






1. 概述
在GeoMesa当中,由于大量需要与内存交互以及网络传输,因此序列化的过程也就必不可少了。与很多大数据的框架一样,鉴于Java原生的序列化机制会造成大量的数据冗余,而且序列化的时间也比较长,因此GeoMesa同样采用了一些序列化框架来解决这个问题。
对于序列化框架的选择,原生的GeoMesa采用了两种选择,一种是avro框架,这个框架是hadoop生态的很多框架所通用的一种框架,因此在与hdfs、hbase进行网络通信的时候会有比较好的兼容性;另一种是kryo框架,也是GeoMesa默认的一种对value值进行序列化的一种框架。
object SerializationType extends Enumeration {
type SerializationType = Value
val KRYO: Value = Value("kryo")
val AVRO: Value = Value("avro")
} 对于数据进行序列化的过程主要分为两大部分:对于SimpleFeatureType的序列化过程、对SimpleFeature的序列化过程。
2 序列化流程
2.1 流程概述
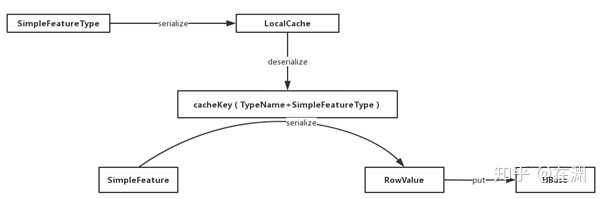
首先,在利用GeoMesa进行数据的写入和查询的过程当中,一般直接操作的都是SimpleFeature对象。那么如何判定这些SimpleFeature对象是不是需要共用一个连接,插入到一个存储空间内呢?这个过程GeoMesa是利用了在本地的一个缓存LocalCache来进行控制的。
在我们写入SimpleFeatureType信息的时候,GeoMesa会利用序列化机制,将SimpleFeatureType里面封装的属性结构信息利用序列化器进行序列化,存储在本地的缓存(localCache)当中。当我们需要写入或者查询数据时,GeoMesa会将本地缓存当中的SimpleFeatureType相关的信息反序列化出来与SimpleFeature当中的SimpleFeatureType信息进行比对。这样就可以保证始终有一个全局的schema来控制表结构的信息。
而对于SimpleFeature的序列化过程主要使用的是Kryo框架,通过将FeatureId和各个属性信息转换成为字节数组,作为Value值存储进RowValue对象当中,最终存储进Hbase当中。
2.2 基本流程
2.2.1 SimpleFeatureType的序列化
对于SimpleFeatureType的序列化过程其实没有出现在写入SimpleFeature的过程当中,而是当创建FeatureWriter时就进行了创建。如下代码当中,第二行就是创建FeatureWriter的过程。可以看到,此时并没有传入SimpleFeature的参数,仅仅是将SimpleFeatureType的TypeName和事务的配置传入FeatureWriter对象当中。结合前面创建datastore的过程可以知道,此时SimpleFeatureType的全量信息都已经被传入到了datastore当中,因此可以看出这一步是只与SimpleFeatureType相关的,与SimpleFeature没有关系。
private void writeFeature(DataStore datastore, SimpleFeatureType sft, SimpleFeature feature) throws IOException {
try (FeatureWriter<SimpleFeatureType, SimpleFeature> writer = datastore.getFeatureWriterAppend(sft.getTypeName(), Transaction.AUTO_COMMIT)) {
System.out.println("write test data");
SimpleFeature toWrite = writer.next();
toWrite.setAttributes(feature.getAttributes());
if (toWrite.getIdentifier() instanceof FeatureIdImpl) {
((FeatureIdImpl) toWrite.getIdentifier()).setID(feature.getID());
}
toWrite.getUserData().put(Hints.USE_PROVIDED_FID, Boolean.TRUE);
toWrite.getUserData().putAll(feature.getUserData());
writer.write();
}
} 接下来就是整个对于SimpleFeatureType的序列化过程:
- 序列化的引入阶段
- 序列化参数的配置
- 构造序列化器
(1)序列化的引入阶段
由于序列化过程是非常底层的一个过程,因此往往会有很深的调用过程,在此对这个过程进行简单的介绍。首先从Demo的代码当中可以看出,我们调用的是org.locationtech.geomesa.index.geotools.GeoMesaDataStore类中的getFeatureWriterAppend方法。
override def getFeatureWriterAppend(typeName: String, transaction: Transaction): FlushableFeatureWriter = {
val sft = getSchema(typeName)
if (sft == null) {
throw new IOException(s"Schema '$typeName' has not been initialized. Please call 'createSchema' first.")
