







python 实时抓取网页数据并进行 筛查
爬取数据的两种方法 :
方法 1 : 使用 requests.get() 方法,然后再解码,接着 调用 BeautifulSoup API
首先看 headers 获取方法 :
点击进入任意一个网页页面,按F12进入开发者模式,点击Network再刷新网页。在Network下的Name中任意点击一个资源,在右侧的Headers版块中下拉到最后,可以看见Request Headers参数列表最后有一个user-agent,其内容就是我们要找的浏览器headers参数值。

然后通过查找 html 源码来 find 指定内容 。利用 find_all() 方法 和 tag.find() 方法

方法2 : 调用 Request() 方法,并进行 urlopen() , decode 操作,最后用 BeautifulSoup() 方法,这样对 html 解析完毕, 接着用 .select() 方法查找 html 代码中的指定内容 。

其实两种方法对于 html 的解析都是固定操作,关键在于 查找 html 的指定内容该如何查找。
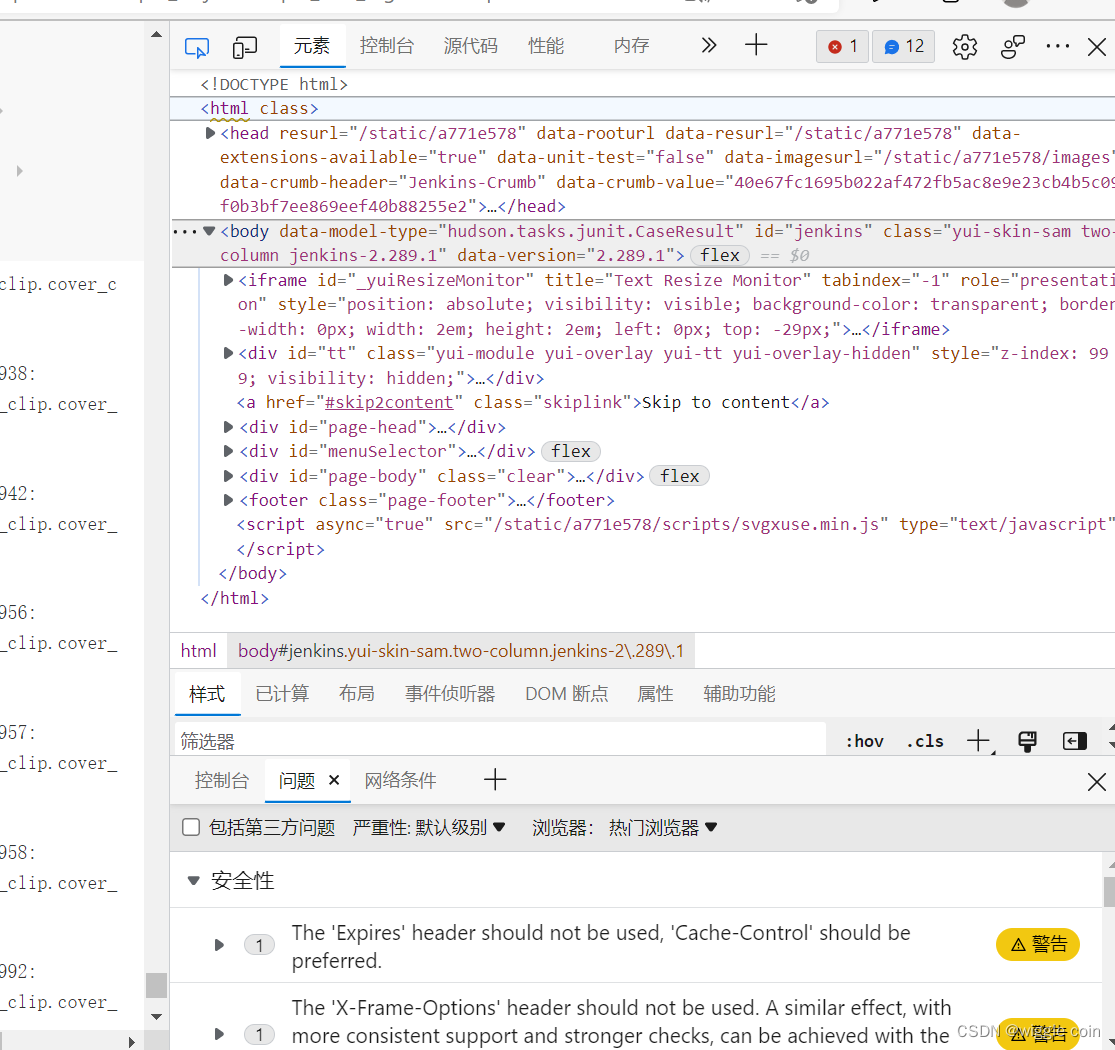
首先使用F12对当前页面进行解析,如图所示 :
接着点击左上角的元素检查按钮,即 :
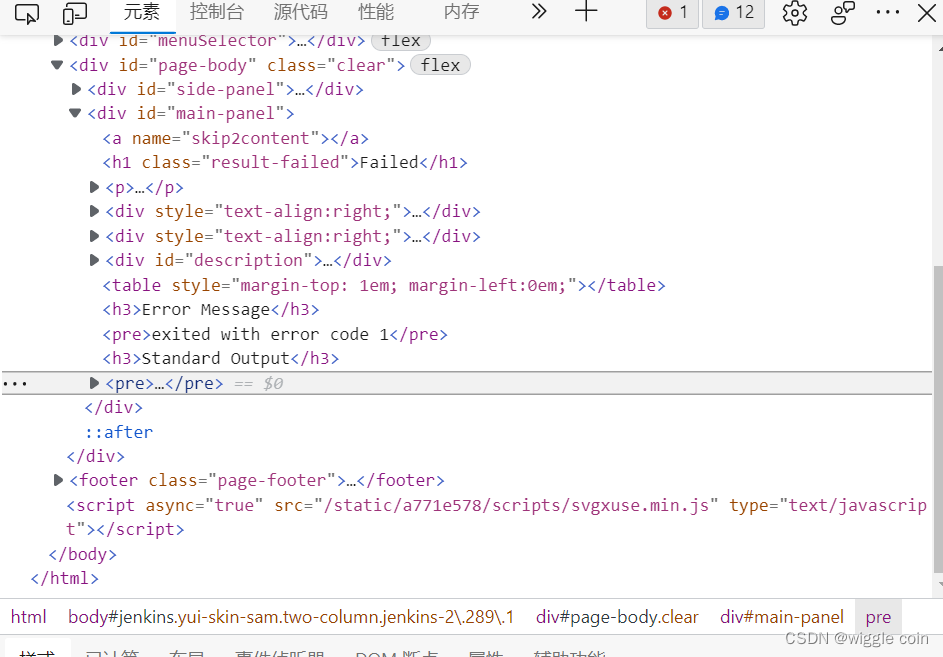
然后再点击想要 爬取的网页内容, 就可以找到 其所在 html 源码中的位置 :
比如我这里的位置是在 pre 里面
紧接着右击 pre 栏,选择复制 selector , 就可以看见所找内容对应的 html 地址 : 我这里的为
#main-panel > pre:nth-child(11)
这里的关键信息就是 > 之后的内容 和 : 之前的内容 。如果有 多个 > 的话,就把多个 > 的信息列出来即可,比如 :
#group-topics > div:nth-child(2) > table > tbody > tr:nth-child(5) > td.title > a
那么就需要提取
tr td.title a
作为关键信息即可。
找出关键信息后,在方法 2 中的 .select() 中填入关键信息即可,注意关键信息用 ’ ’ 包起来 。
下面请看源码 :
from bs4 import BeautifulSoup
import requests
from datetime import datetime
import time
##import schedule
## 获取 headers
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'}
## 方法 1 爬取 html 网页内容
ip0_url = "http://xxxxxxxxx.cn"
ip1_url = "http://xxxxxxxxx.cn"
ip2_url = "http://xxxxxxxxx.cn"
r_ip0 = requests.get(ip0_url,headers = headers)
