






一、什么是k近邻算法
通俗的讲,k近邻算法就是将一个数据集按一定的空间进行划分,再通过查找k个最相近的值来判断某一数据属于哪个空间。它是一种有监督算法,与其对应的是无监督算法,这两个概念不在这里进行讲解。
还是通过一个简单的例子,来直观地感受一下什么是k近邻算法。假设,有A和B两个学生,他们的数学成绩、语文成绩和评价如下:
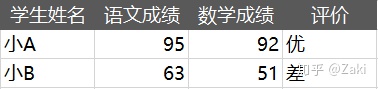
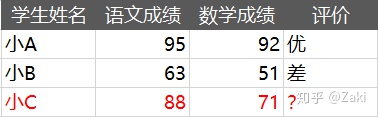
而针对这份数据,唯一知道的就是评价只有“优”和“差”两类,没有其他类别,但这个结果是按什么标准得出的却不得而知。在这种情况下,又出现小C同学,他的成绩分别是88分和71分,那么我又该如何评价小C呢?确切地讲我应该按什么样的标准或方法把他归为“优”或“差”呢?
这里用python进行简单地模拟,再通过k近邻算法来找出答案。
#导入pandas包
import pandas as pd
#创建训练数据集:小A和小B的成绩
#评价一列中,1代表‘优’,0代表‘差’
students = pd.DataFrame([[95,92,1],
[63,51,0]],
columns=['语文','数学','评价'])
#展示数据
students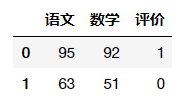
绘制散点图来查看数据的分布情况。
#导入数据可视化包
from matplotlib import pyplot as plt
#绘制学生A的散点图
plt.scatter(x=students['语文'][0],y=students['数学'][0],color='blue',label='优')
#绘制学生B的散点图
plt.scatter(x=students['语文'][1],y=students['数学'][1],color='red',label='差')
#显示图像中的label值
plt.legend()
#设置x轴、y轴、标题信息
plt.xlabel('语文成绩')
plt.ylabel('数学成绩')
plt.title('学生成绩')
#显示网格线
plt.grid(True)
#展示图像
plt.show()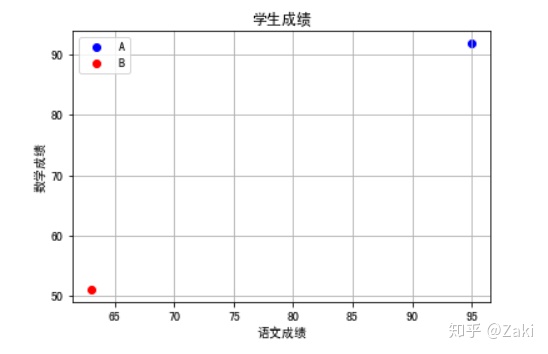
这个图中,小A和小B分别占据了两极,我们可以想象整个数据被这两个人划分成了两个空间。两个人各自立山头为王,接近小A的都算“优”,接近小B的都算“差”。
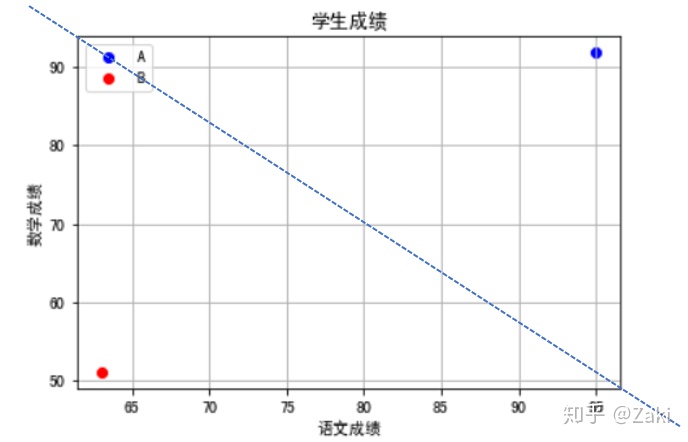