}
if (transaction != Transaction.AUTO_COMMIT) {
logger.warn("Ignoring transaction - not supported")
}
featureWriterFactory.createFeatureWriter(sft, manager.indices(sft, mode = IndexMode.Write), None)
} 这个方法主要完成了对schema和事务的操作,最后将这些操作的结果封装在FeatureWirter对象当中回传给用户。其中与我们序列化过程有关的是第9行的代码,这一行调用了org.locationtech.geomesa.hbase.data.HBaseFeatureWriter.HBaseFeatureWriterFactory类中的createFeatureWriter方法。
override def createFeatureWriter(sft: SimpleFeatureType,
indices: Seq[HBaseFeatureIndexType],
filter: Option[Filter]): FlushableFeatureWriter = {
(TablePartition(ds, sft), filter) match {
case (None, None) =>
new HBaseFeatureWriter(sft, ds, indices, null, null)
with HBaseTableFeatureWriterType with HBaseAppendFeatureWriterType
case (None, Some(f)) =>
new HBaseFeatureWriter(sft, ds, indices, f, null)
with HBaseTableFeatureWriterType with HBaseModifyFeatureWriterType
case (Some(p), None) =>
new HBaseFeatureWriter(sft, ds, indices, null, p)
with HBasePartitionedFeatureWriterType with HBaseAppendFeatureWriterType
case (Some(p), Some(f)) =>
new HBaseFeatureWriter(sft, ds, indices, f, p)
with HBasePartitionedFeatureWriterType with HBaseModifyFeatureWriterType
}
}
}在这里我们可以看到,GeoMesa在此进行了一个匹配的过程,但是每一个分支的结果都是创建了一个HbaseFeatureWriter对象。
abstract class HBaseFeatureWriter(val sft: SimpleFeatureType,
val ds: HBaseDataStore,
val indices: Seq[HBaseFeatureIndexType],
val filter: Filter,
val partition: TablePartition) extends HBaseFeatureWriterType {
private val wrapper = HBaseFeature.wrapper(sft)在创建HbaseFeatureWriter对象时,我们可以在这个类当中看到,在这个对象当中有一个参数wrapper,调用 org.locationtech.geomesa.hbase.data.HBaseFeature伴生对象当中的wrapper方法。
def wrapper(sft: SimpleFeatureType): (SimpleFeature) => HBaseFeature = {
val serializers = HBaseColumnGroups.serializers(sft)
val idSerializer = GeoMesaFeatureIndex.idToBytes(sft)
(feature) => new HBaseFeature(feature, serializers, idSerializer)
} 在这个方法中,才真正开始根据Hbase这种datastore与序列化器进行匹配,从上述代码的第2行可以看出调用了org.locationtech.geomesa.index.conf.ColumnGroups特性当中的serializers方法。
def serializers(sft: SimpleFeatureType): Seq[(T, SimpleFeatureSerializer)] = {
apply(sft).map { case (colFamily, subset) =>
if (colFamily.eq(default)) {
(colFamily, KryoFeatureSerializer(subset, SerializationOptions.withoutId))
} else {
(colFamily, new ProjectingKryoFeatureSerializer(sft, subset, SerializationOptions.withoutId))
}
}
} 经过了上述这些复杂的调用过程,才真正进入到了对于SimpleFeatureType的序列化过程。
(2)序列化参数的配置
接着上文的方法调用过程,接下来实现序列化的是org.locationtech.geomesa.index.conf.ColumnGroups伴生对象的apply方法。
从这段代码可以看出,这个方法主要分为三个部分,一开始进行了各种参数的准备,之后就是对于这些参数的封装过程,最后将这些封装好的参数放入缓存当中。
def apply(sft: SimpleFeatureType): Seq[(T, SimpleFeatureType)] = {
val key = CacheKeyGenerator.cacheKey(sft)
var groups = cache.getIfPresent(key)
if (groups == null) {
val map = scala.collection.mutable.Map.empty[String, SimpleFeatureTypeBuilder]
sft.getAttributeDescriptors.asScala.foreach { descriptor =>
descriptor.getColumnGroups().foreach { group =>
map.getOrElseUpdate(group, new SimpleFeatureTypeBuilder()).add(descriptor)
}
}
val sfts = map.map { case (group, builder) =>
builder.setName(sft.getTypeName)
val subset = builder.buildFeatureType()
subset.getUserData.putAll(sft.getUserData)
