







AB测试
所谓的AB测试其实与高中生物中实验对照组的概念一样,主要就是将实验对象进行分桶。打个比方,可以假设实验对象为用户,那么AB测试主要就是将实验对象进行分桶,即将实验对象分成实验组和对照组,对实验组的用户施以新模型,对对照组的用户施以旧模型,再分桶的过程中,要注意样本的独立性和采样方式的无偏性,确保同一个用户每次只能分到同一个桶中,在分桶过程中所选取的user_id需要是一个随机数,这样才能保证桶中的样本是无偏的。
从算法的角度来举个栗子:
- 有一个新模型A,目前系统中使用的是模型B,在正式上线前,需要通过AB测试来验证新模型在浙江用户上的效果,目前有如下三种方案:
- 根据user_id(完全随机生成)个位数的奇偶性将用户划分为实验组和对照组,对实验组施以模型A,对照组施以模型B。
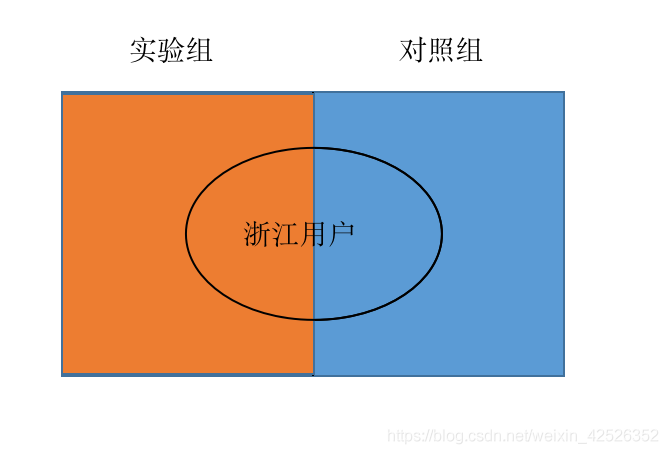
错,没有区分是否为浙江用户,实验组和对照组均有稀释。
- 将user_id个位数为奇数且为浙江用户作为实验组,其余用户为对照组。
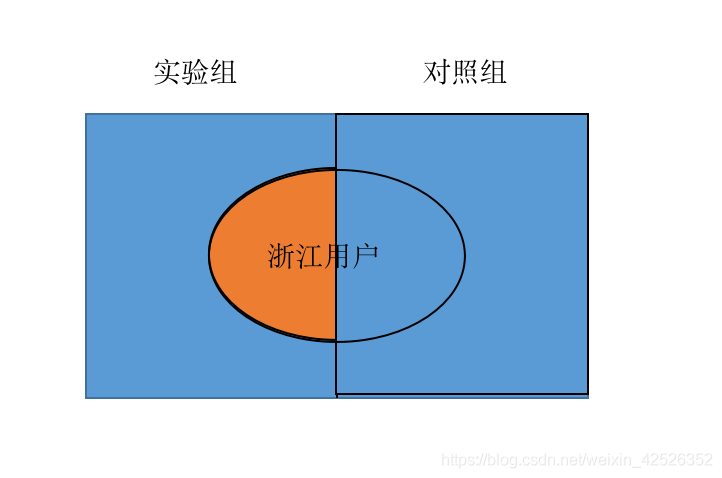
错,实验组无误,但选取其余所有用户划分为对照组,导致对照组的结果被稀释。
- 将user_id个位数为奇数且为浙江用户作为实验组,将user_id个位数为偶数且为浙江用户作为对照组。
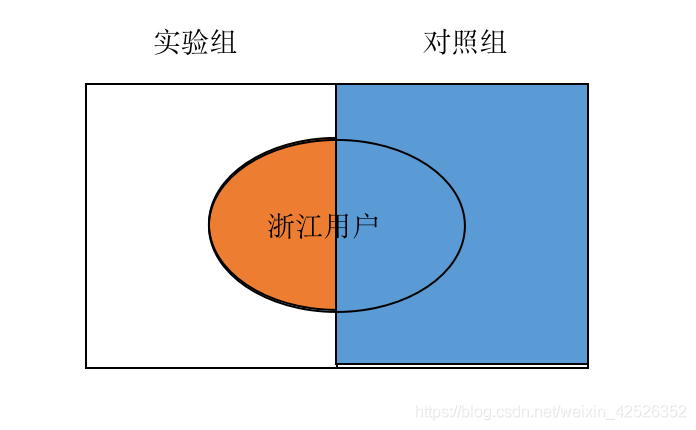
错,对照组存在偏差。
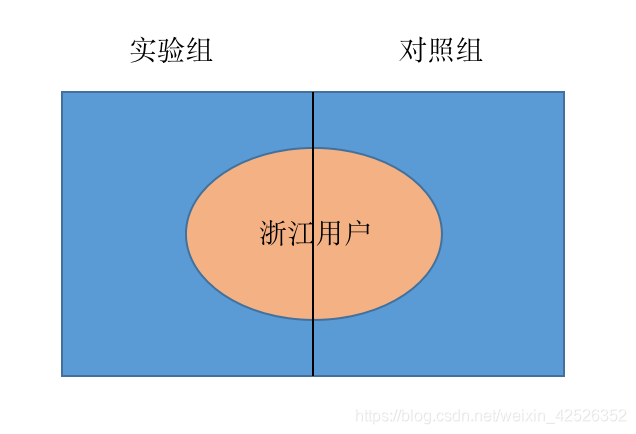
正确的方法是:将所有浙江用户根据user_id个位数划分为实验组合对照组,分别施以模型A,模型B,才能够验证A的效果。
灰度发布
灰度发布(测试)一般则是指如果该算法通过AB测的基础上,决定全面上线该模型,或者做一次比较重大的改版的话,要先进行一个小范围的尝试工作,然后再慢慢放量,直到这个全新的功能覆盖到所有的系统用户,也就是说在新功能上线的黑白之间有一个灰,所以这种方法也通常被称为灰度测试。类似于我们通常所说的内测,以便及时发现和纠正其中的问题,当然如果效果不理想,那么也可以及时采取灰度回滚。
通俗来讲,灰度发布就是将自己的产品首先拿出来给一部分目标人群使用,通过她们的使用结果和反馈来修改产品的一些不足,做到查漏补缺,完善产品的功能,使产品的质量得到提高。这样产品尽早的与用户接触能为以后产品的正式发布打下基础。
灰度期:灰度发布开始到结束期间的这一段时间,称为灰度期。
所以在实际项目中,AB测试&&灰度发布是进阶混合完成的,并且希望先灰度一些非核心低优先级的任务并且在低峰时间段来验证。离线调度任务是基于 Apache Airflow 为基础构建,因此实现方式是通过扩展Airflow增加了一些路由配置来支持SparkSQL,Tensorflow任务可以按优先级、时间段、流量比例等配置的AB测试&&灰度发布功能。
