






概率图模型
概率图模型中,样本由公式G=(V,E)建模表示:
其中V表示节点,即随机变量,E表示边,即概率依赖关系。
概率图模型可以分为两种:有向图和无向图。
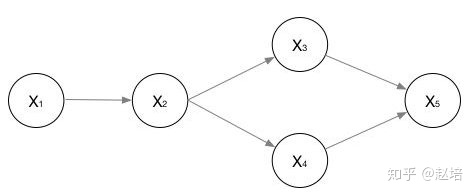
有向图
有向图联合概率为:
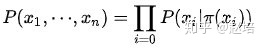
无向图
无向图求联合概率需要用到因式分解,即有若干个最大团(最大团中的结点相互联通)的乘积组成。
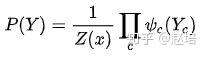
c表示最大团的个数,对每个最大团求其势函数,并累乘。Z(x)是规范化因子,这个怎么计算的呀?
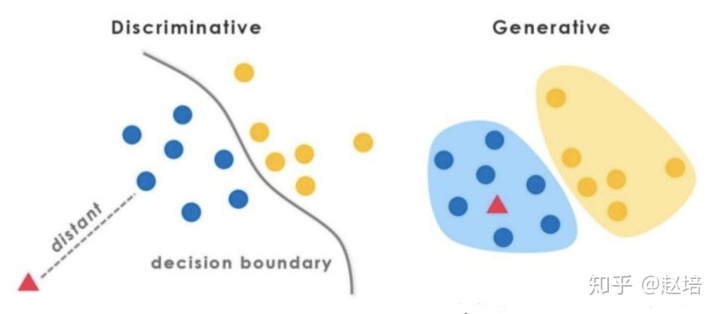
生成模型与判别模型区别
判别模型直接对P(Y|X)建模,就是根据X所提供的特征找到一个复杂的映射关系,与y进行映射。
- 对 P(Y|X) 建模
- 对所有的样本只构建一个模型,确认总体判别边界
- 观测到输入什么特征,就预测最可能的label
- 另外,判别式的优点是:对数据量要求没生成式的严格,速度也会快,小数据量下准确率也会好些。
生成模型学习到的是X与Y的联合模型P(X, Y), 在训练过程中只对P(X, Y)建模
1.对 P(X, Y) 建模
2.学习的是整体的分布,没有什么判别边界。
3.生成式模型的优点在于,所包含的信息非常齐全,整个数据集的分布都可以学到。
4、特点:生成式模型需要非常充足的数据量以保证采样到了数据本来的面目,所以速度相比之下,慢。
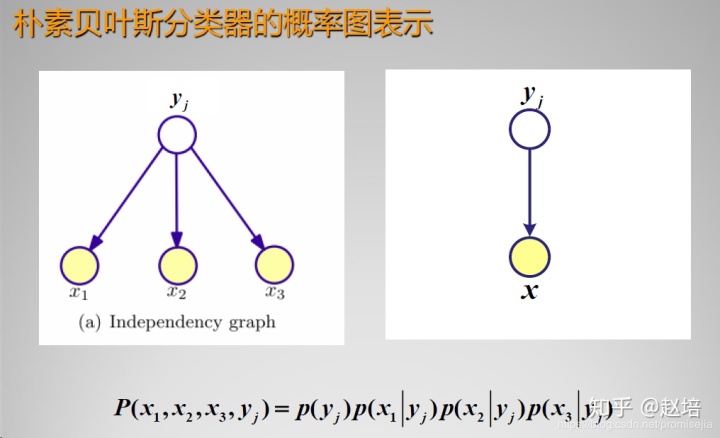
代表:Naive Bayes(朴素贝叶斯):P(X|Y) = P(X1) P(X2) ... P(Xn)
朴素贝叶斯概率图模型
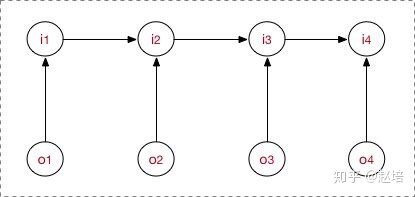
隐马尔可夫模型
定义
隐马尔可夫是关于时序的概率模型。描述有一个隐藏的马尔可夫链随机生成不可观测的状态随机序列(状态序列),再由各个状态生成一个观测从而产生观测随机序列(观测序列)。
隐马尔可夫模型由初始概率分布、状态转移概率分布以及观测概率分布确定。
隐马尔可夫模型满足:
1、齐次一阶马尔可夫假设:一阶马科夫指在t时刻的状态只依赖于前一时刻的状态,与其他时刻的状态和 观测无关,齐次是说任意相邻两个相邻时刻之间转移的概率分布是一致的。
2、观测独立假设:即任意时刻的观测值依赖于该时刻的状态,给定某时刻状态后,该时刻的观测值与其他时刻的观测值是相互独立的。
模型运行过程
1、学习训练过程:HMM训练过程,就是找出数据的分布情况,也就是模型参数的确定。主要就是根据观测结果,估计参数,使得观测序列概率最大。
方式:
监督学习方法:数据中既包含状态序列也包含观测序列,可以使用极大似然估计。
其本质就是基于统计的方式统计每种状态转移以及发射概率,还有初始概率。
非监督方式:采用EM方式,先求期望,在期望函数确定下求最大值下的参数,用这个参数更新。
