







一点题外话
由于本次题目涉及到了编译原理,而题主这门课还没开始修,所以接下来的解析只能是以自己的角度来理解,描述过程中极有可能出现不严谨的地方,还望各位大大见谅。
题目要求
尽管不是很明白为什么要在网络编程这一门课上丢一个编译原理的作业(甚至编译原理的课程都还没有学习),但是既然给出了源码,那么就尝试着理解并改进一下吧,也借此机会管中窥豹一下编译原理这门课。下面是计算器的要求:
- 具有加、减、乘、除、模的功能(操作符)
- 加、减具有同样的优先权,乘、除、模具有同样的优先权,但高于加、减
- 支持‘()’(具有最高优先权), 也即sub expression
- 只考虑处理非负整数,也即 >= 0的正数
源码解析
'''
A module of evaluating expr, and just for Network Programming 2021
王海平
02/10/2021 南京
'''
import operator
import re
from operator import *
import traceback
isa = isinstance # Just for typing convenience,isinstance函数用于判断数据类型
symbol_table = {
'+':add,'-':sub,'/':floordiv,'*':mul,'%':mod,'**':lambda a,b:int(pow(a,b)),'//':floordiv,
}
def list_checker(x):
'check whether x is a non-empty list or not, if so, return its length'
if x != [] and isa(x,list):
return len(x)
return 0
def require(x,predicate,msg = "invalid token"):
if not predicate:
raise SyntaxError(msg)
def atom(x):
require(x,isa(x,str),'Fatal error!')
try:
# Here we try it as a number first,Otherwise, it's a symbol
return int(x)
except Exception:
return x
all_tokens = []
#将字符串划分为单个的元素:表达式和数字
def tokenizer(x):
r = r'((\*{2,})|(\/{2,})|[^\w\d])'
global all_tokens
all_tokens = list(map(atom,re.sub(r,lambda m:' ' + m.group() + ' ',x).split()))
return
def token_reader():
return all_tokens.pop(0) if all_tokens else None
def parser(look_ahead_token):
token = look_ahead_token
if token == None:
return []
if token == '(':
subs = []
while True:
token = token_reader()
if token == None:
break
if token == ')':
break
subs.append(parser(token))
if token != ')':
raise SyntaxError(f'missing ")"!')
if not subs:
raise SyntaxError('empty ()!')
return subs
elif token == ')':
raise SyntaxError('wrong ")" token)')
else:
return token
def evalx(syntree,eval_level = 1):
trace = True
if list_checker(syntree) > 1:
print('\t'* (eval_level-1) + "evalx " + repr_list(syntree,nocomma = True))
trace = True
def term(tree):
a = factor(tree)
while isa(a,int) and list_checker(tree) and tree[0] in ['*','/','%','**','//']:
func = symbol_table[tree.pop(0)]
c = factor(tree)
require(tree,isa(c,int),"Invalid operand!")
#
# apply func with args of a and c
#
a = func(a,c)
return a
def factor(tree):
'''Two cases considered here:
1 a single token
2 a list(sub expr)
'''
r = tree.pop(0)
if isa(r,list):
#
# It's a sub expr,then evaluate it now !
#
r = evalx(r,eval_level + 1)
else:
assert isa(r,int),f'[{r}] should be a number!'
return r
a = term(syntree)
while list_checker(syntree) and syntree[0] in '+-':
func = symbol_table[syntree.pop(0)]
c = term(syntree)
require(syntree,isa(c,int),"Invalid operand!")
a = func(a,c) # update a here!
