







1.动量梯度下降法(Gradient descent with Momentum)
基本的想法:运行速度几乎总是快于标准的梯度下降算法,简而言之,就是计算梯度的指数加权平均数,并利用该梯度更新你的权重

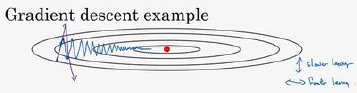
例如,在上几个导数中,你会发现这些纵轴上的摆动平均值接近于零,所以在纵轴方向,你希望放慢一点,平均过程中,正负数相互抵消,所以平均值接近于零。但在横轴方向,所有的微分都指向横轴方向,因此横轴方向的平均值仍然较大,因此用算法几次迭代后,你发现动量梯度下降法,最终纵轴方向的摆动变小了,横轴方向运动更快,因此你的算法走了一条更加直接的路径,在抵达最小值的路上减少了摆动
2.RMSprop(均方根)
RMSProp算法的全称叫 Root Mean Square Prop,是Geoffrey E. Hinton在Coursera课程中提出的一种优化算法,在上面的Momentum优化算法中,虽然初步解决了优化中摆动幅度大的问题。所谓的摆动幅度就是在优化中经过更新之后参数的变化范围,如下图所示,蓝色的为Momentum优化算法所走的路线,绿色的为RMSProp优化算法所走的路线。

为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对权重 WW 和偏置 bb 的梯度使用了微分平方加权平均数。
其中,假设在第 tt 轮迭代过程中,各个公式如下所示:
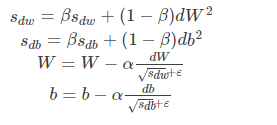

3.Adam 优化算法(Adam optimization algorithm)
有了上面两种优化算法,一种可以使用类似于物理中的动量来累积梯度,另一种可以使得收敛速度更快同时使得波动的幅度更小。那么讲两种算法结合起来所取得的表现一定会更好。Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用的一种算法,我们所使用的参数基本和上面讲的一致,在训练的最开始我们需要初始化梯度的累积量和平方累积量。

本算法中有很多超参数,超参数学习率𝑎很重要,也经常需要调试,你可以尝试一系列值,然后看哪个有效。𝛽1常用的缺省值为0.9,这是 dW 的移动平均数,也就是𝑑𝑊的加权平均数,这是Momentum 涉及的项。至于超参数𝛽2,Adam 论文作者,也就是Adam 算法的发明者,推荐使用 0.999,这是在计算(𝑑𝑊)2以及(𝑑𝑏)2的移动加权平均值,关于𝜀的选择其实没那么重要,Adam 论文的作者建议𝜀为10−8,但你并不需要设置它,因为它并不会影响算法表现。但是在使用 Adam 的时候,人们往往使用缺省值即可,𝛽1,𝛽2和𝜀都是如此,我觉得没人会去调整𝜀,然后尝试不同的𝑎值,看看哪个效果最好。你也可以调整𝛽1和𝛽2,但我认识的业内人士很少这么干。
为什么这个算法叫做 Adam,Adam 代表的是 Adaptive Moment Estimation,𝛽1用于计算这个微分(𝑑𝑊),叫做第一矩,𝛽2用来计算平方数的指数加权平均数((𝑑𝑊)2),叫做第二矩,所以Adam 的名字由此而来,但是大家都简称 Adam 权威算法。















 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









