







 超级会员免费看
超级会员免费看
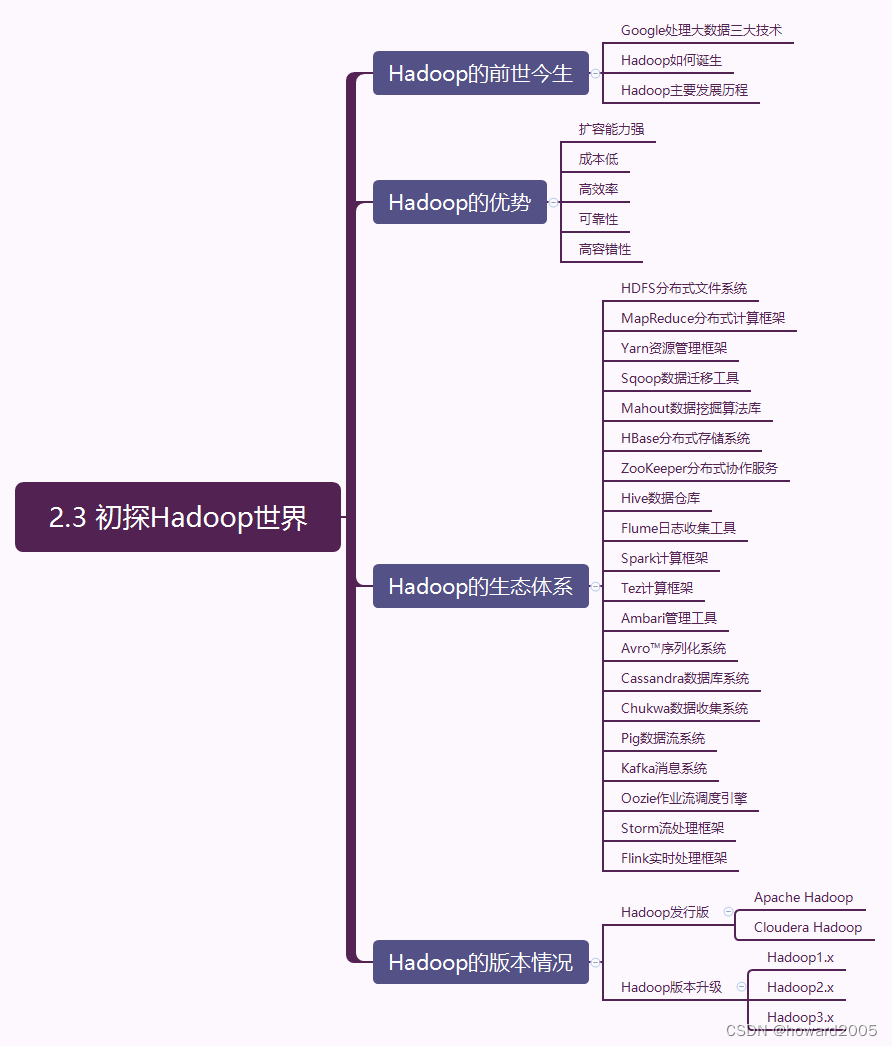
 本文详细介绍了Hadoop的起源、主要发展历程、优势以及庞大的生态系统,涵盖了从HDFS、MapReduce到Yarn、HBase等多个组件。Hadoop以其强大的扩容能力、低成本、高效率和高容错性,成为了大数据处理的关键工具,其生态体系包括数据存储、计算框架、资源管理等多个方面,如Sqoop、Mahout、Hive、Spark等。文章还概述了Hadoop的不同版本及其发行版,帮助读者深入理解Hadoop在大数据领域的重要地位。
本文详细介绍了Hadoop的起源、主要发展历程、优势以及庞大的生态系统,涵盖了从HDFS、MapReduce到Yarn、HBase等多个组件。Hadoop以其强大的扩容能力、低成本、高效率和高容错性,成为了大数据处理的关键工具,其生态体系包括数据存储、计算框架、资源管理等多个方面,如Sqoop、Mahout、Hive、Spark等。文章还概述了Hadoop的不同版本及其发行版,帮助读者深入理解Hadoop在大数据领域的重要地位。
文章目录
- 零、学习目标
- 一、导入新课
- 二、新课讲解
-
- (一)Hadoop的前世今生
- (二)Hadoop的优势
- (三)Hadoop的生态体系
-
- 1、HDFS分布式文件系统
- 2、MapReduce分布式计算框架
- 3、Yarn资源管理框架
- 4、Sqoop数据迁移工具
- 5、Mahout数据挖掘算法库
- 6、HBase分布式存储系统
- 7、ZooKeeper分布式协作服务
- 8、Hive数据仓库
- 9、Flume日志收集工具
- 10、Spark内存计算框架
- 11、Tez计算框架
- 12、Ambari管理工具
- 13、Avro™序列化系统
- 14、Cassandra数据库系统
- 15、Chukwa数据收集系统
- 16、Pig数据流系统
- 17、Kafka消息系统
- 18、Oozie作业流调度引擎
- 19、Storm流处理框架
- 20、Flink实时处理框架
- 21、Apache Phoenix
- 22、Apache Drill
- 23、Apache Hudi
- 24、Apache Kylin
- 25、Apache Presto
- 26、ClickHouse
- 27、Apache Druid
- 28、TensorFlow
- 29、PyTorch
- 30、Apache Superset
- 31、Elasticsearch
- 32、Jupyter Notebook
- 33、Apache Zeppelin
- (四)Hadoop的版本情况
- 三、归纳总结
- 四、上机操作
零、学习目标
- 了解Hadoop的发展历史
- 了解Hadoop的版本情况
- 掌握Hadoop的生态体系
一、导入新课
- 上次课,主要讲解了大数据的应用场景,大数据应用在各个行业。Hadoop作为一个能够对大量数据进行分布式处理的框架,用户可以利用Hadoop开发和处理海量数据。本次课将针对Hadoop的基本概念、优势与生态体系进行详细讲解。
二、新课讲解
(一)Hadoop的前世今生
1、Google处理大数据三大技术
- 大数据技术首先需要解决的问题是如何高效、安全地存储;其次是如何高效、及时地处理海量的数据,并返回有价值的信息;最后是如何通过机器学习算法,从海量数据中挖掘出潜在的价值,并构建模型,以用于预测预警。
- 随着数据

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2302
2302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