(convert(group), subset)
} + (default -> sft)
// return the smallest groups first
groups = sfts.toSeq.sortBy(_._2.getAttributeCount)
cache.put(key, groups)
}
groups
}首先,在参数准备阶段,程序对于传入的key值进行了判断,此处的key不是全部的schema信息,而是SimpleFeatureType的名称以及各个字段的信息。例如在demo当中,此处的key值内容是“index-text02;taxiId:String,dtg:Date,geom:Point,description:String”。
然后就是根据这个key值从缓存当中获取相应的对象,这个过程会调用com.github.benmanes.caffeine.cache.LocalManualCache类中的getIfPresent方法。
@Override
default @Nullable V getIfPresent(Object key) {
return cache().getIfPresent(key, /* recordStats */ true);
} 进一步,程序会调用com.github.benmanes.caffeine.cache.BoundedLocalCache类中的getIfPresent方法。
@Override
public V getIfPresent(Object key, boolean recordStats) {
Node<K, V> node = data.get(nodeFactory.newLookupKey(key));
if (node == null) {
if (recordStats) {
statsCounter().recordMisses(1);
}
return null;
}
long now = expirationTicker().read();
if (hasExpired(node, now)) {
if (recordStats) {
statsCounter().recordMisses(1);
}
scheduleDrainBuffers();
return null;
}
@SuppressWarnings("unchecked")
K castedKey = (K) key;
V value = node.getValue();
if (!isComputingAsync(node)) {
setVariableTime(node, expireAfterRead(node, castedKey, value, now));
setAccessTime(node, now);
}
afterRead(node, now, recordStats);
return value;
}之后返回apply方法以后,程序会判断获取到的对象是不是空值,如果获取到的是个空值,说明在缓存当中是没有key值对应的信息的,这个时候就会根据传入的SimpleFeatureType进行一些操作。
if (groups == null) {
val map = scala.collection.mutable.Map.empty[String, SimpleFeatureTypeBuilder]
sft.getAttributeDescriptors.asScala.foreach { descriptor =>
descriptor.getColumnGroups().foreach { group =>
map.getOrElseUpdate(group, new SimpleFeatureTypeBuilder()).add(descriptor)
}
} 参数sfts其实是一个tuple,其中第一个元素就是列族名的字节表达,第二个元素是一个SimpleFeatureTypeImpl,也就是SimpleFeatureType的实现类的对象。之后这个tuple就会被封装进groups内。这个groups最终会被放进缓存当中。
val sfts = map.map { case (group, builder) =>
builder.setName(sft.getTypeName)
val subset = builder.buildFeatureType()
subset.getUserData.putAll(sft.getUserData)
(convert(group), subset)
} + (default -> sft)
groups = sfts.toSeq.sortBy(_._2.getAttributeCount)
cache.put(key, groups) (3)构造序列化器
接下来进行序列化器的构造,在这里有四种序列化器,分别是可变的延迟加载序列化器、可变的活跃序列化器、不变的延迟加载序列化器、不变的活跃序列化器。调用的是org.locationtech.geomesa.features.kryo.KryoFeatureSerializer伴生对象的apply方法,可以看出最终创建了不同的序列化器对象。
def apply(sft: SimpleFeatureType, options: Set[SerializationOption] = Set.empty): KryoFeatureSerializer = {
(options.immutable, options.isLazy) match {
case (true, true) => new ImmutableLazySerializer(sft, options)
case (true, false) => new ImmutableActiveSerializer(sft, options)
case (false, true) => new MutableLazySerializer(sft, options)
case (false, false) => new MutableActiveSerializer(sft, options)
}
} 2.2.2 SimpleFeature的序列化
具体负责将SimpleFeature进行序列化的过程在org.locationtech.geomesa.features.kryo.impl.KryoFeatureSerialization类的writeFeature方法中实现,如下:
private def writeFeature(sf: SimpleFeature, output: Output): Unit = {
val offsets = KryoFeatureSerialization.getOffsets(cacheKey, writers.length)
val offset = output.position()
output.writeInt(VERSION, true)
output.setPosition(offset + 5) // leave 4 bytes to write the offsets
if (withId) {
// TODO optimize for uuids?
