







一、 支持任务类型
Azkaban内置的任务类型支持command、java
command实际是执行shell脚本,所以支持性很高。
二、 单一job案例
需求:编写时间脚本,每隔一分钟将时间输入到指定文本date.txt
- 编写job
# 必须以job为结尾
vi p1.job
type=command
command=sh p1.sh
- 编写脚本
vi p1.sh
date >> /opt/soft/data/date.txt
- 打包
必须将文件打包成为zip包,zip包含job运行所需的所有文件
如没有zip命令,使用yum -y install zip unizp安装
[root@jzy opt]# zip p1.zip p1.job p1.sh
- 创建project

- 上传打好的zip包

-
执行
点击Execute Flow

点击Schedule调度执行

如下所示,可以设置执行频率

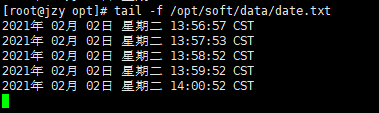
- 查看执行结果

时间每隔一分钟定向输出到指定文件
三、 多任务工作流程配置
需求,执行四个job,流程为执行完1,执行2和3,执行4,如下图所示

- 编写job
first.job
[root@jzy opt]# vi first.job
type=command
command=echo 'first'
second.job
[root@jzy opt]# vi second.job
type=command
command=echo 'second'
dependencies=first
third.job
[root@jzy opt]# vi third.job
type=command
command=echo 'third'
dependencies=first
fourth.job
[root@jzy opt]# vi fourth.job
type=command
command=echo 'fourth'
dependencies=second,third
打包
[root@jzy opt]# zip lots.zip first.job second.job third.job fourth.job
-
创建任务并上传(与单任务相同)
-
此时可以查看个job之间的依赖关系,如下所示,点击执行

时间关系也可以提现先后执行顺序,如下所示

四、 执行spark程序
需求:读取mysql当中的表并写入本地指定路径
简单程序如下
import org.apache.spark.sql.SparkSession
object readTry {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("azkaban_test")
// .master("local[*]")
.getOrCreate()
val mysql_maps: Map[String, String] = Map[String,String](
"driver" -> "com.mysql.jdbc.Driver",
"url" -> "jdbc:mysql://192.168.56.20:3306/mytest",
"user" -> "root",
"password" -> "1234",
"dbtable" -> "temperatures"
)
spark.read.format("jdbc").options(mysql_maps).load().show()
.write.save("file:///opt/temperatures")
}
}
建好需要写入的文件路径
spark_read.job
type=command
command=/opt/soft/spark/spark-2.4.0-bin-hadoop2.6/bin/spark-submit \
--class com.risen.mytry.readTry \
--master spark://192.168.56.20:7077 \
spark_data_transfer-1.0-SNAPSHOT.jar
将打成jar包的程序和job一起打包成zip,上传至azkaban并运行
报错Installation Failed. Error chunking
有时候jar包注入依赖环境导致文件很大,上传zip失败,报错Installation Failed. Error chunking
在mysql当中,执行如下命令,并重新启动server即可
set global max_allowed_packet=1073741824;















 6757
6757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