r_ip1 = requests.get(ip1_url,headers = headers)
r_ip2 = requests.get(ip2_url,headers = headers)
html_ip0 = r_ip0.content.decode('utf-8','ignore')
html_ip1 = r_ip1.content.decode('utf-8','ignore')
html_ip2 = r_ip2.content.decode('utf-8','ignore')
ip0_page = BeautifulSoup(html_ip0,'lxml')
ip1_page = BeautifulSoup(html_ip1,'lxml')
ip2_page = BeautifulSoup(html_ip2,'lxml')
def job_1(sa_page,time_now):
now_file = "./err_log/pre.txt"
file2 = open(now_file,'w').close()
for tag in sa_page.find_all('html'):
sub_tag = tag.find('body')
with open(now_file,'a') as ff:
ff.write(sub_tag.text)
ff.close()
def job_2(ip_name,log_file):
ip = ip_name.split("_lo")[0]
line_list = []
sa_pre_path = "./err_log/pre.txt"
sa_path = "./err_log/{}.txt".format(log_file)
file1 = open(sa_pre_path,'rb')
for line in file1.readlines():
data = line.decode()
strlist = data.split("/\n")[0]
if "STATUS" in strlist:
status = strlist.split("STATUS:")[1].split(" ")[0]
if(status == "FAIL"):
line_list.append(strlist)
# 对 ip0 进行一些特殊处理
if (ip_name == "ip0_log"):
with open(sa_path,'w') as fw:
fw.write("\n====================={}====================\n\n".format(ip_name))
for ll in line_list:
fw.write(ll)
# 从另外一个 html 网址获取内容
ll_0 = ll.split("STATUS")[0]
ll_1 = re.sub(r" ","",ll_0)
ll_r = re.sub(r'/','_',ll_1) ## re.sub() replace function
