







单一数字评估指标(Single number evaluation metric)
无论你是调整超参数,或者是尝试不同的学习算法,或者在搭建机器学习系统时尝试不同手段,你会发现,如果你有一个单实数评估指标,你的进展会快得多,它可以快速告诉你,新尝试的手段比之前的手段好还是差。
所以当团队开始进行机器学习项目时,我经常推荐他们为问题设置一个单实数评估指标。
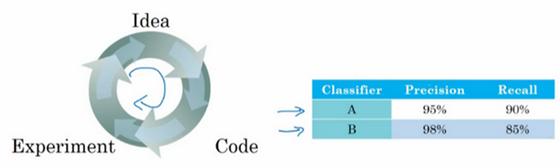
我们来看一个例子,你之前听过我说过,应用机器学习是一个非常经验性的过程,我们通常有一个想法,编程序,跑实验,看看效果如何,然后使用这些实验结果来改善你的想法,然后继续走这个循环,不断改进你的算法。
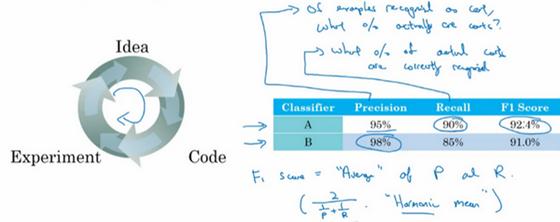
比如说对于你的猫分类器,之前你搭建了某个分类器A,通过改变超参数,还有改变训练集等手段,你现在训练出来了一个新的分类器B,所以评估你的分类器的一个合理方式是观察它的查准率(precision,也叫准确率)和查全率(recall 也叫召回率)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3431
3431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









