






🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊专栏推荐:深度学习网络原理与实战
🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
HRNet源码解析篇
写在前面
Hello,大家好,我是小苏👦🏽👦🏽👦🏽
在上一节中,我已经为大家介绍HRNet的原理部分,其实说起来挺惭愧,因为原理部分介绍的还是比较简单的,我想你仅仅阅读原理部分是很难彻底弄明白HRNet的精髓。那么本节将在上一节的基础上,为大家更细致的讲解HRNet。🧨🧨🧨当然了,本节属于源码解析篇,所有会存在比较多的代码,大家也不用担心看不懂,我都对关键代码做了详细的解释,并画图进一步帮助大家理解,所以大家一定要耐心看下去喔。🎯🎯🎯
这里我还想多说一句,其实写源码解析类博客其实怪难的,因为有时候明明很好表达的内容,用文字为大家展示却有种一拳打在棉花上的无力感,哈哈哈,可能是自己水平不够叭。🧑🧑🧑自己也做过几期视频,感觉效果也还行,感兴趣的可以点击 ☞☞☞看看,后期可能会考虑写完博客出配套视频的方式为大家介绍知识点。enmmm,说远了,说这些我是想告诉大家,我并不期望通过这一篇文章就能让你把整个HRNet的源码都看透,这是不可能的。但是其中一些关键的地方,如果本文能给你一点启发,那我觉得此篇文章的目的就达到了。此外,大家在阅读代码时,一定不要停留在看的层面,一定要动手调试起来,这样会有不一样的收获。🍋🍋🍋
好了,不说废话了,让我们一起发车,来学学HRNet的源码叭~~~🚖🚖🚖
源码地址: HRNet源码🌱🌱🌱
关键点数据集构建
深度学习中数据才是王道,本文使用的是COCO数据集中的人体关键点检测数据集,对此数据集还不清楚的务必点击下面链接了解详情:
COCO数据集——关键点检测标注文件解析🌼🌼🌼
清楚COCO数据集的格式后,我们一起来看看是如何构建关键点数据集的?首先来说说这里的关键点数据集的构建主要干了什么?其实它就是把原始图像中对人体关键点标注过的图像记录了下来。
我们一点点的来看其是如何实现的,主要定义在CocoKeypoint类中:
上述代码主要展示了传入CocoKeypoint类中的参数,为后面阅读CocoKeypoint类中代码做准备,对本篇transforms不熟悉的可以稍后阅读本文的下一节–>在线数据增强。🥗🥗🥗
下面我们就一步步的来看看CocoKeypoint类到底干了什么?在__init__函数中,先初始化了一系列变量:
我们调试来看看这些值的结果:

这里我重点介绍一下self.coco = COCO(self.anno_path)这句代码,其传入的是self.anno_path参数,即人体关键点检测标注文件——'D://Dataset//coco2017\\annotations\\person_keypoints_train2017.json'我们跳入COCO函数内部调试一下:
首先设置一些字典变量来存储相关信息:
接着我们会打开标注文件路径并读取得到dataset:
我们来看看dataset的值:

dataset一共有五个字段的值,和我在COCO数据集——关键点检测标注文件解析这篇博客中介绍的是完全一致的。
接着调用createIndex方法为之前定义的字典变量赋值:
这段代码先是遍历数据集中的annotations标签,然后将其image_id作为键,标签作为值构建一个图像id到标签的字典imgToAnns,来看看其遍历一次的结果:

接着是将标签的id作为键,标签作为值构建一个字典,同样看看遍历一次的结果:

注意:这里的id和image_id不一样,image_id是图像的唯一标识,id是目标实例分配的唯一标识符,用于在数据集中唯一标识这个目标实例。一个图像中可能会有多个目标实列,即有多个人。
我们遍历完所有标签,看看imgToAnns和anns中有多少数据:


可以看到imgToAnns共有64115条数据,表示一共有64115张图像存在标注。anns共有262465条数据,表示一共有262465个标注目标实列,也就是标注了262465个人。那么为什么会存在这样的差异呢?因为不是每张图像都会有标注目标实列(一共118287张图像,有标注目标实列的有64115张),也不是每张存在标注目标实列的都只有一个标注目标实列(最少有一个,从imgToAnns数据图中可以看到,image_id为120021的图像有三个标注目标实列,说明标注了3个人,我们也可以来看看这张图像,看看是不是有3个人,如下:

)
接着这段代码是遍历数据集中的image图像,然后将id【注意:image中的id指的是image_id,而不是上文说的实列id】作为键,img图像作为值构建字典imgs,来看看遍历一次的结果:

然后来看看遍历完所有数据imgs的结果:

一共有118287条数据,这就是COCO训练集图片的数量。
这段代码是遍历数据集中的categories类别,然后将其id【注意:这里的id指类别的唯一标识符。在人体关键点检测中,这个id都是1,因为我们只会对人体进行标注,而person的类别标识符是1。】作为键,categories信息作为值构建cats字典,来看看遍历一次的结果:

enmmm,dataset中只有一条数据,只能遍历一次,因为只有一个类别id,即id=1。

这段代码同样遍历annotations标签,然后将 category_id【注意:这个是类别id,其为1】作为键,image_id作为值构建从类别id到图像id映射的字典 catToImgs,来看一次遍历的结果:

然后来看看遍历完所有数据的catToImgs字典:

一共有262465条数据,即表示有262465张图像有类别id 1(这里包括了重复的图像,比如一个图像中有3个人,那么这里就有三条数据,那么其实这里的262465表示一共标注了262465个person实列)
到这里我们的COCO(self.anno_path)函数的内容就介绍完啦,我们来看看self.coco的值,如下:

其实其就是COCO(self.anno_path)函数中那几个字典变量。
接着我们会把imgs的key进行排序,并转成列表:

然后通过det = self.coco将self.coco的值赋给det,并设置一个self.valid_person_list列表用于存储有效的人体关键点信息,并设置一个obj_idx记录目标实列个数。
最后执行下面的代码:
这段代码干了什么呢,我们一点点来分析:首先是遍历img_ids,第一次拿到第一个image_id=9:

此image_id对应图像如下:

然后执行img_info = self.coco.loadImgs(img_id)[0],loadImgs定义如下:
这个函数主要是根据img_id来加载图像,我们直接来看img_info的结果:

这显示了image_id=9的图像的信息。
接着是ann_ids = det.getAnnIds(imgIds=img_id)这句代码,getAnnIds函数如下:
我们注意来看一下这句:lists = [self.imgToAnns[imgId] for imgId in imgIds if imgId in self.imgToAnns],意思是遍历imgIds,然后判断imgId是否存在self.imgToAnns中,我们知道imgToAnns共有64115条数据,表示一共有64115张图像存在标注,也就是说只有存在人物的图像才存在标注,即只有图像存在人物,其imgId才会在imgToAnns中,而我们刚刚image_id=9的图像不存在人物,故lists=[]是空列表,后续返回值会是空列表。因此我们需要换一张存在人物的图像进行展示,当遍历至image_id=36时,图像出现人物,图像如下:

此时lists值如下,为这张图像的标注信息:

接着anns = list(itertools.chain.from_iterable(lists))是将将嵌套的列表(lists)展平成一个单层的列表。

后面的这几句都没起作用:
然后通过ids = [ann['id'] for ann in anns]获取到标注目标实列的id,并将其返回给ann_ids,其值如下:

接着是anns = det.loadAnns(ann_ids),将ann_ids传入loadAnns方法中,其定义如下:
这个函数主要通过ann_ids来加载标注信息,返回的anns如下:

接着是遍历anns,先检查ann[“category_id”] 是否为1并检查标注的keypoints关键点是否存在可见关键点。
然后从标注的bbox中获取xmin, ymin, w, h,并构建info信息,注意这里score不在ann中,其最后值为1。
然后将关键点的坐标和可见性分成两个变量表示并加入到info字典中,最后将info添加到self.valid_person_list中,并将obj_idx加1,表示多了一个目标实列 。
此循环代码结束,来看看self.valid_person_list.append的值:

【注意:这里的图像只有一个人物,如果图像中包含多个人物原理是一样的,会遍历图像中的各个人物,并把每个人物的信息存放到valid_person_list中】
当我们遍历完所有img_ids数据时,self.valid_person_list.append就存储了所有有效的人体关键点检测的相关信息,最后一共有149813个有效数据。