if trace:
print('\t'* (eval_level-1) + "eval result:[" + str(a) + ']')
return a
def prompt(sprompt = '\r\nevalx>>',must_valid = True):
'''Read something from console, if must_valid is True
we always return something(not white chars)
'''
s = input(sprompt).strip()
if not s and must_valid:
#
# Nothing, and try again !
#
s = prompt(sprompt)
return s
def repr_list(x,sep=' ',nocomma = False):
s = '['
first = True
for a in x:
if not first:
s += sep
if list_checker(a):
s += repr_list(a,sep,nocomma)
else:
if a != ',' or not nocomma:
if isa(a,int):
s += str(a)
else:
s += "'" + str(a) + "'"
first = False
return s + ']'
def expr_handler(expr):
try:
# Normalize this expr by adding '(' in front and ')' at tail
expr = '(' + expr + ')'
print('expr:' + expr)
tokenizer(expr)
#将字符串分解为元素
print('tokens:[' + repr_list(all_tokens,sep = ' ')[1:-1] + "]")
if not prompt_user or prompt("Would you like to parse tokens[YES|NO]?",False).lower() not in ['no','n']:
#计算表达式
tt = parser(token_reader())
print('Syntax tree:' + repr_list(tt,sep = ' '))
if all_tokens:
print("Invalid token ===>>> {}".format(all_tokens))
raise SyntaxError("invalid token")
if not prompt_user or prompt("Would you like to evaluate them[YES|NO]?",False).lower() not in ['no','n']:
n = evalx(tt)
if tt:
print("Invalid token ===>>> {}".format(tt))
raise SyntaxError("invalid token")
print('result:[' + str(n) + ']')
except Exception as e:
print(f"\nInvalid expr ===>>> [{expr}]\n")
traceback.print_exc(limit=3)
return
prompt_user = False
def repl():
' a function for Read -> Evaluate -> Print -> Loop'
while True:
expr = prompt()
if expr in ('quit','exit','q'):
print('\r\nBye ...')
break
if expr == "prompt":
global prompt_user
prompt_user = not prompt_user
continue
if expr.lower() == 'test':
test_evalx()
continue
expr_handler(expr)
def test_evalx():
all_expr = ('1+ 2*3',
'(1 + 2) * 3',
'106 + 7 * (5 - 2)',
'(((3+2)*3)*5-7) - (6 *(3+8)/2)',
'(((3+2)*3)*5-7) - (6 *(3+8)2)', # innvalid
'() + 66', # innvalid
#bug:乘方和乘除优先级相同
'4*5**2',
'5**2*4',
#bug:乘方和乘除优先级相同
)
for expr in all_expr:
expr_handler(expr)
prompt("\r\nPls press ENTER key to continue...",False)
if __name__ == '__main__':
#test_evalx()
repl()
首先看一下引用的库,一共引用了三个库,分别是:
- 正则表达式库re,这部分用于词法分析
- 操作符库operator:这部分用于最后的二元操作符的计算
