






1、sql计算指标显著性
--评估显著性
raw as (
select pid, exp_group_name,
nvl(bubble_cnt,0) as bubble_cnt
from pas_tag
left join bubble
on pas_tag.pid=bubble.passenger_id
)
select
metric,
round(metric_t, 4) as metric_t,
round(metric_c, 4) as metric_c,
N_t,
N_c,
round(mean_difference, 4) as mean_difference,
concat(round(lift * 100, 2), '%') as lift,
round(upper_bound, 4) as upper_bound,
round(lower_bound, 4) as lower_bound,
case
when upper_bound * lower_bound > 0 then '显著'
else '不显著'
end as siginificance
from(
select
metric,
metric_t,
metric_c,
N_t,
N_c,
sum_ss_t,
sum_ss_c,
metric_t - metric_c as mean_difference,
case
when metric_c <> 0 then (metric_t - metric_c) / metric_c
end as lift,--处理组vs对照组的相对提升
case
when type = 'binomial' then metric_t - metric_c + 1.96 * sqrt(
metric_t * (1 - metric_t) / N_t + metric_c * (1 - metric_c) / N_c
)
when type = 'gaussian' then metric_t - metric_c + 1.96 * sqrt(
1 / N_t / (N_t -1) * (sum_ss_t - N_t * metric_t * metric_t) + 1 / N_c /(N_c -1) * (sum_ss_c - N_c * metric_c * metric_c)
)
when type = 'ratio' then metric_t - metric_c + 1.96 * sqrt(metric_a * (1 - metric_a) * (1 / N_t + 1 / N_c))
end upper_bound,
case
when type = 'binomial' then metric_t - metric_c - 1.96 * sqrt(
metric_t * (1 - metric_t) / N_t + metric_c * (1 - metric_c) / N_c
)
when type = 'gaussian' then metric_t - metric_c - 1.96 * sqrt(
1 / N_t / (N_t -1) * (sum_ss_t - N_t * metric_t * metric_t) + 1 / N_c / (N_c -1) *(sum_ss_c - N_c * metric_c * metric_c)
)
when type = 'ratio' then metric_t - metric_c - 1.96 * sqrt(metric_a * (1 - metric_a) * (1 / N_t + 1 / N_c))
end lower_bound
from (
select 'gaussian' as type
,'人均冒泡' as metric
,sum(if(exp_group = 'treatment_group', bubble_cnt, 0)) / sum(if(exp_group = 'treatment_group', 1, 0)) as metric_t
,sum(if(exp_group = 'control_group', bubble_cnt, 0)) / sum(if(exp_group = 'control_group', 1, 0)) as metric_c
,0 as metric_a
,sum(if(exp_group = 'treatment_group', 1, 0)) as N_t
,sum(if(exp_group = 'control_group', 1, 0)) as N_c
,sum(if(exp_group = 'treatment_group', bubble_cnt * bubble_cnt, 0)) as sum_ss_t