到这里,关键点检测数据集的构建部分就为大家介绍完了,这部分说难也算不上难,但我认为却是非常重要的一部分,希望大家好好消化一下。🍻🍻🍻
在线数据增强
enmmm,我想大家应该对数据增强有一定的了解叭,比如旋转、剪裁、水平翻转等等,在代码中通常使用transforms.xxx来实现,在之前的博客中,我为大家介绍过一些数据增强,如 Faster RCNN中为大家介绍了水平翻转。
这一小节我准备多花点时间来写,因为这部分有的地方是比较难理解,也是蛮重要的。话不多说,我们一起来看看HRNet中使用了哪些数据增强手段:
其训练集和测试集采用不同的数据增强手段,测试集使用的数据增强方法是训练集的子集,所以直接来看训练集中的方法就好了,一共有以下四个:
transforms.HalfBodytransforms.AffineTransformtransforms.RandomHorizontalFliptransforms.KeypointToHeatMap
注意: transforms.ToTensor和transforms.Normalize不属于数据增强,而是处于数据预处理,对这两个不熟悉的可以点击下面的链接了解详情:
pytorch中的transforms.ToTensor和transforms.Normalize理解🍁🍁🍁
下面我将来一个个的为大家介绍这四种数据增强方式,快来和我一起学学叭~~~🥂🥂🥂
在具体介绍每种数据增强方法之前,我先来给大家展示一下本次调试使用的图片,如下:

其shape为(426,640,3),为COCO验证集的第一张图片。
transforms.HalfBody
HalfBody——一半的身体,大家可以猜猜这个数据增强手段干了什么?好叭,不卖关子了,一句话解释它干了什么,就是以一定的概率让人体关键点保留上半部分或者下半部分。你或许会疑惑为什么要把完整的人切分成上半部分和下半部分,这是为了模拟关键点检测中的部分遮挡情况。在实际场景中,人物可能被其他对象或者场景的遮挡,这样的情况会使得关键点检测更加具有挑战性。而我们使用HalfBody数据增强,只使用部分身体进行训练,可以实现类似遮挡的效果。这可以帮助模型学习如何处理部分遮挡的情况,提高模型在真实场景中的鲁棒性。
知道了HalfBody的原理,下面就来看看这个HalfBody类是如何实现的:
首先来看看__init__方法:
这个初始化方法主要定义了一个概率p,upper_body_ids和lower_body_ids。upper_body_ids和lower_body_ids是指人的身体的上部和下部的索引,0,1,2,3,4,5,6,7,8,9,10为上,其它为下:

为了让大家直观的感受,作图如下:
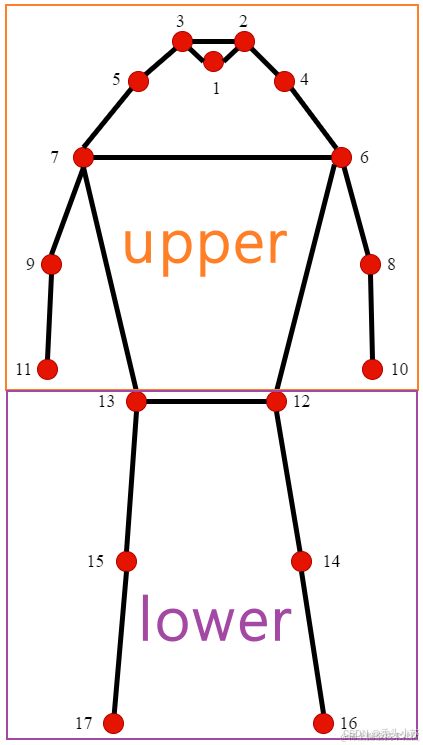
注意:上图索引是从1开始的,代码索引是从0开始的
接着来看__call__方法:
对上述代码做相关解释,首先以一定概率p(0.3)对图像进行HalfBody操作,若满足条件,获取关键点坐标和可见性,如下:


接着按照上半身和下半身对17个关键点进行分类,结果如下:【注意:这里只有15个关键点,因为vis表格有两个0值,表示有两个点没有标注,被if v > 0.5过滤掉了】