output.writeString(sf.getID)
}
// write attributes and keep track off offset into byte array
var i = 0
while (i < writers.length) {
offsets(i) = output.position() - offset
writers(i)(output, sf.getAttribute(i))
i += 1
}
// write the offsets - variable width
i = 0
val offsetStart = output.position() - offset
while (i < writers.length) {
output.writeInt(offsets(i), true)
i += 1
}
// got back and write the start position for the offsets
val end = output.position()
output.setPosition(offset + 1)
output.writeInt(offsetStart)
// reset the position back to the end of the buffer so the bytes aren't lost, and we can keep writing user data
output.setPosition(end)
if (withUserData) {
KryoUserDataSerialization.serialize(output, sf.getUserData)
}
}从这段代码可以看出,SimpleFeature的序列化过程可以分成如下几个部分:
- 序列化版本号和FeatureId(第2行到第9行)
- 序列化各个属性值(第10行到第16行)
- 序列化属性的偏移量(第17行到第29行)
- 序列化用户设置的参数(第31行到第33行)
接下来就对各个部分进行介绍。
(1)序列化版本号和FeatureId
首先,GeoMesa会创建一个容量为1024的字节数组 ,会将此时的版本号进行序列化以后放在第一个位置。这个地方用到了Kryo框架当中的可变长机制,虽然数据类型是Int类型,正常应该占用4个字节的长度,但是在此处,程序会对这个数据进行判断,如果这个数据是否能用少量的字节数表达,将冗余的位数进行忽略。例如:在GeoMesa当中默认的版本号是2,如果按照通常的方式,需要四个字节来进行存储:00000000 00000000 00000000 00000010,而在此处由于这种机制的存在,只需要用一个字节来进行存储:00000010,这样就能够大量的节省存储资源。
接着,缓冲区的游标会向后调整5位,因为在value设计时,从第2位到第5位预留出来,用来存储各个属性的偏移量的数据。从第6位开始写入FeatureId。结合此处的源码,可以看出FeatureId本身的序列化使用的是原生的针对String类型的序列化机制。
val offsets = KryoFeatureSerialization.getOffsets(cacheKey, writers.length)
val offset = output.position()
output.writeInt(VERSION, true)
output.setPosition(offset + 5) // leave 4 bytes to write the offsets
if (withId) {
output.writeString(sf.getID)
} (2)序列化各个属性值
接下来,系统开始对SimpleFeature当中的属性进行遍历,将这些属性分别进行序列化。
var i = 0
while (i < writers.length) {
offsets(i) = output.position() - offset
writers(i)(output, sf.getAttribute(i))
i += 1
} 在遍历的过程当中,对于每一个属性值,根据这些属性的不同类型,GeoMesa会进行类型匹配,分配给不同的序列化器来进行序列化。具体的过程实现是org.locationtech.geomesa.features.kryo.impl.KryoFeatureSerialization类中的matchWriter方法
private [geomesa] def matchWriter(bindings: Seq[ObjectType], descriptor: AttributeDescriptor): (Output, AnyRef) => Unit = {
import org.locationtech.geomesa.utils.geotools.RichAttributeDescriptors.RichAttributeDescriptor
bindings.head match {
case ObjectType.STRING =>
(o: Output, v: AnyRef) => o.writeString(v.asInstanceOf[String]) // write string supports nulls
case ObjectType.INT =>
val w = (o: Output, v: AnyRef) => o.writeInt(v.asInstanceOf[Int])
writeNullable(w)
case ObjectType.LONG =>
val w = (o: Output, v: AnyRef) => o.writeLong(v.asInstanceOf[Long])
writeNullable(w)
case ObjectType.FLOAT =>
val w = (o: Output, v: AnyRef) => o.writeFloat(v.asInstanceOf[Float])
writeNullable(w)
case ObjectType.DOUBLE =>
val w = (o: Output, v: AnyRef) => o.writeDouble(v.asInstanceOf[Double])
writeNullable(w)
case ObjectType.BOOLEAN =>
val w = (o: Output, v: AnyRef) => o.writeBoolean(v.asInstanceOf[Boolean])
writeNullable(w)
case ObjectType.DATE =>
val w = (o: Output, v: AnyRef) => o.writeLong(v.asInstanceOf[Date].getTime)
