







1. 什么是dataloader数据集加载器
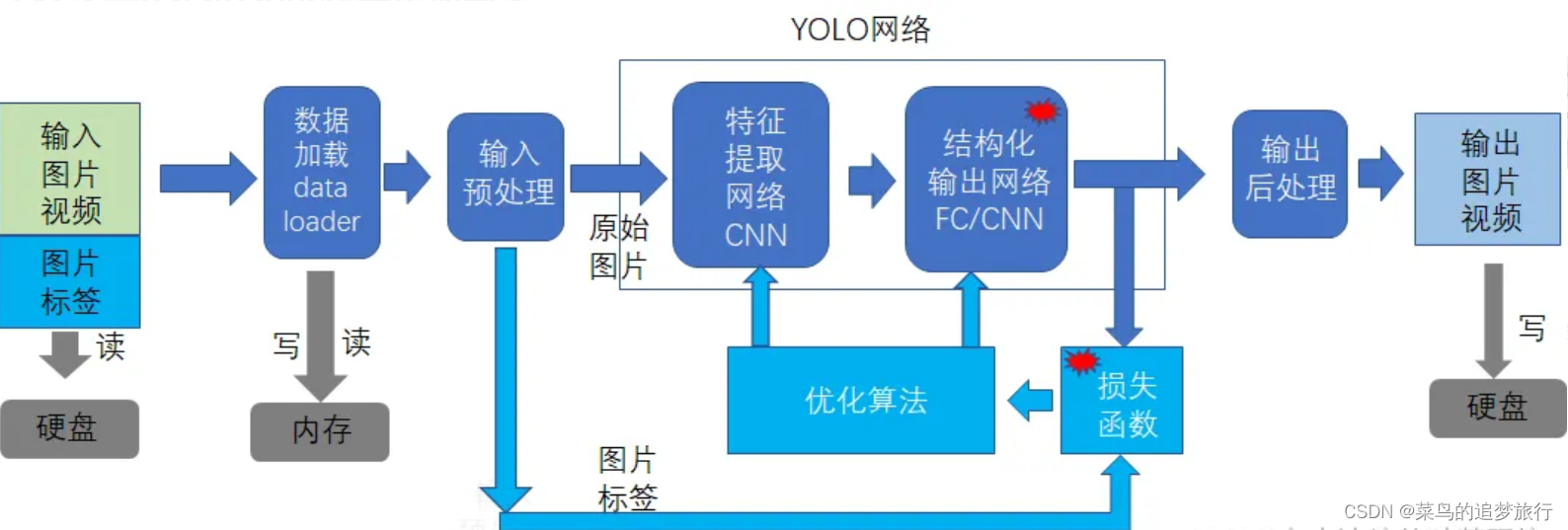
数据加载器dataloader处于硬盘的输入图片与YOLO神经网络之间。
其存在的意义和目的:是降低对硬盘的访问频次。
基本的方法是:批处理 和缓存
- 批处理:从硬盘中一次读取多个批次的多张图片文件到内存中,而不是一张一张图片的读取,批处理,避免了频繁的读取硬盘,缓解了高速的GPU网络处理与低速的硬盘文件读取之间速度上的不平衡。
- 缓存:硬盘中的图片和标签是分开的,cache的作用是把各个独立的硬盘图片以及标签,整合在一个cache文件,这样dataloader就不需要查找和打开一个个单独的文件。因为打开、读取和关闭文件的开销还是很大。
- 多线程:多线程的目的还是增加对硬盘数据读取的效率,特别是在多GPU训练的场合,多线程读取数据,就显得尤为重要 。
因此数据加载器的职责就是读取带有标签的数据。
2. Pytorch的dataloader
2.1 依赖的库
from torch.utils.data import DataLoader, Dataset
这里有两个主要的对象
(1)dataset:包括pytorch预支持的数据集以及用户可以自定义自己的数据集 数据集的职责:定义数据集在硬盘中的位置、机构化数据的数据、标签等信息。
(2)dataloader:通过dataset读取硬盘中的数据集,并把图片和标签存放在内存中 。以供神经网络随时使用。
2.2 自定义自己的数据集
数据集dataset对象:负责读取、管理和组织自身的数据。 基于Dataset模板定义自己的数据集class,里面至少包含3个函数:
①__init__:传入数据,或者像下面一样直接在函数里加载数据
②__len__:返回这个数据集一共有多少个item ③__getitem__:返回一条训练数据,并将其转换成tensor
import torch
from torch.utils.data import Dataset
class MyData(Dataset):
def __init__(self):
a = np.load("D:/Python/nlp/NRE/a.npy",allow_pickle=True)
b = np.load("D:/Python/nlp/NRE/b.npy",allow_pickle=True)
d = np.load("D:/Python/nlp/NRE/d.npy",allow_pickle=True)
c = np.load("D:/Python/nlp/NRE/c.npy")
self.x = list(zip(a,b,d,c))
def __getitem__(self, idx):
assert idx < len(self.x)
return self.x[idx]
def __len__(self):
return len(self.x)
# 创建Y一个数据集dataset实例
xxx_dataset = MyData()
2.3 自定义dataloader加载器
数据集加载器对象dataloader:负责通过dataset对象,读取数据集数据,并存放在在自己的内存中。
instance_dataloader = DataLoader(dataset, batch_size = 2, shuffle=True,collate_fn = preprocess)
创建一个dataloader实例:instance_dataloader = DataLoader(…)
- dataset:指定该dataloder关联到那个数据集对象上。
- batch_size = 2: 为训练网络提供batch数据,这里指定batch的长度。
- shuffle:从dataset中读取到的样本,是否需要打乱后才被运行load到内存中,以增加训练数据的随机性,增强训练网络的适应性和泛化能力。
- collate_fn = preprocess:在加载每个数据集数据时,需要进行什么样的预处理:比如填充,比如转换为pytorch的tensor,比如数据增强等等功能。这里的数据增,在传递个神经期望之前,就已经完成。
