







简介:本项目旨在指导学习者使用Python和PyTorch框架构建和训练深度学习模型。PyTorch因其灵活性和效率被广泛应用于学术研究和工业界,尤其在深度学习领域。项目内容包括理解深度学习概念、探索PyTorch核心组件、定义神经网络架构、以及训练和评估模型的完整流程。通过这个项目,学习者可以亲身体验从理论到实践的过程,深入理解神经网络和PyTorch的工作原理。 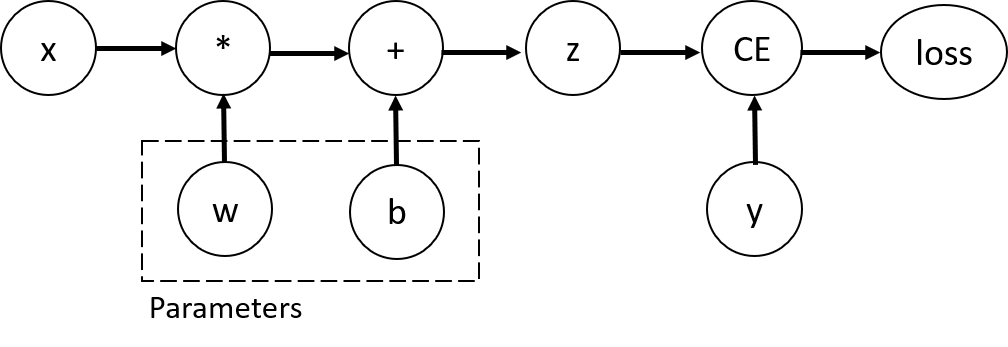
1. PyTorch框架和基础概念
PyTorch是目前最流行的深度学习框架之一,它以动态计算图著称,使得构建复杂神经网络模型变得更为简单直观。本章我们将揭开PyTorch的神秘面纱,介绍其核心组件以及基础概念,帮助读者快速入门深度学习的实践旅程。
1.1 PyTorch的安装与配置
在开始使用PyTorch之前,我们首先需要确保系统中安装了正确版本的PyTorch。推荐使用Conda进行安装,因为它能很好地管理Python环境和依赖包。
# 安装命令适用于Linux系统
conda install pytorch torchvision torchaudio -c pytorch
安装完成后,可以通过Python的交互式环境检查安装情况:
import torch
print(torch.__version__)
1.2 PyTorch的模块构成
PyTorch主要由以下几个核心模块构成:
-
torch:提供各种张量操作,基础的数学运算和线性代数操作。 -
torch.nn:包含构建神经网络所需的各种模块和损失函数。 -
torch.optim:提供常用的优化算法,如SGD和Adam等。 -
torch.utils.data:包含数据加载和预处理的工具,如DataLoader。
通过熟悉这些模块,开发者可以快速搭建和训练深度学习模型。
1.3 理解张量(Tensor)
张量是PyTorch中用于表示多维数组的数据结构,类似于NumPy中的ndarray。不同的是,张量不仅可以在CPU上操作,还可以在GPU上进行加速计算,极大地提高了大规模数据处理的效率。
# 创建一个3x3的随机张量
tensor = torch.randn(3, 3)
print(tensor)
在后续的章节中,我们会深入探讨Tensor的使用方法,以及它在神经网络中的关键作用。
2. 神经网络基础介绍
2.1 神经网络的基本组成
神经网络是深度学习模型的基本构成元素,其基本组成可以简单地分为神经元和连接权重,以及激活函数。
2.1.1 神经元和激活函数
神经元是神经网络中的基本单位,可以看作是一个简单的函数,它接收一组输入信号并产生一个输出信号。在数学上,我们可以认为神经元实现了加权求和的操作,并将结果传递给一个激活函数。常见的激活函数包括Sigmoid、Tanh和ReLU等。Sigmoid函数可以将输入压缩到0和1之间,而ReLU函数则在输入为正时直接输出该值,在输入为负时输出0。激活函数的选择对网络的学习能力和模型的性能有着直接的影响。
import torch
import torch.nn as nn
# Sigmoid激活函数
def sigmoid(x):
return 1 / (1 + torch.exp(-x))
# ReLU激活函数
def relu(x):
return torch.maximum(torch.tensor(0.0), x)
# 创建一个输入Tensor
input_tensor = torch.tensor([1.0, -2.0, 3.0])
# 应用激活函数
output_sigmoid = sigmoid(input_tensor)
output_relu = relu(input_tensor)
print("Sigmoid Activated Output:", output_sigmoid)
print("ReLU Activated Output:", output_relu)
2.1.2 权重和偏置的作用
在神经网络中,权重和偏置是每个神经元与其它神经元连接的强度表示。权重决定了输入信号对当前神经元输出的影响程度。一个正权重会使得相同的输入信号产生更大的正输出,反之,负权重会使得输入信号产生负的输出。偏置则为神经元提供了一个基准点,即使在输入信号为零时,也能让神经元产生一个非零的输出。权重和偏置的初始化和更新是神经网络训练中的关键过程,关系到模型能否有效地学习数据的内在规律。
# 创建一个带有权重和偏置的简单线性模型
linear_model = nn.Linear(in_features=3, out_features=1, bias=True)
# 初始化权重和偏置
initial_weights = linear_model.weight.data
initial_bias = linear_model.bias.data
print("Initial Weights:", initial_weights)
print("Initial Bias:", initial_bias)
2.2 神经网络的学习方式