AB测分组sql实现
在ABtest测试上,通常会将用户群按照特定的条件分成若干组,然后取每组一定数量的用户(例如从总体中随机取5000个,或者随机取10%),发送对应的内容,最后查看效果。
1. 每个激活日期随机取1000个用户/10%用户
- 随机1000个用户
select user_id, active_date, rn
from (
select user_id, active_date, row_number() over(
partition by active_date order by rand() ) as rn
from t_user_active
) a
where rn <= 1000;
- 随机10%用户
select user_id ,active_date, rn
from (
select user_id, active_date, percent_rank() over (
partition by active_date order by rand() ) as pr
from t_user_active
) a
where pr <= 0.1
2. 随机均分成100组,每组取1000个用户/10%用户
案例二与案例一不同的地方在于,没有用户条件的限定,只需将用户随机均分成100组即可,这时用到了< ntile >窗口函数,其余与案例一同理。
- 随机均分成100组,每组取1000个用户。
select user_id, nt, rn
from (
select user_id, nt, row_number() over(
partition by nt order by rand() ) as rn
from (
select user_id, ntile(100) over(order by rand()) as nt
from t_user_all
) a
)b
where rn <= 1000;
- 随机均分成100组,每组取10%个用户
select user_id, nt, rn from (
select user_id, nt, percent_rank() over (partition by nt order by rand() ) as rn
from (
select user_id, ntile(100) over(order by rand()) as nt
from t_user_all)a
)b
where pr <= 0.1

















 1451
1451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