2、序列解码(标注):学习完参数后,也就确定了一个HMM模型,这个模型是对这一批全部数据进行训练得到的参数。
解码问题就是根据观测序列找到一条隐状态序列,条件是这个隐状态序列的概率最大。本质就是有向图求最大路径问题,用维特比算法,基于动态规划方式跟新每个时刻下的所有状态的最大概率。
3、序列概率过程 :给定模型参数,也就是确定完模型,输出每个观测序列的概率,P(O| r)。方法有前向算法、后向算法。
最大熵马尔可夫模型(MEMM)
MEMM是判别模型。
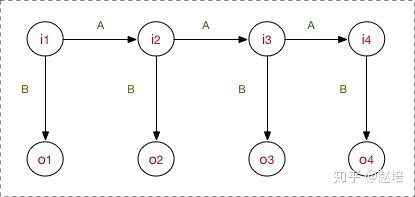
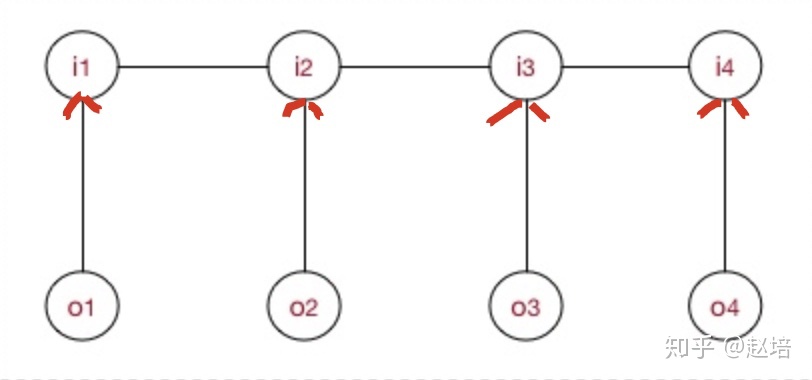
MEMM打破了HMM的观测独立假设【其实我也不太懂,这个需要看一看】,在MEMM中,标注状态 Ii 、 ,不仅和当前状态(观测)Oi相关,还跟前面的标注 Ij 相关。
MEMM允许“定义特征”,直接学习条件概率
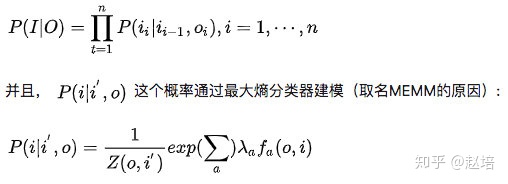
这部分是归一化, 且是局部归一化,只对当前状态和输入如何选择下一个状态归一化
P(Ii | li-1, oi)是特征函数,特征函数是需要去定义的;
lambda 是特征函数的权重,这是个未知参数,需要从训练阶段学习而得。
总体上,MEMM建模公式如下:
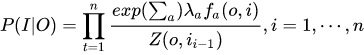
MEMM概率图:
注意:
1、不满足观测独立假设
2、MEMM是判别式
3、MEMM流程:
step1. 先预定义特征函数
step2. 在给定的数据上,训练模型,确定参数,即确定了MEMM模型
step3. 用确定的模型做序列标注问题或者序列求概率问题。
缺点:产生标注偏置
原因:局部归一化
现象就是:假设状态A到B只有一条路径,也就是A到B状态转移100%,此时不论B的观测是什么,总是会得到一样的结果,也就是忽略观测输入,只考虑状态转移。用下面的话说就是,MEMM倾向于选择拥有更少状态的转移。
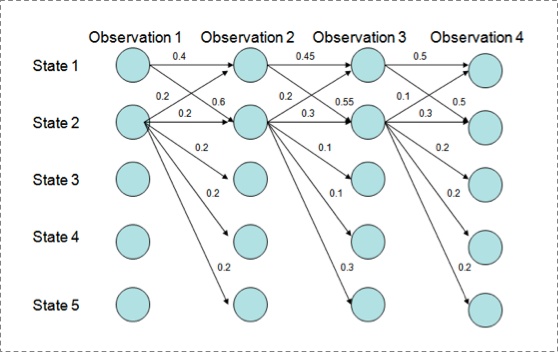
1. 现象
是从街货上烤过来的……
!img](https://pic4.zhimg.com/80/v2-40f9945cdffb12cfec84bebc7b7e3be5_hd.jpg)
用Viterbi算法解码MEMM,状态1倾向于转换到状态2,同时状态2倾向于保留在状态2。 解码过程细节(需要会viterbi算法这个前提):
P(1-> 1-> 1-> 1)= 0.4 x 0.45 x 0.5 = 0.09 , P(2->2->2->2)= 0.2 X 0.3 X 0.3 = 0.018, P(1->2->1->2)= 0.6 X 0.2 X 0.5 = 0.06, P(1->1->2->2)= 0.4 X 0.55 X 0.3 = 0.066
但是得到的最优的状态转换路径是1->1->1->1,为什么呢?因为状态2可以转换的状态比状态1要多,从而使转移概率降低,即MEMM倾向于选择拥有更少转移的状态。 2. 解释原因