,sum(if(exp_group = 'control_group', bubble_cnt * bubble_cnt, 0)) as sum_ss_c
from raw
union all
select 'gaussian' as type
,'人均呼叫' as metric
,sum(if(exp_group = 'treatment_group', call_cnt, 0)) / sum(if(exp_group = 'treatment_group', 1, 0)) as metric_t
,sum(if(exp_group = 'control_group', call_cnt, 0)) / sum(if(exp_group = 'control_group', 1, 0)) as metric_c
,0 as metric_a
,sum(if(exp_group = 'treatment_group', 1, 0)) as N_t
,sum(if(exp_group = 'control_group', 1, 0)) as N_c
,sum(if(exp_group = 'treatment_group', call_cnt * call_cnt, 0)) as sum_ss_t
,sum(if(exp_group = 'control_group', call_cnt * call_cnt, 0)) as sum_ss_c
from raw))2、python 评估显著性
from scipy import stats
from statsmodels.stats.proportion import proportions_ztest
t=df[df.exp_group=='treatment_A']
c=df[df.exp_group=='control_group']
metrics_avg=['call_cnt', 'finish_cnt', 'finish_cnt_zy',
'finish_cnt_sf', 'gmv_amt', 'gmv_amt_zy',
'gmv_amt_sf', 'subsidy_c' ]
metrics_ratio=[['finish_cnt','call_cnt','CR']]
result=pd.DataFrame()
for x in metrics_avg:
p=stats.ttest_ind(t[x],c[x]).pvalue
t_n=t.shape[0]
c_n=c.shape[0]
t_avg=t[x].mean()
c_avg=c[x].mean()
gap=t_avg-c_avg
relative_gap=gap/c_avg
temp=pd.DataFrame([x,c_n,t_n,c_avg,t_avg,gap,relative_gap,p])
result=result.append(temp.T)
for x in metrics_ratio:
t_success=t[x[0]].sum()
c_success=c[x[0]].sum()
t_count=t[x[1]].sum()
c_count=c[x[1]].sum()
counts=np.array([t_count,c_count])
successes=np.array([t_success,c_success])
p=proportions_ztest(successes,counts)[1]
t_n=t.shape[0]
c_n=c.shape[0]
t_avg=t_success/t_count
c_avg=c_success/c_count
gap=t_avg-c_avg
relative_gap=gap/c_avg
temp=pd.DataFrame([x[2],c_n,t_n,c_avg,t_avg,gap,relative_gap,p])
result=result.append(temp.T)
result.columns=['指标','对照组样本量','实验组样本量','对照组','实验组','绝对提升','相对提升','p_value']
result['显著性']=np.where(result['p_value']<=0.05,'显著','不显著')
result=result.set_index(['指标'])
result【3】 Excel公式和在线网站等工具
Sample Size Calculator (Evan’s Awesome A/B Tools) (evanmiller.org)
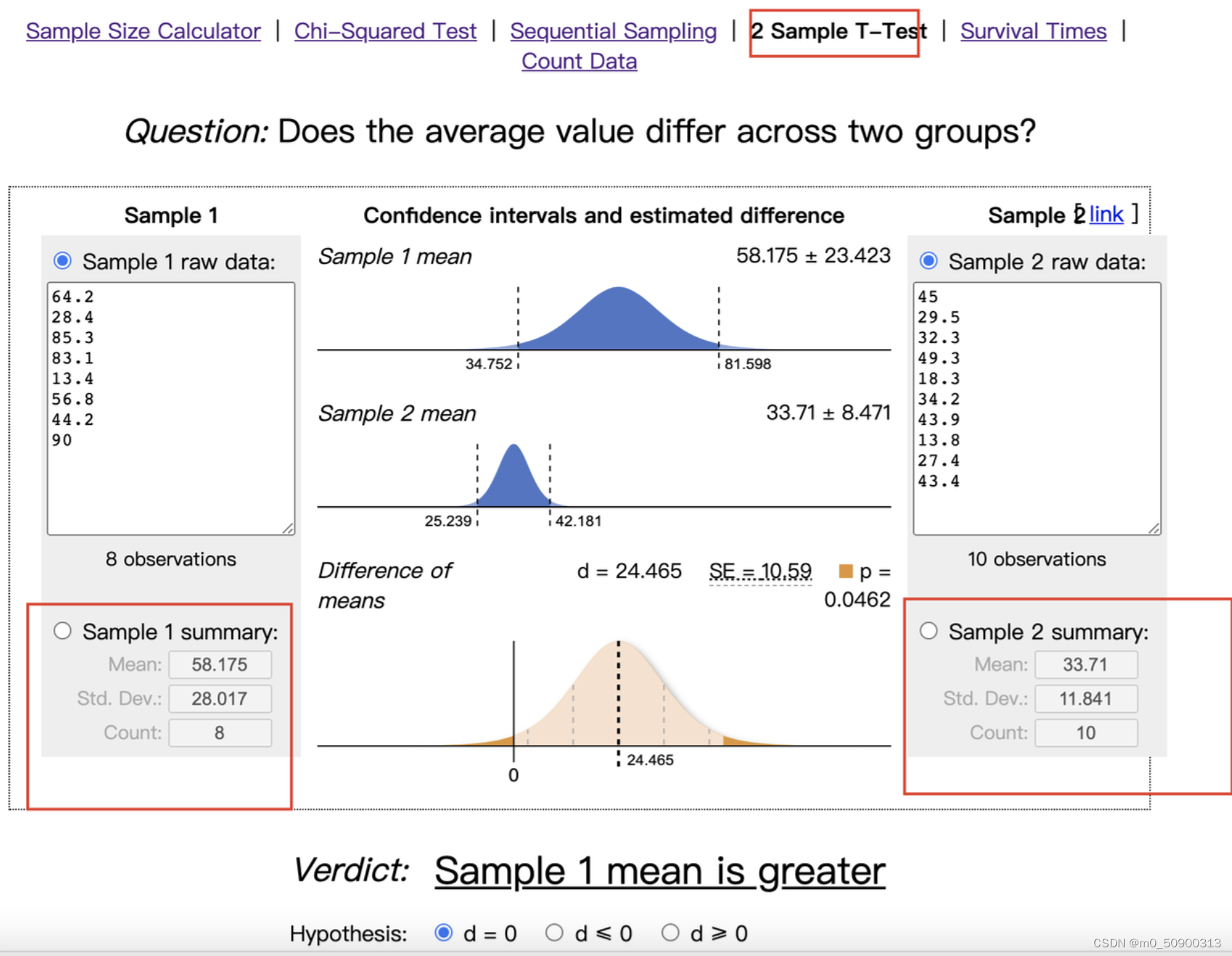
相关系列更多知识:关注gzh 《大佬等我呀》















 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









