







参考:
Pandas Series入门教程
Pandas 数据结构 - Series
Pandas 数据结构 - Series
理解
这个Series可以简单理解成一列数据,这一列数据是以数组的形式存储的。数组有下标,也就是索引,我们可以指定索引范围,数组中的数据类型也可以指定,还可以给这样一列数据一个名字,就像是列的标题一样。
直观的看,Series长这样:
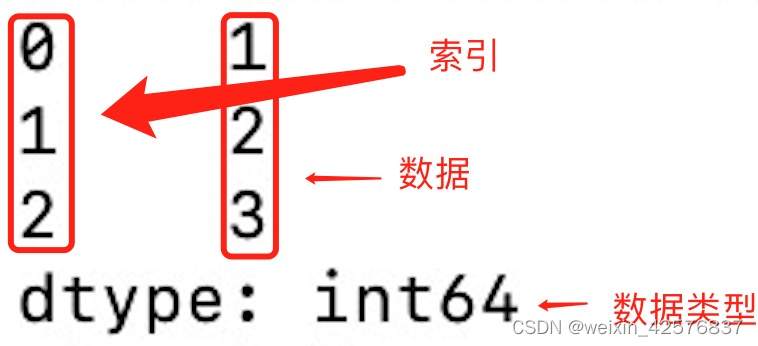
pandas.Series()
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
一个一个来看:
第一个参数data
首先想要创建一个Series对象,需要使用pandas.Series()这个函数。
首先需要导入pandas库。
import pandas as pd
现在既然想要创建一个Series对象,那这个Series对象(就想象成一列数据),那么这个列里面的数据是什么,这个数据就是由data参数来指定的。
它可以是python基本类型中的list,dict,也可以是numpy中的ndarray类型。
举例:
import pandas as pd
import numpy as np
#创建一个python列表
a1 = [1,3,5,7,9]
#创建一个numpy中的ndarray类型数组,步长为2
a2 = np.arange(2,11,step=2)
#看一下a1和a2的类型
print(type(a1))
print(type(a2))

#创建一个Series
s1 = pd.Series(data=a1)
s2 = pd.Series(data=a2)
#看一下这个Series
print(s1)

print(s2)

第二个参数index
前面已经说了,这个Series可以看成一列数据,数据是用数组来存储的,数组中就有index,所以这个参数就是来指定我们自己的index。默认情况下,index从0开始,比如上面两个s1与s2就是从0开始的索引:

假设现在有三个学生:[‘张三’,‘李四’,‘王五’],用这个列表创建一个Series:
stus=['张三','李四','王五']
s = pd.Series(stus)
s

由于每一个学生都有学号,我们不想使用0,1,2,作为索引,想使用学号作为索引。
#创建一个索引,长度需要跟数据的长度一致
index = ['001','002','003']
#使用这个索引
s.index = index
s

也可以直接使用索引取出数据

dtype,name,copy参数
- dtype:指的就是series中数据的类型,Series 的数据类型一般是 NumPy 数据类型。
- name:感觉好像没啥用
- copy:表示对 data 进行拷贝,默认为 False。还没明白
stus=['张三','李四','王五']
#创建一个索引,
index = ['001','002','003']
s = pd.Series(stus,index=index,name='students',copy=True)
s

使用字典创建Series对象
除了可以使用列表或者ndarray类型来创建Series之外,还可以使用字典来创建。
#创建一个字典
d = {
'a':0,
'b':1,
'c':2
}
s = pd.Series(data=d)
s
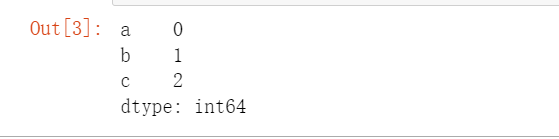
字典的key作为了Series的索引。
Series 的常用属性和方法。
| 名称 | 属性 |
|---|---|
| axes | 以列表的形式返回所有行索引标签。 |
| dtype | 返回对象的数据类型。 |
| empty | 返回一个空的 Series 对象。 |
| ndim | 返回输入数据的维数。 |
| size | 返回输入数据的元素数量。 |
| values | 以 ndarray 的形式返回 Series 对象。 |
| index | 返回一个RangeIndex对象,用来描述索引的取值范围。 |
用一个例子来展示这些方法属性:
#np.random.randn(5)生成5个服从标准正态分布的数据
s = pd.Series(np.random.randn(5))
s

axes

s.axes:可以看出返回的是Series的索引范围,这里给出的信息表示:这个索引是从0开始的,到5停止,步长为1,的列表
那么如果把索引改一下,改成字符类型,返回的结果是:
#np.random.randn(5)生成5个服从标准正态分布的数据
s = pd.Series(np.random.randn(5),index=['1','2','3','4','5'])
s