writeNullable(w)
case ObjectType.UUID =>
val w = (o: Output, v: AnyRef) => {
val uuid = v.asInstanceOf[UUID]
o.writeLong(uuid.getMostSignificantBits)
o.writeLong(uuid.getLeastSignificantBits)
}
writeNullable(w)
case ObjectType.GEOMETRY =>
// null checks are handled by geometry serializer
descriptor.getPrecision match {
case GeometryPrecision.FullPrecision =>
(o: Output, v: AnyRef) => KryoGeometrySerialization.serializeWkb(o, v.asInstanceOf[Geometry])
case precision: GeometryPrecision.TwkbPrecision =>
(o: Output, v: AnyRef) => KryoGeometrySerialization.serialize(o, v.asInstanceOf[Geometry], precision)
}
case ObjectType.JSON =>
(o: Output, v: AnyRef) => KryoJsonSerialization.serialize(o, v.asInstanceOf[String])
case ObjectType.LIST =>
val valueWriter = matchWriter(bindings.drop(1), descriptor)
(o: Output, v: AnyRef) => {
val list = v.asInstanceOf[java.util.List[AnyRef]]
if (list == null) {
o.writeInt(-1, true)
} else {
o.writeInt(list.size(), true)
val iter = list.iterator()
while (iter.hasNext) {
valueWriter(o, iter.next())
}
}
}
case ObjectType.MAP =>
val keyWriter = matchWriter(bindings.slice(1, 2), descriptor)
val valueWriter = matchWriter(bindings.drop(2), descriptor)
(o: Output, v: AnyRef) => {
val map = v.asInstanceOf[java.util.Map[AnyRef, AnyRef]]
if (map == null) {
o.writeInt(-1, true)
} else {
o.writeInt(map.size(), true)
val iter = map.entrySet.iterator()
while (iter.hasNext) {
val entry = iter.next()
keyWriter(o, entry.getKey)
valueWriter(o, entry.getValue)
}
}
}
case ObjectType.BYTES =>
(o: Output, v: AnyRef) => {
val arr = v.asInstanceOf[Array[Byte]]
if (arr == null) {
o.writeInt(-1, true)
} else {
o.writeInt(arr.length, true)
o.writeBytes(arr)
}
}
}
}从上面的代码可以看出,在进行属性序列化的过程中,程序会首先对数据进行类型匹配,这些类型有基本数据类型:String、Int、Float、Double、Boolean,还有特殊数据类型:Date、Geometry、UUID、Json,还有集合数据类型:List、Map。由于大部分数据类型的序列化方式比较简单,在此不再赘述。其中比较特殊的是Geometry的序列化方式比较特殊,在此对地理信息的数据类型进行详细介绍。
在前面的matchWriter方法当中,可以看出在进行类型匹配时,对于地理相关的信息,统一归类为Geometry类型。如果我们需要序列化的数据为Point、Linestring等等这些具体的地理类型,则由org.locationtech.geomesa.features.serialization.WkbSerialization类中的serializeWkb方法来进行进一步的类型匹配。
def serializeWkb(out: T, geometry: Geometry): Unit = {
if (geometry == null) { out.writeByte(NULL_BYTE) } else {
out.writeByte(NOT_NULL_BYTE)
geometry match {
case g: Point => writePoint(out, g)
case g: LineString => writeLineString(out, g)
case g: Polygon => writePolygon(out, g)
case g: MultiPoint => writeGeometryCollection(out, WkbSerialization.MultiPoint, g)
case g: MultiLineString => writeGeometryCollection(out, WkbSerialization.MultiLineString, g)
case g: MultiPolygon => writeGeometryCollection(out, WkbSerialization.MultiPolygon, g)
case g: GeometryCollection => writeGeometryCollection(out, WkbSerialization.GeometryCollection, g)
}
}
}在上述代码当中,可以看出,GeoMesa对于地理信息类型又分为Point、LineString、Polygon、MultiPoint、MultiLineString、MultiPolygon、GeometrCollection这些类型。在进一步的序列化过程中,针对不同的类型,有不同的序列化方法与之对应。这些方法都存在于org.locationtech.geomesa.features.serialization.WkbSerialization类中。为了介绍简便,在此以writePoint方法为例。