上半身一个9个关键点,下半身一共6个关键点,这就是根据upper_body_ids和lower_body_ids来划分的。【注:大家这里要是不理解一定要自己调试看看】
然后会以0.5的概率选择上半身的关键点或者下半身的关键点。如果发现选择的一半身体的关键点个数小于等于2个,则不做任何处理,返回原有的image和target。若关键点个数大于2,则执行以下代码:
我先来介绍一下这段代码主要干了什么,其实就是找到新的目标(上半身或下半身)的bbox,我画图为大家解释一下:
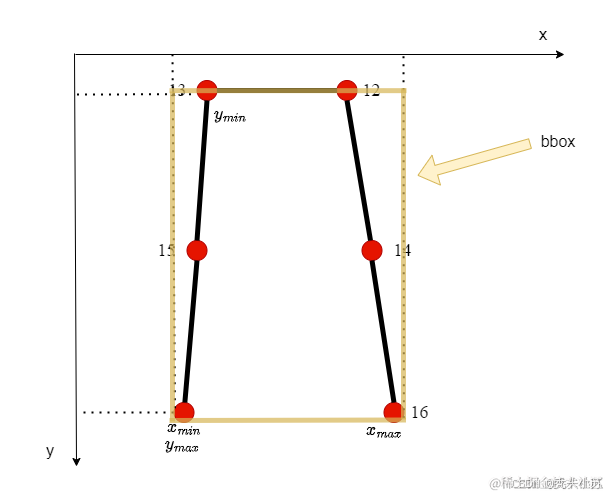
这里我们其实是可以得到一个bbox了,但是其太靠近物体边缘了,放大1.5倍,代码如下:
同样画个图帮大家理解,如下:
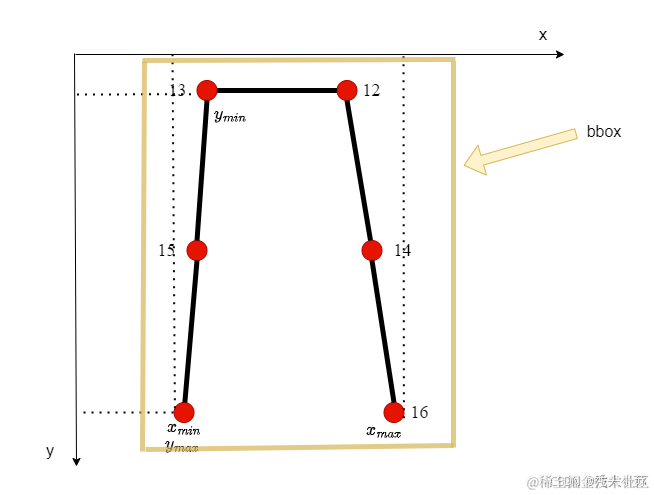
transforms.AffineTransform
AffineTransform——仿射变化,这个是干什么的,我来帮大家解释一下这个仿射变换干了什么,其实就是需要原始图像和目标图像中三个对应点**(代码中使用的是图像中心点,上边界中心点和右边界中心点)**,然后通过这三个点将原始图像变换倒目标图像。
enmmm,大家是不是没怎么明白,别急,我会带大家看看代码,并可视化输出结果,这样大家就能直观的感受到仿射变换到底做了什么了。
首先第一步会调整上一步骤得到的bbox的长宽比,使其符合h:w=256:192,这个是我们输入图片的尺寸,具体代码如下:
我们可以看看调整bbox后的图像,如下:

你可能看不出bbox的长宽比,但其就是256:192,其高度h为71.507,宽度w为53.630,精度上有点差别,不相信的大家自己去调试试试喔~~~🍡🍡🍡
接着我们就寻找原图像(bbox)和目标图像的三个点:
然后对bbox进行缩放和旋转,先是缩放,
我们来看看缩放后的bbox: 【注意这里我调试时的scale取0.7115,所以bbox变小了】

然后是旋转:【注意这里我调试时的angle取-25,所以bbox逆时针旋转了25°】
我们再来看看旋转后的结果:

最后就是仿射变换了:
同样的我们来看看最后的resize_img长什么样,如下:【resize_img的大小是256*192喔】

到这里我们对图像的操作就完成了,不要忘记我们还要对标签进行同样的操作喔,关键点检测的标签就是一个个点嘛,如下:
最后再来用一个图来总结一下仿射变换都做了什么,如下:

transforms.RandomHorizontalFlip
RandomHorizontalFlip——水平翻转。我想对这个数据增强手段大家都比较熟悉,就是将图片左右进行翻转,其最后实现的效果如下图所示:

和仿射变换一样,要实现水平翻转,我们不仅需要对图片进行水平翻转操作,同样需要对标签进行同步操作,我们分别来看看如何对图片和标签进行水平翻转操作的叭。
- 图片
对图片进行水平翻转的操作很简单啦,只需要一行代码就可以了喔,如下:
- 标签
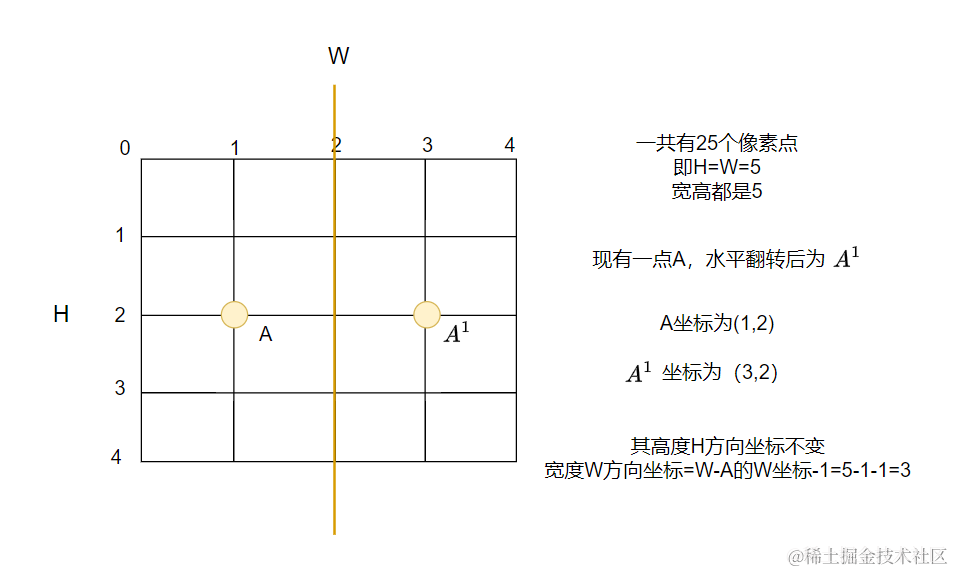
对标签进行翻转是这步的难点,我当时阅读这部分的代码时弄了很长时间才明白,其实要画一个图大家就能很容易的理解。我们先来看代码叭:【注:我没有复制所有代码过来了,挑了关键的代码】
这句代码什么意思呢?其实就是将关键点水平翻转了一下,作图帮大家理解:
大家会不会认为这样就结束了呢,其实很没有,我们来看看代码中还做了什么,如下:
这步交换了人体关键点中堆成的关键点,为什么要这么做,我当时就是这里疑惑了好久好久,我来画个图帮大家理解一下:

这样你可能还看不出端倪,我在画出水平翻转后的图像,如下:

你会发现如果单纯的将两个点对应过来,左右关系会对调,因此需要把标签进行左右互换。【大家这里如果觉得不好理解的话,可以自己动动手,画画图,相信你会有所收获】
transforms.KeypointToHeatMap
KeypointToHeatMap——将关键点映射为热力图。我们在理论部分说到,HRNet是基于热力图实现关键点检测,不清楚的可以去原理详解篇寻找寻找答案。那么其是怎么将关键点映射成热力图的呢,我们一起来看看代码是怎么实现的叭。
首先,先来看看其__init__函数:
这段主要定义了存储热力图的宽度和高度、高斯标准差和关键点权重等信息,然后生成了一个大小为13*13的高斯核kernel(中间的值大,往四周扩散值越来越小),如下图所示:

接着我们来看__call__函数:
我给大家解释一下可能难理解的地方:
这句是将关键点的坐标映射到热力图上,因为最终的热力图相较于原图像下采样了4倍,所以要除以4,这里加上0.5是起到一个四舍五入的作用,因为后面要将坐标转为int格式。
这两句是找到某个关键点对应热力图的左上角(ul)和右下角(br)的坐标,kernel_radius是高斯核的半径,如下图所示,hw坐标系表示热力图坐标,中间的⚪表示关键点在热力图上的坐标,坐标为(x,y):
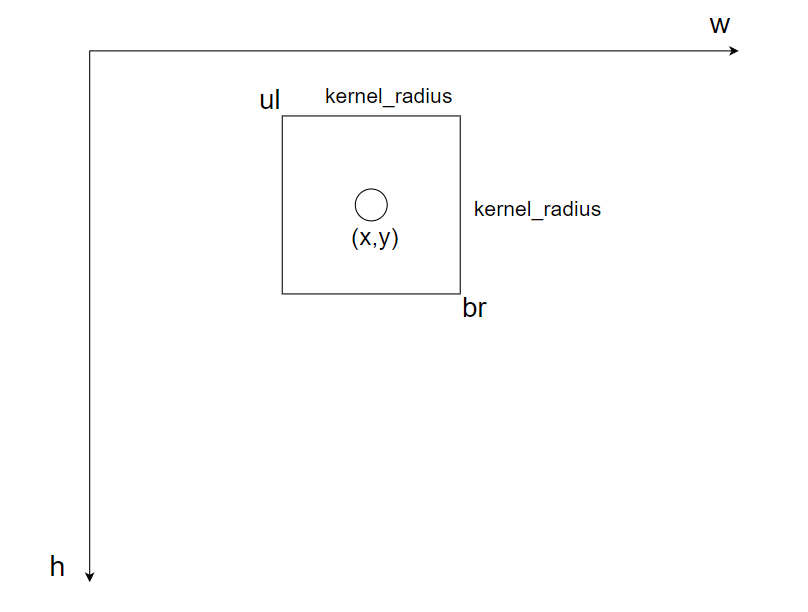
这句是看看以xy为中心kernel_radius为半径的辐射范围内(就是上图中的正方形区域内)与heatmap(就是上图的hw坐标系,当然其h=64,w=48,并不是无线延长的坐标系)有没有交集,若无交集,则将kps_weights[kp_id]置为0。
这几句分别计算高斯核有效区域和heatmap中的有效区域,为下一步将将高斯核有效区域复制到heatmap对应区域做准备:
这几句到底实现了什么呢,其实就是把高斯核kernel复制到热力图中,至于复制到什么位置,复制多少,就看g_x、g_x、img_x和img_y了。我调试帮助大家理解一下,比如现在g_x=(0,12)、g_y=(0,12)、img_x=(25,37)和img_y=(12,24)。
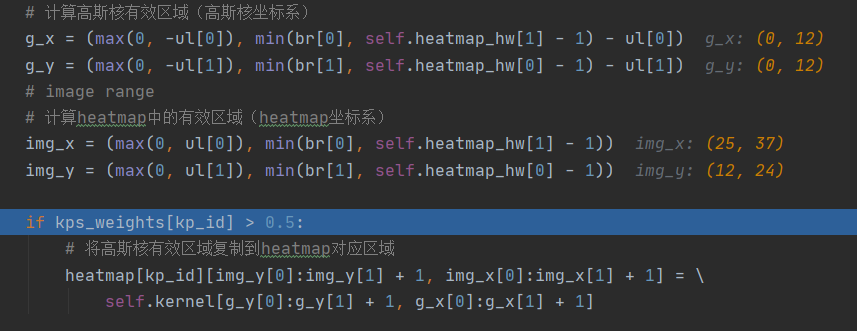
g_x[0]:g_x[1]+1=0:12+1、g_y[0]:g_y[1]+1=0:12+1表示复制kernel的x方向(0,12+1)范围内的值和y方向(0,12+1)范围内,你看kernel的shape你会发现,其大小为13*13,那么这个(0,12+1)就是复制整个kernel数组**(这里刚好是整个数组,你调试的话会有不同的结果)**:

那么把这个数组复制到哪里呢,其实就是热力图的对应区域,这是就用到了img_x=(25,37)和img_y=(12,24),将其复制到热力图w方向(25,37+1)和h方向(12,24+1)的位置,如下图所示:

这里展示一下图片和产生热力图的结果,如下图所示:【注:由于不是同一次调试的结果,所以这里的图像和之前的有所差异】

最后我还想说一个小点,就是kps_weights这个值,表示的是关键点的权重,如果没有指定这个参数,那么其就默认是关键点的可见性,如果指定了这个参数,其会让原来的可见性乘这个指定的参数,在HRNet中,这个kps_weights默认如下:

小结
HRNet中的在线数据增强方式到这里就为大家介绍完啦,我觉得这部分还是非常重要的,大家可以去认真的学习一下喔,不明白的可以先调试调试,实在搞不懂欢迎评论区和我交流探讨。🥂🥂🥂
网络结构搭建
HRNet的网络结构我在原理详解篇已经为大家介绍过了,也简略的为大家展示了一些代码,但是没用具体介绍网络的详细结构。这里呢,我也不打算介绍了,因为我认为网络搭建部分真的是比较简单的,就像搭积木一样,一层一层的,只要你拿起代码对照着网络结构图调试一遍就会非常清晰了。所以这里大家一定要动起小手来喔!!!🌼🌼🌼
网络训练和预测
我们一起来看看训练阶段的代码,主要看训练一个epoch的情况就好啦,即train_one_epoch函数,首先有一个热身训练的代码:
关于此部分代码可以从我的这篇博客-->poly学习率策略源码详解中查看详情,对这种学习率调整策略有详细解释,链接如下:
深度学习语义分割篇——DeeplabV3原理详解+源码实战🌱🌱🌱
接着就来说说for循环遍历数据集的过程,使用的for循环如下:
我们可以调试进入log_every函数中,注意到log_every函数中有一个yield obj,yield是python中的关键字,是一个生成器,每次log_every运行到yield obj时都会暂停执行下面的代码,而是将obj返回给调用方,这样做的目的是节省内存。
这么说我觉得大家听的还是云里雾里,我画一个图解释一下代码的运行流程:
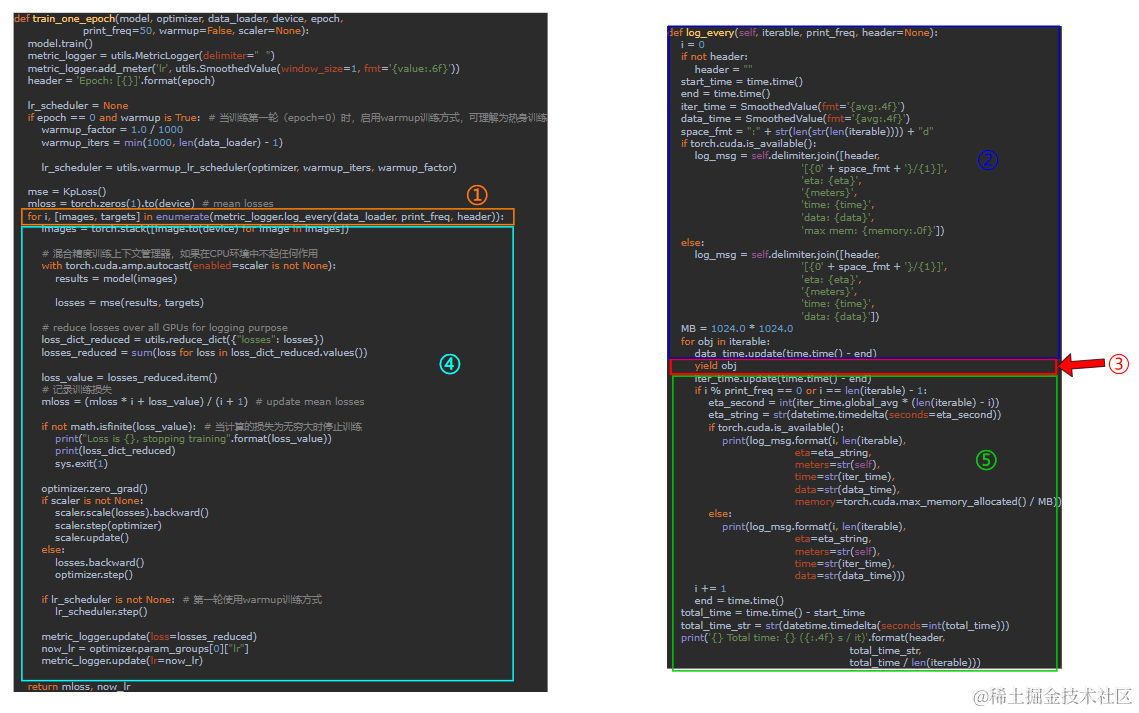
其按顺序依次执行①②③④⑤,在执行完③时,obj会传给①,得到image和target。知道了这一点,那么剩下的内容就比较简单啦,这里就不在过多叙述咯,不清楚的大家一定要调试调试喔。
接下来就是预测过程,我们会通过网络得到输出结果,其尺寸为(1,17,64,48),1表示batch为1,后面我们需要对这个输出做一些后处理操作,使其能够将预测关键点映射到原图上。关于预测过程,我也在HRNet原理详解篇进行了介绍,不清楚的一定要去看看喔🍚🍚🍚
总结
呼呼呼~~~终于写完啦,源码解析篇就到这里结束啦,整个HRNet到这里也结束咯,如果有任何不明白的地方欢迎和我一起探讨,共同进步喔。🥂🥂🥂
参考链接
HRNet网络简介🍁🍁🍁
如若文章对你有所帮助,那就🛴🛴🛴
.gif")















 2792
2792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