- traceback库:用于更好的显示错误出现的地方,这个库不是属于必须的,只是有了更好
看一下大致结构
可以很容易的找到主要函数expr_handler,这个函数以字符串为输入,输出一个float的数值。进入expr_handler函数内部,可以看到整个函数不长,刨除提示和错误处理逻辑后,其实主要是调用了这几部分语句:
expr = '(' + expr + ')'
print('expr:' + expr)
tokenizer(expr)
tt = parser(token_reader())
n = evalx(tt)
通过搜索token、parser、evalx以及这三个函数内部的一些关键词可以猜测到,这三个函数对应的流程应该是:词法分析、语法分析、求值这三个步骤,也就是采用了类似于Python语言的编译模型。
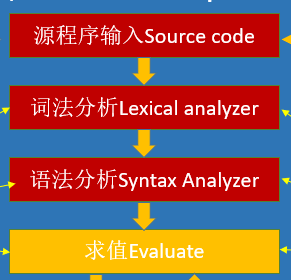
tokenizer()
这个函数用于将源程序字符串分解为对应的元素,而在这个计算器中的合法的单词有:数字,+ , - , * ,/,**,//,(,)。
比如语句66+55*33-44+(3**5//2),将被划分为一个如下的列表:
(66,'+',55,'*',33,'-',44,'+','(',3,'**',5,'//',2)
可以看到原函数其实比较简单。但是其中的核心语句有点长了
all_tokens = list(map(atom,re.sub(r,lambda m:' ' + m.group() + ' ',x).split()))
为了方便调试和结构清晰,我重写了这个函数
#equal code
def tokenizer(x):
r = r'((\*{2,})|(\/{2,})|[^\w\d])'
#():子表达式的开始
#{}:最少n次重复,最多m次重复
#\w:匹配数字、下划线、字母
#\d:匹配数字
#Equal Code
def TmpFun(m):
return ' ' + m.group() + ' '
#将每个字符用' '划分出来
TmpVar=re.sub(r,TmpFun,x)
TmpVar=TmpVar.split()
#将每个字符用' '划分出来
TmpVar=map(atom,TmpVar)#区分运算符和数字
global all_tokens
all_tokens=list(TmpVar)
return
这下结构就清晰多了,正则表达式和Python中map、list函数的用法,请自行参考第三方文档。
parser
这个函数的作用是将上一步解析好的一个一个独立的单词组成按照自己的规则组成有意义的元素,如上节列表经过转换会成为一个新的语法树(尽管没有树的结构)
(66,'+',55,'*',33,'-',44,'+',('(',3,'**',5,'//',2))
也就是说,这里的语法树由三个元素构成:操作数(数据)、操作符(运算)、子表达式。
eval
这个函数的作用是将我们上一步构造好的语法树进行求值。这个函数也是最为复杂的一个函数,在解析之前再次强调一下由于题主还没有修过编译原理,这部分可能会比较口水话。另外这部分老师的逻辑有一点点BUG并且遇到多个优先级的时候不太好用,我会在后面贴出我自己的理解并修复这个BUG。
在解析整个过程前,记住一点,在整个求值过程中,语法树在这里是以队列的形式呈现的,每次取出一个元素时,会弹出队首元素。
首先看一下这个函数的主循环部分:
a = term(syntree)
while list_checker(syntree) and syntree[0] in '+-':
func = symbol_table[syntree.pop(0)]
c = term(syntree)
require(syntree,isa(c,int),"Invalid operand!")
a = func(a,c) # update a here!
return a
可以看到,这段代码的主要逻辑应该是:如果是最低优先级的运算符+、-的话,就将两个经过term函数的操作数进行运算,循环进行直到语法树解析完成。
term
那么term函数的作用是什么呢?该函数以某个表达式为输入,循环进行这样的操作:取出语法树中的两个操作数和一个操作符,进行运算,直到遇到下一级操作符或者语法树结束。
如表达式3*5*8的计算过程为:
- 取出3、*、5,运算,得到结果15,更新表达式
- 取出15、*、8,运算,得到结果120
- 语法树解析结束,输出结果
又如表达式3*5+8*5的运算结果为:
- 取出3、*、5,运算,得到结果15,更新表达式
- 下一个运算符为’+’,结束运算,并返回结果15(此时的语法树应该为
'+',8,'*',5)
term函数如下:
def term(tree):
a = factor(tree)
while isa(a,int) and list_checker(tree) and tree[0] in ['*','/','%','**','//']:
func = symbol_table[tree.pop(0)]
c = factor(tree)
require(tree,isa(c,int),"Invalid operand!")