神经网络通过学习数据的特征来改善其性能。这种学习主要是通过数据在神经网络中的传递过程来实现的。
2.2.1 前向传播与反向传播
前向传播是神经网络从输入层到输出层的信号传递过程。在此过程中,输入数据经过各层处理,最终产生一个输出。反向传播则是前向传播的逆过程,其目的是为了计算输出错误对应于各个神经元权重的梯度,从而可以利用梯度下降算法对权重进行更新,以减少模型预测误差。
# 简单的前向传播函数
def forward_propagation(x, weights, bias):
return x @ weights.T + bias
# 随机生成输入数据和权重
x = torch.randn(1, 3)
weights = torch.randn(3, 1)
bias = torch.randn(1)
# 执行前向传播
output = forward_propagation(x, weights, bias)
print("Output of Forward Propagation:", output)
2.2.2 损失函数的选取与意义
损失函数用来衡量模型预测值与真实值之间的差异。一个常用的损失函数是均方误差(MSE),它衡量的是预测值和真实值之间的平方差。损失函数越小,表示模型的预测越准确。在神经网络训练过程中,通过最小化损失函数来更新权重和偏置,从而达到改善模型性能的目的。
# 定义均方误差损失函数
def mse_loss(y_true, y_pred):
return torch.mean((y_true - y_pred) ** 2)
# 假设真实值为 y_true
y_true = torch.tensor([1.0])
# 预测值 y_pred
y_pred = output
# 计算损失
loss = mse_loss(y_true, y_pred)
print("Loss with initial weights:", loss)
在第二章中,我们介绍了神经网络的基础组成和学习方式。本章节内容为神经网络概念的初步探索,为后续章节关于构建神经网络、训练过程以及优化提供了理论基础。接下来,我们将继续深入探讨如何在PyTorch框架中处理数据和自动计算梯度。
3. 使用Tensor和Autograd进行数据处理和梯度计算
PyTorch是一个强大的深度学习库,它在数据处理和自动梯度计算方面提供了丰富的工具和功能。在本章节中,我们将深入了解如何使用Tensor和Autograd进行高效的数据处理以及如何进行梯度计算,这是构建和训练神经网络不可或缺的两个方面。
3.1 PyTorch中的Tensor对象
3.1.1 Tensor的基本操作和属性
Tensor在PyTorch中是存储多维数组的基本数据结构,类似于NumPy的ndarray,但Tensor可以利用GPU进行计算加速。Tensor的操作和属性是构建深度学习模型的基础。
import torch
# 创建一个5x3的Tensor,未初始化
x = torch.empty(5, 3)
print(x)
# 创建一个随机初始化的Tensor
y = torch.rand(5, 3)
print(y)
# 创建一个需要梯度计算的Tensor
w = torch.tensor([1.5, -2.3, 5.7], requires_grad=True)
print(w)
在上述代码中,我们创建了三种不同类型的Tensor:一个空的Tensor,一个随机初始化的Tensor以及一个标记为需要梯度的Tensor。 requires_grad=True 标志允许后续计算中自动梯度的追踪。
3.1.2 Tensor与NumPy的相互转换
Tensor与NumPy数组之间可以轻松转换,这对于数据预处理和与其他库(比如SciPy)集成非常有用。
import numpy as np
# Tensor转NumPy数组
x_np = x.numpy()
print(x_np)
# NumPy数组转Tensor
y_torch = torch.from_numpy(y.numpy())
print(y_torch)
这样的转换对于利用NumPy强大的数据处理能力,以及在Tensor之间转换数据类型等场景非常有用。
3.2 Autograd机制的理解与应用
3.2.1 计算图的建立与执行
Autograd是PyTorch的核心功能之一,它能够自动计算梯度。在PyTorch中,每个操作都会创建一个计算图节点,这个图能够追踪操作的历史。
# 开启梯度计算
with torch.enable_grad():
a = torch.randn(2, 2, requires_grad=True)
b = torch.randn(2, 2, requires_grad=True)
c = a + b
d = c * 2
e = d.mean()
print(e)
在这段代码中, e 是一个单一值(标量), torch.enable_grad() 上下文管理器确保 a 、 b 、 c 、 d 的梯度计算被追踪。
3.2.2 梯度自动计算的原理
通过反向传播,PyTorch自动计算梯度并更新模型参数。