直接看MEMM公式:
求和的作用在概率中是归一化,但是这里归一化放在了指数内部,管这叫local归一化。 viterbi求解过程,是用dp的状态转移公式(MEMM的没展开,请参考CRF下面的公式),因为是局部归一化,所以MEMM的viterbi的转移公式的第二部分出现了问题,导致dp无法正确的递归到全局的最优。
条件随机场
CRF是在给定随机变量X的条件下,Y的马尔可夫随机场。条件说明这是一个判别式模型,随机场是指无向图
马尔可夫随机场
广义的CRF的定义是: 满足
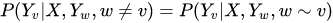
的马尔科夫随机场叫做条件随机场(CRF)。
线性链随机场
满足马尔可夫性
无向图联合概率分布因式分解:
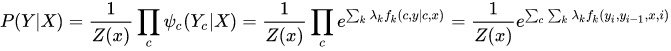
在线性链CRF示意图中,每一个对相邻的 i 状态为一个最大团,c是最大团的个数,总数是T序列长度,每个团的势函数自己定义,我们用的是状态转移函数和状态函数。
CRF建模公式如下:
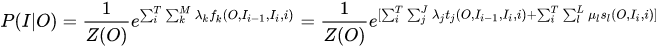
特征函数
特征函数详细解释见这里
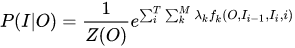
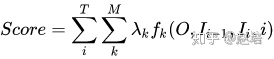
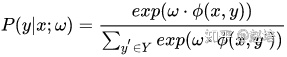
模型的工作流程,跟MEMM是一样的:
- step1. 先预定义特征函数
- step2. 在给定的数据上,训练模型,确定参数
- step3. 用确定的模型做
序列标注问题或者序列求概率问题。
模型流程
1、学习训练过程
一套CRF由一套参数λ唯一确定(先定义好各种特征函数)。
CRF用极大似然估计方法、梯度下降、牛顿迭代、拟牛顿下降、IIS、BFGS、L-BFGS等等优化方法优化
2、序列标注过程
还是跟HMM一样的,用学习好的CRF模型,在新的sample(观测序列 )上找出一条概率最大最可能的隐状态序列
3、序列求概率过程
LSTM+CRF
1、perspectively
大家都知道,LSTM已经可以胜任序列标注问题了,为每个token预测一个label(LSTM后面接:分类器);而CRF也是一样的,为每个token预测一个label。
但是,他们的预测机理是不同的。CRF是全局范围内统计归一化的条件状态转移概率矩阵,再预测出一条指定的sample的每个token的label;LSTM(RNNs,不区分here)是依靠神经网络的超强非线性拟合能力,在训练时将samples通过复杂到让你窒息的高阶高纬度异度空间的非线性变换,学习出一个模型,然后再预测出一条指定的sample的每个token的label。
2、LSTM+CRF
既然LSTM都OK了,为啥researchers搞一个LSTM+CRF的hybrid model?