#
# apply func with args of a and c
#
a = func(a,c)
return a
在term函数用到了factor函数,之前提到过,在这个作业中,语法树由操作数、操作符和子表达式构成,而子表达式的运算结果应该是一个操作数。所以这里的factor函数的作用就是输入一个语法树中的元素,如果是子表达式的话就通过递归调用求值函数eval来求出子表达式,否则直接返回操作数。
了解了factor函数后,结合例子,这里的term函数的循环结构就清楚了。
总结一下,在求值这个步骤中,主要使用到了如下思想:
- 整个运算符只有两级
- 如果是第二级运算符,则直接进行两个数据之间的运算;如果是第一级运算符,则先求出这个运算符的数据,再进行求值。如
8*5+6*4的求值过程为8*5,6*4,40+24。
BUG
在老师给出的代码里面,由于只有两级操作数,所以一下算式是不等价的:
4*5**2
5**2*4

更新后的计算器
先上代码和结果:
#pragma once
#include<iostream>
#include<math.h>
#include<vector>
#include<string>
#include<map>
#include<algorithm>
using namespace std;
constexpr int PtType = 1;
constexpr int NonPtType = 0;
template<class T>
struct N_Vector{
int DataType_Id;
union
{
vector<N_Vector<T>>* ElePt;
T* Ele;
}Ele;
N_Vector(int Id, void* Ele) {
this->DataType_Id = Id;
if (Id == PtType)
this->Ele.ElePt = (vector<N_Vector<T>>*)Ele;
else
this->Ele.Ele = (T*)Ele;
}
};
class Calculator {
private:
void Show_StrVector(const vector<string>& Strings, string Title) {
cout << Title;
for (int i = 0; i < Strings.size(); i++)
{
printf("\'%s\',", Strings[i].c_str());
}
cout << endl;
}
int GetPriority(const string& op) {
for (int i = 0; i < Operator.size(); i++)
{
if (find(Operator[i].begin(), Operator[i].end(), op) != Operator[i].end())
return i;
}
return -1;
}
void Show_SyxTree(vector<N_Vector<string>>& Vector) {
for (int i = 0; i < Vector.size(); i++)
{
if (Vector[i].DataType_Id == NonPtType) {
string* Ele = Vector[i].Ele.Ele;
printf("\'%s\',", Ele->c_str());
}
else {
printf("{");
Show_SyxTree(*Vector[i].Ele.ElePt);
printf("}");
}
}
}
int term(vector<N_Vector<string>>& expression,float& Result) {
float Left_Operand = factor(expression[0]);
expression.erase(expression.begin());
while (expression.size())
{
if (expression.size() > 2) {
if ((GetPriority(*expression[0].Ele.Ele) < 0 || GetPriority(*expression[2].Ele.Ele) < 0)) {
printf("%s Should be a Operator\n", *expression[0].Ele.Ele);
return -1;
}
if ((GetPriority(*expression[0].Ele.Ele) >= GetPriority(*expression[2].Ele.Ele))) {
string Operator = *expression[0].Ele.Ele;
expression.erase(expression.begin());
float Second_Operand = factor(expression[0]);
expression.erase(expression.begin());
Left_Operand = opearte(Operator, Left_Operand, Second_Operand);
}
else {
Result=Left_Operand;
return 0;
}
}
else {
string Operator = *expression[0].Ele.Ele;
expression.erase(expression.begin());
float Second_Operand = factor(expression[0]);
expression.erase(expression.begin());
Left_Operand = opearte(Operator, Left_Operand, Second_Operand);
Result = Left_Operand;
return 0;
}
}
}
float factor(N_Vector<string> Node) {
if (Node.DataType_Id == NonPtType)
return atof(Node.Ele.Ele->c_str());
else {
float tmp;
eval(*Node.Ele.ElePt, tmp);
return tmp;
}
}
float opearte(string& Operator,float Left_op, float Right_op) {
if (Operator == "+") {
return Left_op + Right_op;
}
else if (Operator == "-"){
return Left_op - Right_op;
}
else if (Operator == "*") {
return Left_op * Right_op;
}
else if (Operator == "/") {
return Left_op / Right_op;
}
else if (Operator == "%") {
return (int)Left_op % (int)Right_op;
}
else if (Operator == "**") {
return powf(Left_op,Right_op);
}
else if (Operator == "//") {
return powf(Left_op, 1 / Right_op);
}
return 0;
}
protected:
int eval(vector<N_Vector<string>>& expression,float& Result) {
float First_Operand;
if (term(expression, First_Operand))
return -1;
while (expression.size())
{
if (expression[0].DataType_Id == PtType || GetPriority(*expression[0].Ele.Ele)) {
printf("Something Wrong!\n");
}
string Operator = *expression[0].Ele.Ele;
expression.erase(expression.begin());
float Second_Operand;