备注:dataloader会启动内部的线程,通过dataset对象,从硬盘中读取数据。
2.4 使用dataloader迭代器读取数据
for i, data in enumerate(xxx_data_loader):
xxx
xxx
dataloader本质上也是一个可迭代的对象,通过迭代的方式读取数据集数据,并泛化给data。
pytorch dataloader是一个通用的dataloader,他建立了一个通用的数据集加载的机制和框架。 然后,不同的训练网络,所需要的数据集不同,dataloader要处理的内容也不相同,这就需要在pytorch的dataloader的基础之上,进一步的封装,以便提供YOLO所需要的数据加载器。
3. YOLO V5 - ultralytics dataloader的代码实现
源代码:yolov5\utils\datasets
3.1 create_dataloader
(1)函数原型
def create_dataloader(
- path, # 样本所在的目录
- imgsz, # 规范化后image的大小,不管输入图片多大,规范提供给网络的图片的尺寸
- batch_size, # batch size,默认是16,对于GPU内存小的开发环境,可以设置为1.
- stride, # 步长:
输入图像经过卷积后,到输出图像降采样的倍数,默认是32倍,也就是说,32*32个像素点,经过特征提取后,会汇集成一个点。对于占用像素点少的小目标,可以适当的降低tride的值, - single_cls=False, # 是否为单一分类
- hyp=None, # 超参数
- augment=False, # 是否需要数据增强 cache=False,
#是否需要对数据集进行cache,如果使能,会在数据集的目录中生成数据集的cache文件,下次加载时,直接加载cache文件中的内容,而不需要挨个读取单个文件。 - pad=0.0, # 把多个图片拼接成一个图片时,定义填充值。
- rect=False, #
是否支持直接通过长方形而不是正方形的图像进行训练,如果不支持,则徐亚规范化成imgsz指定的正方形图像。 - rank=-1, # ???
- workers=8, # 同时启动几个loader线程
- image_weights=False, # ???
- quad=False, # ??? prefix=‘’, # ???
- shuffle=False ) # 是否需要
- shuffle,打乱数据集
(2)主要功能 创建YOLO数据集:
-
dataset = LoadImagesAndLabels()
-
利用pytorch的loader创建加载器对象:loader = DataLoader()
3.2 支持的其他功能
(1)load_image: 加载普通的image class LoadImages和标签: 本地图片 (适合本地检查和本地训练) class LoadWebcam: 本地视频 (只适合检测) class LoadStreams: 支持网络视频或图像(只适合检测)
(2)load_mosaic/load_mosaic9: 加载image时,马赛克数据增强加载 Mosaic数据增强方法是YOLOV4论文中提出来的,主要思想是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据。这样做的好处是丰富了图片的背景,并且四张图片拼接在一起变相地提高了batch_size,在进行batch normalization的时候也会计算四张图片,所以对本身batch_size不是很依赖,单块GPU就可以训练YOLOV4。
马赛克数据增强的设置是超参数有设置,而不是用户命令行设置。
4. 参考文章
原文链接:https://blog.51cto.com/u_11299290/5144793
感谢原作者,转载这篇文章是为了便于学习,如有侵权,请联系删除。















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









