






要理解为什么QListView结合自定义模型和委托在处理大数据集时性能更好,需要深入了解Qt的模型/视图框架的设计和工作原理。
性能差距的原因
-
数据分离与懒加载:
- QListView:
QListView只在需要显示的时候从模型中获取数据。这意味着它不会一次性加载所有数据,只会加载和显示当前视口(viewport)中可见的项。即使数据集非常大,只有当前需要显示的数据项会被访问和渲染。 - QListWidget:
QListWidget内部管理所有项的数据,所有数据项都会被一次性加载和管理,无论是否在视口中可见。这会导致在处理大数据集时内存占用和初始化时间更长。
- QListView:
-
缓存机制:
- QListView:使用自定义模型和委托时,可以实现有效的缓存和重用机制。例如,在滚动列表时,可以重用已经渲染的项,而不是每次都重新创建和销毁项。
- QListWidget:由于直接管理所有数据项,无法实现这种高效的缓存和重用机制,滚动和渲染性能会下降。
-
灵活性和优化:
- QListView:分离数据和显示的方式允许更细粒度的优化。例如,可以通过自定义模型实现高效的数据访问,通过委托实现高效的渲染。
- QListWidget:直接管理数据和显示,优化空间有限,尤其在数据量大和复杂显示需求时。
性能测试示例
为了更直观地展示性能差异,我们可以编写一个示例程序,比较QListView和QListWidget在处理大数据集时的性能。
示例代码
#include <QApplication>
#include <QListView>
#include <QListWidget>
#include <QStringListModel>
#include <QVBoxLayout>
#include <QWidget>
#include <QElapsedTimer>
#include <QDebug>
void populateListWidget(QListWidget *listWidget, int itemCount) {
listWidget->clear();
for (int i = 0; i < itemCount; ++i) {
listWidget->addItem(QString("Item %1").arg(i));
}
}
void populateListView(QListView *listView, int itemCount) {
QStringListModel *model = new QStringListModel(listView);
QStringList items;
for (int i = 0; i < itemCount; ++i) {
items << QString("Item %1").arg(i);
}
model->setStringList(items);
listView->setModel(model);
}
int main(int argc, char *argv[])
{
QApplication app(argc, argv);
QWidget window;
QVBoxLayout layout(&window);
QListWidget listWidget;
QListView listView;
layout.addWidget(&listWidget);
layout.addWidget(&listView);
int itemCount = 100000;
// Measure time for QListWidget
QElapsedTimer timer;
timer.start();
populateListWidget(&listWidget, itemCount);
qDebug() << "QListWidget populated in" << timer.elapsed() << "ms";
// Measure time for QListView
timer.restart();
populateListView(&listView, itemCount);
qDebug() << "QListView populated in" << timer.elapsed() << "ms";
window.show();
return app.exec();
}
解释
- populateListWidget:向
QListWidget添加100,000条数据。 - populateListView:向
QListView添加100,000条数据,但数据存储在QStringListModel中,QListView通过模型访问数据。 - 时间测量:使用
QElapsedTimer测量两个操作的时间,比较它们的性能。
运行结果
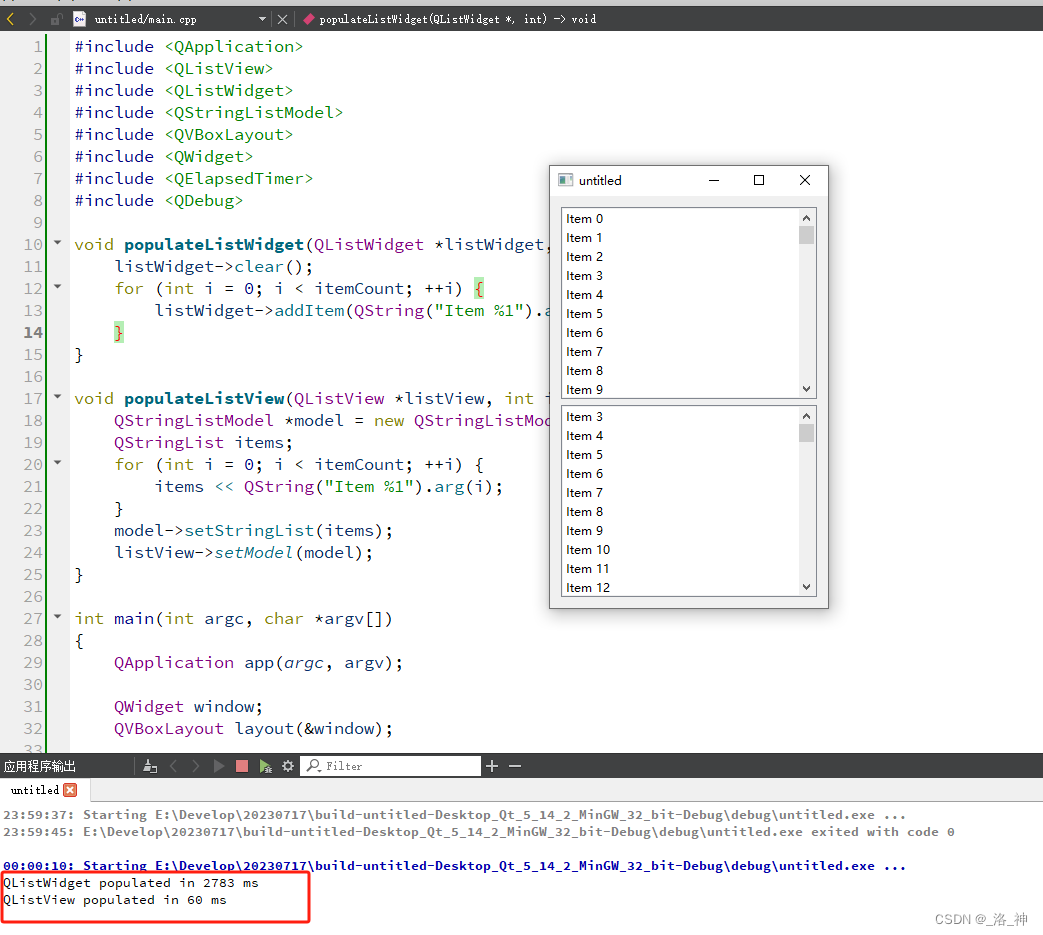
- QListWidget:由于它一次性加载和管理所有数据,初始化时间和内存占用较高,性能较差。
- QListView:通过模型访问数据,初始化时间较短,内存占用较低,性能更好。
结论
通过上述示例和解释,可以看出QListView结合自定义模型和委托在处理大数据集时的性能优势。具体表现为:
- 数据懒加载:仅加载和渲染可见项,减少不必要的数据处理。
- 高效缓存和重用:减少创建和销毁项的开销。
- 数据显示分离:允许更细粒度的优化和扩展。
因此,对于处理大数据集和复杂显示需求的应用场景,使用QListView结合自定义模型和委托是更好的选择。















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