if (term(expression, Second_Operand))
return -1;
First_Operand = opearte(Operator, First_Operand, Second_Operand);
}
Result= First_Operand;
return 0;
}
const vector<char> ElementChar = { '+','-','*','/',' ','(',')','%' };
const vector<vector<string>> Operator = { {"+","-"},{"*","/","%"},{"**","//"} };
string Input;
bool Debug=1;
vector<string> Token;
vector<N_Vector<string>> Syntax_Tree;
float Output;
int tokenizer() {
for (int i = 0; i < Input.length(); i++) {
string TmpStr;
if (!(find(ElementChar.begin(), ElementChar.end(), Input[i]) != ElementChar.end() || (Input[i]>='0' && Input[i]<='9'))) {
printf("No such element at poz %d", i);
return -1;
}
else if (Input[i] == ' ') {
}
else if (Input[i] >= '0' && Input[i] <= '9') {
TmpStr.push_back(Input[i]);
for (i++; Input[i] >= '0' && Input[i] <= '9'; i++)
{
TmpStr.push_back(Input[i]);
}
i--;
}
else if (Input[i] == '/' || Input[i] == '*') {
char OriginCode = Input[i];
TmpStr.push_back(Input[i]);
for (i++; Input[i] ==OriginCode; i++)
{
TmpStr.push_back(Input[i]);
}
i--;
}
else {
TmpStr.push_back(Input[i]);
}
if (TmpStr.size()) {
Token.push_back(TmpStr);
}
}
return 0;
}
int parser(bool IsSubExp,vector<N_Vector<string>>& Vector) {
while (Token.size())
{
string* TmpStr = new string;
string Token_0 = Token[0];
Token.erase(Token.begin());
if (Token_0 == "(") {
vector<N_Vector<string>>* SubExp = new vector<N_Vector<string>>;
if (parser(true,*SubExp)) {
return -1;
}
Vector.push_back(N_Vector<string>(PtType, (void*)SubExp));
continue;
}
if (IsSubExp) {
if (Token_0 == ")") {
if(!Vector.size()) {
printf("Empty ()!\n");
return -1;
}
else {
//Vector.push_back(N_Vector<string>(NonPtType, (void*)TmpStr));
return 0;
}
}
}
else {
if (Token_0 == ")") {
printf("surplus )!\n");
return -1;
}
}
*TmpStr = Token_0;
Vector.push_back(N_Vector<string>(NonPtType, (void*)TmpStr));
}
if (IsSubExp) {
printf("Missing )!\n");
return -1;
}
return 0;
}
public:
int Cal(string Input) {
Token.clear();
Syntax_Tree.clear();
Output = 0;
this->Input.clear();
if (!Input.length())
return -1;
this->Input = Input;
if (tokenizer()) {
return -1;
}
if (Debug) {
cout << "The Input Is:" << Input << endl;
Show_StrVector(Token, "Token:");
}
if (parser(false,this->Syntax_Tree)) {
return -1;
}
if (Debug) {
cout << "The Syntax Tree is:" << endl;
Show_SyxTree(Syntax_Tree);
cout << endl;
}
if (eval(Syntax_Tree, Output)) {
return -1;
}
if (Debug) {
cout << "The Result is:" << Output << endl;
}
return 0;
}
};
结果:
----------------------------------------------------
The Input Is:1+ 2*3
Token:'1','+','2','*','3',
The Syntax Tree is:
'1','+','2','*','3',
The Result is:7
----------------------------------------------------
----------------------------------------------------
The Input Is:(1 + 2) * 3
Token:'(','1','+','2',')','*','3',
The Syntax Tree is:
{'1','+','2',}'*','3',
The Result is:9
----------------------------------------------------
----------------------------------------------------
The Input Is:106 + 7 * (5 - 2)
Token:'106','+','7','*','(','5','-','2',')',
The Syntax Tree is:
'106','+','7','*',{'5','-','2',}
The Result is:127
----------------------------------------------------
----------------------------------------------------
The Input Is:(((3+2)*3)*5-7) - (6 *(3+8)/2)
Token:'(','(','(','3','+','2',')','*','3',')','*','5','-','7',')','-','(','6','*','(','3','+','8',')','/','2',')',
The Syntax Tree is:
{{{'3','+','2',}'*','3',}'*','5','-','7',}'-',{'6','*',{'3','+','8',}'/','2',}
The Result is:35
----------------------------------------------------
----------------------------------------------------
The Input Is:() + 66
Token:'(',')','+','66',
Empty ()!