# 反向传播计算梯度
e.backward()
print(a.grad)
print(b.grad)
当我们调用 .backward() 方法时,会根据计算图反向传播,计算每个变量对最终损失的梯度。 a.grad 和 b.grad 将分别包含 a 和 b 对最终损失的梯度。这对于理解模型参数如何影响输出至关重要。
在本章中,我们深入了PyTorch的两个核心组件:Tensor和Autograd。我们了解了Tensor对象的创建、操作和属性,以及如何将Tensor转换为NumPy数组。此外,还学习了Autograd机制的工作原理和如何使用它来执行梯度计算。在接下来的章节中,我们将进一步探索如何构建和训练简单的神经网络结构。
4. 构建简单神经网络结构
4.1 神经网络层的定义
在构建神经网络时,我们需要定义网络中的各种层,这些层是构成网络结构的基本单元。在PyTorch中,我们通常使用 torch.nn 模块中的类来定义这些层。网络层可以分为线性层(全连接层)和非线性层(激活函数等)。定义层时,还需要考虑参数初始化方法,以确保网络从一个良好的起点开始学习。
4.1.1 线性层和非线性层的使用
线性层是最基础的神经网络层类型,它根据给定的权重和偏置,对输入数据进行线性变换。在PyTorch中,线性层可以使用 nn.Linear 类来实现。非线性层则是添加网络中非线性因素的关键,最常见的非线性层包括ReLU、Sigmoid和Tanh等激活函数,它们通过 nn.ReLU 、 nn.Sigmoid 和 nn.Tanh 等类在PyTorch中实现。
import torch
import torch.nn as nn
# 定义一个简单的两层全连接网络
class SimpleNetwork(nn.Module):
def __init__(self):
super(SimpleNetwork, self).__init__()
self.fc1 = nn.Linear(in_features=10, out_features=20) # 第一个全连接层,输入10个特征,输出20个特征
self.relu = nn.ReLU() # 添加ReLU激活函数
self.fc2 = nn.Linear(in_features=20, out_features=1) # 第二个全连接层,输入20个特征,输出1个特征
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 实例化模型
model = SimpleNetwork()
4.1.2 参数初始化方法
在模型训练之前,正确地初始化参数是非常重要的。参数初始化不当会导致训练过程中出现各种问题,如梯度消失或梯度爆炸。PyTorch提供了多种参数初始化方法,可以通过 torch.nn.init 模块来使用,或者在定义层时直接指定初始化方式。
# 使用不同方法初始化线性层的权重和偏置
def initialize_parameters(m):
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.1) # 高斯分布初始化权重
nn.init.constant_(m.bias, val=0) # 偏置初始化为0
# 将初始化函数应用到模型中
model.apply(initialize_parameters)
4.2 神经网络的组合与构建
构建复杂的神经网络需要多个层的组合。理解如何有效地组合层,以及如何设计网络结构,是构建深度学习模型的关键部分。
4.2.1 多层网络的实现
多层网络是指网络中包含多个隐藏层的结构。每一层的输出成为下一层的输入,这种结构能够捕捉数据中的复杂特征。构建多层网络时,需要考虑每层的输入输出维度,确保数据流动的正确性。
class MultiLayerNetwork(nn.Module):
def __init__(self):
super(MultiLayerNetwork, self).__init__()
self.fc1 = nn.Linear(in_features=784, out_features=128)
self.fc2 = nn.Linear(in_features=128, out_features=64)
self.fc3 = nn.Linear(in_features=64, out_features=10)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 784) # Flatten the input image
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
# 实例化模型
model = MultiLayerNetwork()
4.2.2 网络结构的设计原则
设计神经网络时,需要遵循一些基本的设计原则,以确保模型的性能和泛化能力。其中包括:
- 网络深度和宽度的选择:网络不宜过深也不宜过浅,过深可能导致梯度消失,过浅可能导致网络无法学习到复杂特征。