那么,在此基础上,再添加小C的成绩,也就是用来测试的数据。从图像上,可以直观地看出小C是属于“优”这一类的,理由就是它离小A近。
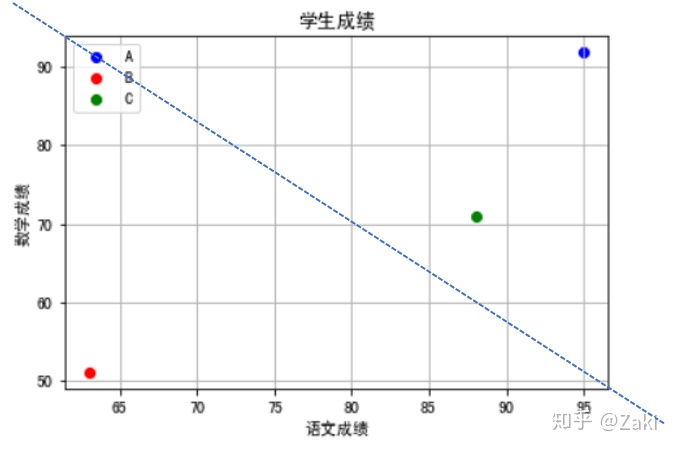
可计算机没法像人类一样用肉眼就能判断出这一结果,它需要一些计算来确定小C离小A近,而不是离小B近。我们都知道两点之间直线最短,而这条直线是可以通过欧式距离来计算得出的,再通俗点的讲就是计算直角三角形时用到的勾股定理。
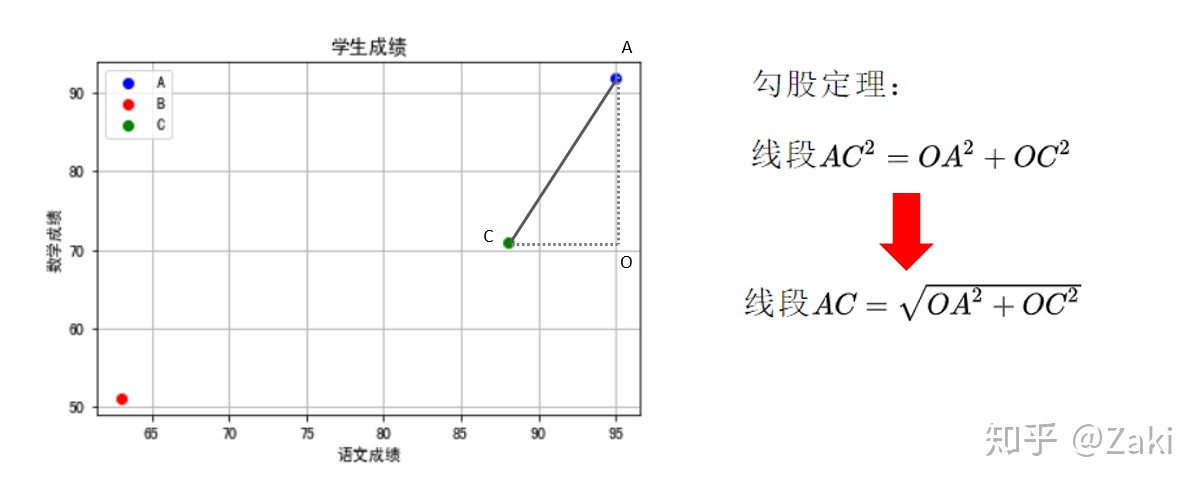
计算出小C与各个点的距离后,谁距离的最短,就将小C判断为那一类。三角形的两条边可以用A的坐标(95,92)和C的坐标(88,71)相减来得到,因为两条边要开平方,所以就算得到的结果是负数也没关系,接下来就用代码实现这一过程。
#用c坐标与其他坐标做减法,得出计算距离所需的两条边的长度
square = students[['语文','数学']] - test_C
#求出两条边后,将每条边都进行开方
square = square ** 2
#开方后,将两条边相加。sum函数里的axis值等于0时行相加,等于1时列相加
square = square.sum(axis=1)
#加完之后开根号
square = square ** 0.5
#显示数据
square
#获取最小值的索引值
minId = square.idxmin()
#根据最小值索引,查找出相应的“评价”值
assess = students['评价'][minId]
#输出判断结果
if(assess == 1):
print('评价结果为:优')
else:
print('评价结果为:差')
上述例子所讲的算法,准确地来说是“最近邻算法”,因为这里我们只判断了离小C最近的1个值,这里的k也就等于1。而k近邻,就是指距离小C最近的k个值,然后采用多数决来判断小C属于哪个分类,即处在哪个空间。k值一般大于1小于20,更多是取决于样本大小。
二、sklearn实现手写数字识别
①案例说明
从kaggle上下载的手写数字识别数据集,所有的手写数字都经过像素画处理,以28*28矩阵的形式进行存储。

数据来源:https://www.kaggle.com/c/digit-recognizer/data
②读取数据
#导入相应的包
import pandas as pd
#读取csv文件
numberData = pd.read_csv('train.csv')
#展示前5行数据集
numberData.head()
③数据说明