----------------------------------------------------
----------------------------------------------------
The Input Is:4*5**2
Token:'4','*','5','**','2',
The Syntax Tree is:
'4','*','5','**','2',
The Result is:100
----------------------------------------------------
----------------------------------------------------
The Input Is:5**2*4
Token:'5','**','2','*','4',
The Syntax Tree is:
'5','**','2','*','4',
The Result is:100
----------------------------------------------------
这个用C++重写的计算器在词法分析和语法分析部分和老师给的思路是一致的,不过在词法分析部分增加了词法错误的检测。另外在执行语法树方面改进的部分较多。
存储语法树的数据结构
可以看到在Python中,Syntax Tree是一个列表,而Python中的列表是可以存储不同元素的,而在c++中一个数组(向量)只能存储一个元素,所以必须要自己创建一个N维数组类来支持子表达式的需求:
struct N_Vector{
int DataType_Id;
union
{
vector<N_Vector<T>>* ElePt;
T* Ele;
}Ele;
N_Vector(int Id, void* Ele) {
this->DataType_Id = Id;
if (Id == PtType)
this->Ele.ElePt = (vector<N_Vector<T>>*)Ele;
else
this->Ele.Ele = (T*)Ele;
}
};
更新后的eval函数
让我们先来思考一个事情,如果我们要支持多优先级计算,要怎么做呢?首先抽象出所有表达式的共同表达式:od1 op1 od2 op2 od3 op3 ....,其中任意一个operand(操作数)都可以是一个子表达式的计算结果,因此上述表达式可以等价为od1 op1 od2 op2 od3,现在来考虑两种情况:
- Priority(op1)>=Priority(op2):这种情况的一种例子是1**3*6+2,这种情况下需要优先计算
op1(od1,od2),然后再计算后面的部分。 - Priority(op1)<Priority(op2):这种情况的一个例子是1+3*6,这种情况下,我们可以将
od2 op2 od3用括号括起来,组成一个子表达式,此时表达式就缩减为od1 op1 (od2)。
根据上述考虑的情况,题主修改了term函数:
int term(vector<N_Vector<string>>& expression,float& Result) {
float Left_Operand = factor(expression[0]);
expression.erase(expression.begin());
while (expression.size())
{
if (expression.size() > 2) {
if ((GetPriority(*expression[0].Ele.Ele) < 0 || GetPriority(*expression[2].Ele.Ele) < 0)) {
printf("%s Should be a Operator\n", *expression[0].Ele.Ele);
return -1;
}
if ((GetPriority(*expression[0].Ele.Ele) >= GetPriority(*expression[2].Ele.Ele))) {
string Operator = *expression[0].Ele.Ele;
expression.erase(expression.begin());
float Second_Operand = factor(expression[0]);
expression.erase(expression.begin());
Left_Operand = opearte(Operator, Left_Operand, Second_Operand);
}
else {
Result=Left_Operand;
return 0;
}
}
else {
string Operator = *expression[0].Ele.Ele;
expression.erase(expression.begin());
float Second_Operand = factor(expression[0]);
expression.erase(expression.begin());
Left_Operand = opearte(Operator, Left_Operand, Second_Operand);
Result = Left_Operand;
return 0;
}
}
}
并在eval函数中将循环条件的一部分舍去:
//c++
expression.size()
#python
while list_checker(syntree) and syntree[0] in '+-':















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