private def writePoint(out: T, g: Point): Unit = {
val coords = g.getCoordinateSequence
val (flag, writeDims) = if (coords.getDimension == 2) { (Point2d, false) } else { (Point, true) }
out.writeInt(flag, optimizePositive = true)
writeCoordinateSequence(out, coords, writeLength = false, writeDims)
} 首先,GeoMesa会对point类型数据进行转化,调用org.locationtech.jts.geom.Point类中的getCoordinateSequence方法,将Point的WKT形式转换为Coordinate对象。例如:原来的“POINT (116.31412 39.89454)”转换为coordinates=” ((116.31412, 39.89454, NaN))”。其中NaN其实表示的是高度信息,由于在此处没有高度信息,因此显示为NaN。
public CoordinateSequence getCoordinateSequence() {
return coordinates;
} 返回到writePoint方法中,接下来会对点的维度进行判断,如果是二维的点,就会设定flag参数为1,如果是多维的点,就会设定flag参数为8。
val (flag, writeDims) = if (coords.getDimension == 2) { (Point2d, false) } else { (Point, true) } 在这段代码当中可以看到程序对flag进行了赋值,这个值就是关于地理信息的参数,这些关于点的参数配置在org.locationtech.geomesa.features.serialization.WkbSerialization当中。
object WkbSerialization {
val Point2d: Int = 1
val LineString2d: Int = 2
val Polygon2d: Int = 3
val MultiPoint: Int = 4
val MultiLineString: Int = 5
val MultiPolygon: Int = 6
val GeometryCollection: Int = 7
val Point: Int = 8
val LineString: Int = 9
val Polygon: Int = 10
}最后对于经纬度数据的序列化过程在WkbSerialization类的writeCoordinateSequence方法当中。下列代码的第13行到21行会对点数据内部的参数进行遍历,根据点的维度来控制遍历的次数,最后分维度来将不同维度的数据进行序列化。
private def writeCoordinateSequence(out: T,
coords: CoordinateSequence,
writeLength: Boolean,
writeDimensions: Boolean): Unit = {
val dims = coords.getDimension
if (writeLength) {
out.writeInt(coords.size(), optimizePositive = true)
}
if (writeDimensions) {
out.writeInt(dims, optimizePositive = true)
}
var i = 0
while (i < coords.size()) {
val coord = coords.getCoordinate(i)
var j = 0
while (j < dims) {
out.writeDouble(coord.getOrdinate(j))
j += 1
}
i += 1
}
}接下来,返回到writeFeature方法中,进行下一步的操作。
(3)序列化属性的偏移量
当完成各个属性值的序列化以后,系统虽然已经将各个属性值序列化成字节数组,但是它现在并不知道每个属性值都是从什么位置开始序列化的。为了解决这个问题,回到之前的writeFeature方法之后,GeoMesa开始对每个属性的偏移量进行序列化。具体实现过程如下:
i = 0
val offsetStart = output.position() - offset
while (i < writers.length) {
output.writeInt(offsets(i), true)
i += 1
}
val end = output.position()
output.setPosition(offset + 1)
output.writeInt(offsetStart)
output.setPosition(end) (4)序列化用户设置的参数
在很多情况下,用户都需要对SimpleFeature进行一系列的设置,这些设置一般都会存在于SimpleFeature对象中的userData属性当中。在序列化的过程中,如果SimpleFeature对象当中存在这些用户设置的信息,我们同样需要对这些信息进行序列化。
if (withUserData) {
KryoUserDataSerialization.serialize(output, sf.getUserData)
} 此处会调用针对UserData的序列化方法,具体的实现存在于org.locationtech.geomesa.features.kryo.serialization.KryoUserDataSerialization类的serialize方法当中。
override def serialize(out: Output, javaMap: java.util.Map[AnyRef, AnyRef]): Unit = {
import scala.collection.JavaConverters._
val map = javaMap.asScala
// may not be able to write all entries - must pre-filter to know correct count
val skip = new java.util.HashSet[AnyRef]()