- 参数量和计算量的平衡:增加层数或每层的神经元数量会增加参数量,可能导致模型过拟合,需要通过正则化等技术来平衡。
- 使用现代架构技巧:如批量归一化(batch normalization),残差连接(residual connections)等,有助于提升模型训练效率。
在构建网络时,需要结合具体问题和数据集的特点,灵活应用这些原则,构建出适合问题的网络结构。
5. PyTorch中nn.Module的使用
5.1 nn.Module的层级结构
5.1.1 自定义模块的创建和组织
在PyTorch中, nn.Module 是构建神经网络的基石,所有的神经网络模块都是它的子类。要使用 nn.Module ,首先需要理解如何自定义一个模块,并进行组织。自定义模块通常包含以下几个部分:
-
__init__方法:用于初始化模块的参数和子模块。 -
forward方法:定义模块的前向传播过程。
下面是一个简单的例子,创建一个自定义的线性网络模块:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
在这个例子中,我们定义了一个包含一个全连接层( fc1 )、一个激活函数( relu )和另一个全连接层( fc2 )的简单网络结构。 forward 方法定义了数据如何通过网络流动。
5.1.2 序列化和反序列化的操作
序列化(Serialization)是将对象状态转换为可以存储或传输的格式的过程。PyTorch支持 torch.save 和 torch.load 两个函数来进行模型的序列化和反序列化操作。
下面的代码展示了如何将一个模型保存到磁盘,并随后重新加载该模型:
# 假设我们已经有了一个SimpleNet的实例simple_net
# 保存模型参数
torch.save(simple_net.state_dict(), 'simple_net.pth')
# 加载模型参数
model = SimpleNet(input_size=10, hidden_size=20, num_classes=3)
model.load_state_dict(torch.load('simple_net.pth'))
在序列化时,我们通常保存 state_dict ,这是一个从参数名称映射到参数张量的字典对象。使用 load_state_dict 方法,我们可以将保存的参数加载到新的模型实例中。
5.2 神经网络模块的高级特性
5.2.1 模块的参数和缓冲区
nn.Module 对象提供了 parameters() 和 buffers() 方法,这些方法返回模块的参数和缓冲区的迭代器。参数和缓冲区是模型可学习的元素,它们在训练过程中会更新。
# 获取模型的所有参数
parameters = list(simple_net.parameters())
# 获取模型的所有缓冲区
buffers = list(simple_net.buffers())
缓冲区通常用于如batch normalization层的running mean和running variance这样的元素,它们也会在训练过程中更新,但不是模型的参数。
5.2.2 模块的子类化和接口定义
自定义 nn.Module 时,可以对已有的模块进行子类化来创建新的模块。通过子类化可以扩展模块的功能或改变其行为。一个简单的例子是对一个已有的模块添加一个新的方法:
class ExtendedNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(ExtendedNet, self).__init__()
self.base = SimpleNet(input_size, hidden_size, num_classes)
def forward(self, x):
# 使用base模块的前向传播
out = self.base(x)
# 增加一些额外的处理
out = F.softmax(out, dim=1)
return out
在上面的代码中, ExtendedNet 继承自 SimpleNet ,我们可以直接使用 SimpleNet 的 forward 方法,并在此基础上增加一些操作,比如在这我们增加了一个softmax操作来增强模型的输出层。
通过子类化和接口定义,可以创建更加复杂和功能丰富的神经网络结构。同时,这也提供了极大的灵活性,使得开发者可以根据自己的需求定制和修改现有的网络模块。
6. 训练神经网络的步骤和过程
在深度学习项目中,训练神经网络是关键步骤,它需要谨慎而有计划地进行。本章将详细介绍如何进行数据的加载、预处理、网络的训练以及后续的优化操作。
6.1 数据加载和预处理
6.1.1 数据加载器DataLoader的使用
PyTorch提供了 DataLoader 类,它能够将数据打包成批次,并对数据进行洗牌(shuffle),实现多线程加载等功能。以下是使用 DataLoader 的一个基本示例:
from torch.utils.data import DataLoader, TensorDataset