哈哈,因为a single LSTM预测出来的标注有问题啊!举个segmentation例子(BES; char level),plain LSTM 会搞出这样的结果:
input: "学习出一个模型,然后再预测出一条指定" expected output: 学/B 习/E 出/S 一/B 个/E 模/B 型/E ,/S 然/B 后/E 再/E 预/B 测/E …… real output: 学/B 习/E 出/S 一/B 个/B 模/B 型/E ,/S 然/B 后/B 再/E 预/B 测/E ……
看到不,用LSTM,整体的预测accuracy是不错indeed, 但是会出现上述的错误:在B之后再来一个B。这个错误在CRF中是不存在的,因为CRF的特征函数的存在就是为了对given序列观察学习各种特征(n-gram,窗口),这些特征就是在限定窗口size下的各种词之间的关系。然后一般都会学到这样的一条规律(特征):B后面接E,不会出现E。这个限定特征会使得CRF的预测结果不出现上述例子的错误。当然了,CRF还能学到更多的限定特征,那越多越好啊!
好了,那就把CRF接到LSTM上面,把LSTM在timestep上把每一个hiddenstate的tensor输入给CRF,让LSTM负责在CRF的特征限定下,依照新的loss function,学习出一套新的非线性变换空间。
最后,不用说,结果还真是好多了呢。
BiLSTM+CRF codes, here. Go just take it.
这个代码比较早,CRF层中的transition matrix以及score的计算都是python from scratch. 目前tf 1.4早已将crf加入contrib中,4行代码即可实现LSTM拼接CRF的效果。
3. CRF in TensorFlow V.S. CRF in discrete toolkit
发现有的同学还是对general 实现的CRF工具包代码,与CRF拼接在LSTM网络之后的代码具体实现(如在TensorFlow),理解的稀里糊涂的,所以还得要再次稍作澄清。
在CRF相关的工具包里,CRF的具体实现是采用上述理论提到的为特征打分的方式统计出来的。统计的特征分数作为每个token对应的tag的类别的分数,输入给CRF解码即可。
而在TensorFlow中,LSTM每个节点的隐含表征vector:Hi的值作为CRF层对应的每个节点的统计分数,再计算每个序列(句子)的整体得分score,作为损失目标,最后inference阶段让viterbi对每个序列的transition matrix去解码,搜出一条最优路径。
关键区别在于,在LSTM+CRF中,CRF的特征分数直接来源于LSTM传上来的Hi的值;而在general CRF中,分数是统计来的。所有导致有的同学认为LSTM+CRF中其实并没有实际意义的CRF。其实按刚才说的,Hi本身当做特征分数形成transition matrix再让viterbi进行路径搜索,这整个其实就是CRF的意义了。所以LSTM+CRF中的CRF没毛病。
2. HMM vs. MEMM vs. CRF
将三者放在一块做一个总结:
- HMM -> MEMM: HMM模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关。但实际上序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。MEMM解决了HMM输出独立性假设的问题。因为HMM只限定在了观测与状态之间的依赖,而MEMM引入自定义特征函数,不仅可以表达观测之间的依赖,还可表示当前观测与前后多个状态之间的复杂依赖。
- MEMM -> CRF:
- CRF不仅解决了HMM输出独立性假设的问题,还解决了MEMM的标注偏置问题,MEMM容易陷入局部最优是因为只在局部做归一化,而CRF统计了全局概率,在做归一化时考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置的问题。使得序列标注的解码变得最优解。
- HMM、MEMM属于有向图,所以考虑了x与y的影响,但没讲x当做整体考虑进去(这点问题应该只有HMM)。CRF属于无向图,没有这种依赖性,克服此问题。
取至
[1] 如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