map.foreach { case (k, _) => if (k == null || !canSerialize(k)) { skip.add(k) } }
val toWrite = if (skip.isEmpty) { map } else {
logger.warn(s"Skipping serialization of entries: " +
map.collect { case (k, v) if skip.contains(k) => s"$k->$v" }.mkString("[", "],[", "]"))
map.filterNot { case (k, _) => skip.contains(k) }
}
out.writeInt(toWrite.size) // don't use positive optimized version for back compatibility
toWrite.foreach { case (key, value) =>
out.writeString(baseClassMappings.getOrElse(key.getClass, key.getClass.getName))
write(out, key)
if (value == null) {
out.writeString(nullMapping)
} else {
out.writeString(baseClassMappings.getOrElse(value.getClass, value.getClass.getName))
write(out, value)
}
}
}3. 序列化机制的配置方法
3.1 序列化器的配置方法
从前文可以知道,在进行创建序列化器时,需要对一些参数进行配置,那我们在进行二次开发的时候就需要根据具体的业务场景来对这些序列化器的机制进行进一步的了解,根据业务来创建不同类型的序列化器。
3.1.1 序列化器的创建方法
创建序列化器的方法主要有两种,一种就是通过用户传参数来决定序列化器的类型,另一种就是直接指定序列化器的种类。在阅读源码的过程中,我们了解到,GeoMesa支持Avro和Kryo两种序列化机制,因此在创建时,就需要选择具体使用哪种序列化的机制来进行数据的序列化。
如果我们在开发时不确定具体使用哪种序列化机制,可以通过直接创建SimpleFeatureSerializers的伴生对象来创建,在传参时需要传入SimpleFeawtureType和序列化机制的参数。最终获得哪种序列化器取决于此处传入哪种序列化机制的参数。
val avro = SimpleFeatureSerializers(sft, SerializationType.AVRO)
val kryo = SimpleFeatureSerializers(sft, SerializationType.KRYO) 另一方面,如果我们比较确定要用到哪种序列化的机制,也可以直接创建这种序列化机制对应的序列化器。代码如下:
val avro = new AvroFeatureSerializer(sft)
val kryo = new KryoFeatureSerializer(sft) 3.1.2 序列化器的操作参数
同样我们也可以对序列化器的操作进行一些设置,具体的方法如下:
val avro = SimpleFeatureDeserializers(sft, SerializationType.AVRO, opts)
val kryo = SimpleFeatureDeserializers(sft, SerializationType.KRYO, opts) 此处的opts参数就是需要设定的一些操作参数。具体可以设置的操作参数如下:
opts = SerializationOption.none
opts = SerializationOption.WithUserData
opts = SerializationOption.WithoutId
opts = SerializationOption.Immutable
opts = SerializationOption.Lazy 如果设置成none,说明此处创建的序列化器没有任何特殊的操作;如果设置成withUserData,说明序列化的过程当中需要将UserData进行序列化并添加在value字节数组的末尾;如果设置成WithoutId,说明序列化的过程当中不会在value的字节数组当中存放Id的数据;如果设置成Immutable,说明这个序列化器的配置是可能变化的,具体到这里主要是SimpleFeatureType和配置参数可能会变化;如果设置成Lazy,说明这个序列化器是延迟加载的,只有需要调用序列化时,才会创建序列化器的对象。
3.2 SImpleFeature的映射机制
由于在GeoMesa当中往往存储的都是全量的时空数据,这样在查询的过程当中,往往会返回很多不需要的字段信息。为了解决这个问题,GeoMesa提供了SimpleFeature的映射机制,我们可以通过较短的SimpleFeatureType来对数据进行提取,选择我们需要的少量的数据信息。具体代码示例如下:
// 创建两个SimpleFeatureType
val sft = SimpleFeatureTypes.createType(sftName, "name:String,*geom:Point,dtg:Date")
val projectedSft = SimpleFeatureTypes.createType("projectedTypeName", "*geom:Point")
// 创建序列化器和映射反序列化器
val encoder = new AvroFeatureSerializer(sft, SerializationOptions.withUserData)
val decoder = new ProjectingAvroFeatureDeserializer(sft, projectedSft, SerializationOptions.withUserData)
// 接受反序列化的结果
val features = getFeaturesWithVisibility
// 接受映射以后的结果
val encoded = features.map(encoder.serialize) 这样,虽然我们在存储的时候,我们根据SimpleFeatureType来创建的schema当中有3个字段的信息:name、geom、dtg,但是我们真正需要查询的只是一个geom信息,通过这种映射机制,就将单个字段的信息提取出来,反序列化以后的结果就是我们需要的数据了。















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