# 假设我们已经有了输入数据input_tensor和目标数据target_tensor
input_tensor = torch.randn(100, 3, 32, 32) # 示例数据
target_tensor = torch.randint(low=0, high=10, size=(100,)) # 示例标签
# 将数据集包装成TensorDataset对象
dataset = TensorDataset(input_tensor, target_tensor)
# 使用DataLoader加载数据,设定batch_size和shuffle参数
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 通过DataLoader迭代数据
for batch_idx, (data, target) in enumerate(dataloader):
# 在这里进行网络训练操作
pass
6.1.2 数据增强和标准化的方法
数据预处理对模型的性能有显著影响。数据增强(Data Augmentation)通过随机变换来扩大训练集,增加模型对新数据的泛化能力。标准化(Normalization)则帮助模型处理输入数据的尺度问题,使其更加稳定。
以下是使用 transforms 模块实现数据增强和标准化的示例:
from torchvision import transforms
from torchvision.datasets import CIFAR10
# 定义数据增强和标准化的组合操作
transform_pipeline = ***pose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomCrop(32, 4), # 随机裁剪
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化
])
# 应用到数据集
train_dataset = CIFAR10(root='data/', train=True, download=True, transform=transform_pipeline)
6.2 网络训练的实践操作
6.2.1 训练循环的编写与优化
编写训练循环是神经网络训练的基本环节。以下代码段演示了如何编写一个训练循环,并且添加了一些基本的优化措施:
def train(model, dataloader, loss_fn, optimizer):
model.train() # 将模型设置为训练模式
for epoch in range(num_epochs): # 遍历训练集
for batch_idx, (data, target) in enumerate(dataloader):
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播
loss = loss_fn(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新权重
# 记录训练过程中的关键指标
if batch_idx % log_interval == 0:
print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(dataloader.dataset)} ({100. * batch_idx / len(dataloader):.0f}%)]\tLoss: {loss.item():.6f}")
6.2.2 损失函数和优化器的选择
在训练神经网络时,损失函数和优化器的选择至关重要。损失函数衡量的是模型输出与真实值之间的差异,而优化器则负责更新模型的参数以最小化损失函数。
以下为损失函数和优化器选择的示例:
from torch import nn
from torch.optim import Adam
# 使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
# 使用Adam优化器,学习率设为0.001
optimizer = Adam(model.parameters(), lr=0.001)
# 现在可以将这些组件应用到我们的训练循环中
在这一章节中,我们深入了解了数据加载、预处理以及神经网络的训练循环的编写和优化。通过使用PyTorch框架内的工具和优化实践,可以使我们对网络训练过程中的每一个细节都有所掌握,为后续的模型评估与优化打下了坚实的基础。在下一章中,我们将探讨如何划分数据集,以及如何评估和优化训练好的模型。
简介:本项目旨在指导学习者使用Python和PyTorch框架构建和训练深度学习模型。PyTorch因其灵活性和效率被广泛应用于学术研究和工业界,尤其在深度学习领域。项目内容包括理解深度学习概念、探索PyTorch核心组件、定义神经网络架构、以及训练和评估模型的完整流程。通过这个项目,学习者可以亲身体验从理论到实践的过程,深入理解神经网络和PyTorch的工作原理。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