还是可以直接返回出索引的范围
dtype

没感觉啥用
empty

Series为空:返回True:
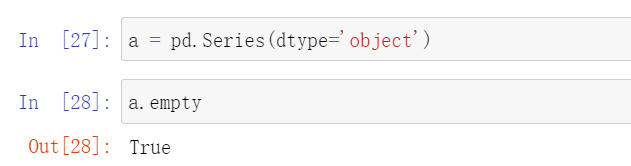
否则返回False
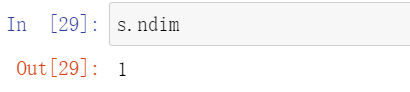
ndim
查看序列的维数。根据定义,Series 是一维数据结构,因此它始终返回 1
size
返回 Series 对象的大小(长度)。也就是Series中有几个数据

values
以数组(ndarray)的形式返回 Series 对象中的数据。
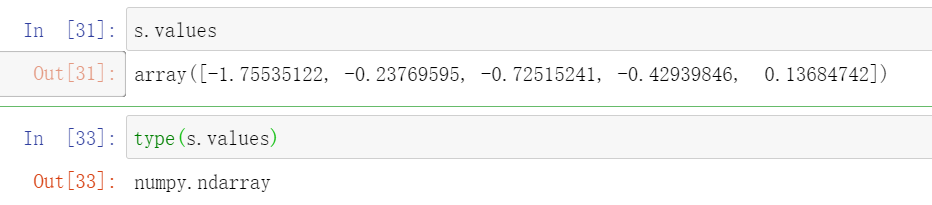
这个应该是用的比较多的一个属性。
index
该属性用来查看 Series 中索引的取值范围。
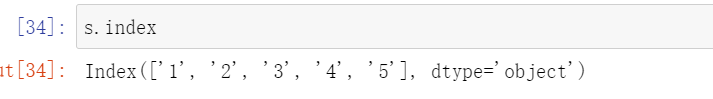
和上面的axes好像没啥区别。
Series常用方法
1) head()&tail()查看数据
如果想要查看 Series 的某一部分数据,可以使用 head() 或者 tail() 方法。
head:头,默认返回前5行数据
tail:尾,默认返回后5行数据
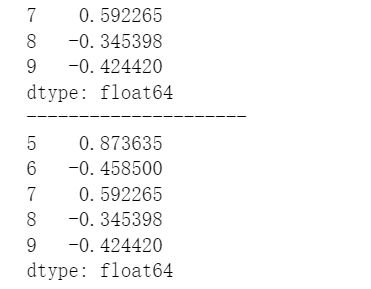
s = pd.Series(np.random.randn(10))
s
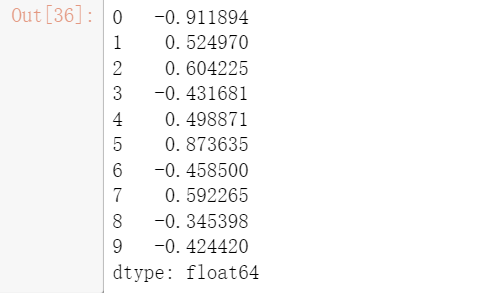
#指定返回前3行
print(s.head(3))
print('---------------------')
#默认返回前5行
print(s.head())
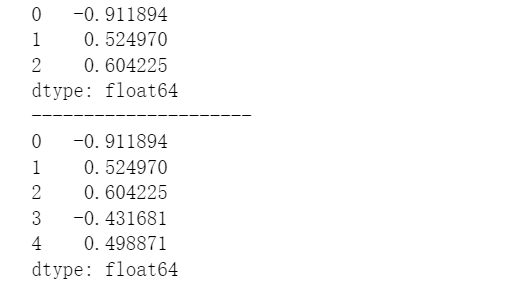
#指定返回后3行
print(s.tail(3))
print('---------------------')
#默认返回后5行
print(s.tail())
2) isnull()&nonull()检测缺失值
isnull() 和 nonull() 用于检测 Series 中的缺失值。所谓缺失值,顾名思义就是值不存在、丢失、缺少。
- isnull():如果为值不存在或者缺失,则返回 True。
- notnull():如果值不存在或者缺失,则返回 False,值存在就返回True
s=pd.Series([1,3,5,None])
s

print(pd.isnull(s)) #是空值返回True
print('-------------------')
print(pd.notnull(s)) #空值返回False

可以看到它是对Series中的每一个数据都做了一个检查。














 2076
2076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