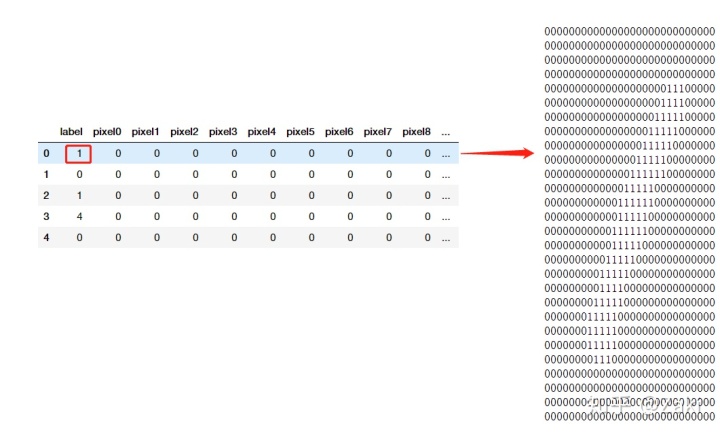
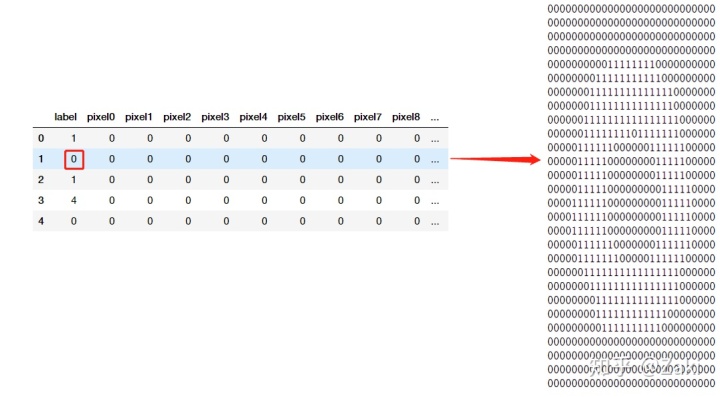
读取数据后发现数据很抽象,一共有785列,每一行代表一个手写数字。第一列是label,剩下的是pixel0到pixel783。
label:代表的是该手写数字识别后的结果。
pixel:这里是将28*28的矩阵转化成了一个一维数组,所以pixel会有784列,28*28 = 784,所以每一列的pixel值代表的就是 矩阵中相应位置的数值。
④构建模型
#导入相应的包
from sklearn.model_selection import train_test_split #随机生成训练集和测试集
#将原始数据拆分成:标签集,手写数字集
#标签集
label = numberData.loc[:,'label']
#手写数字集
numberPic = numberData.loc[:,'pixel0':'pixel783']
#建立训练集和测试集:80%用于训练,20%用于测试
train_X,test_X,train_y,test_y = train_test_split(numberPic,label,train_size=0.8)
print(' 训练集特征',train_X.shape[0],
' 训练集标签',test_X.shape[0])
print(' 测试集特征',train_y.shape[0],
' 测试集标签',test_y.shape[0])
⑤选择算法训练模型并评估
#导入相应的包
from sklearn.neighbors import KNeighborsClassifier as KNN #k近邻算法
#创建模型:n_neighbors代表k值,默认是5,这里用3
neigh = KNN(n_neighbors = 3)
#训练模型:带入训练集
neigh.fit(train_X,train_y)
#评估模型:带入测试集。返回的结果是模型成功识别的准确率
neigh.score(test_X,test_y)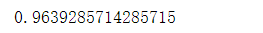
⑥案例总结
上述结果表明,在k值等于3的情况下,该模型的识别正确率达到了96.4%。k值的取值不同,自然也会影响模型的准确率,因为它是取离数据最近的k个点并采用多数决进行判断。k值太小就会出现过拟合的现象,而k值太大误差就大,容易使预测发生错误。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









