickhouse-backup]#

















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