# 获取到指定 url
log_url = "http://xxxx.cn/xxx/XXXXXX_IP/view/03/view/xxx/xxx/xxx_{0}_regre/lastCompletedBuild/testReport/(root)/{1}/{2}/".format(ip,ll_r,ll_r)
### 方法 2 ,使用 Request API 来爬取页面 (个人感觉比 方法 1 好用)
r_log = Request(log_url,headers = headers)
res = urlopen(r_log)
aa = res.read().decode('utf-8')
log_page = BeautifulSoup(aa,'html.parser')
## 搜索 关键路径
comment = log_page.select('pre')
###### 如果 搜索的 html 网站 没有结果,则 跳过
if(len(comment) < 2):
continue
else:
cc = str(comment[1])
key_value = cc.split('Waive List:')[1].split('Error Pattern found')[0]
if (len(key_value) < 100):
fw.write("{}\n\n".format(key_value))
else:
fw.write("ERR MSG : \n")
if ("Offending" in key_value):
fw.write("Offending {}\n".format(key_value.split("Offending")[1].split("Offending")[0])) # line 1
elif ("UVM" in key_value):
fw.write("UVM{}\n\n".format(key_value.split("UVM")[1].split("UVM")[0])) # line 1
### 在文件中追加写入其他 ip 的内容
else:
with open(sa_path,'a') as fw:
fw.write("\n====================={}====================\n\n".format(ip_name))
for ll in line_list:
fw.write(ll)
ll_0 = ll.split("STATUS")[0]
ll_1 = re.sub(r" ","",ll_0)
ll_r = re.sub(r'/','_',ll_1) ## re.sub() replace function
log_url = "http://xxxx.cn/xxx/XXXXXX_IP/view/03/view/xxx/xxx/xxx_{0}_regre/lastCompletedBuild/testReport/(root)/{1}/{2}/".format(ip,ll_r,ll_r)
r_log = Request(log_url,headers = headers)
res = urlopen(r_log)
aa = res.read().decode('utf-8')
log_page = BeautifulSoup(aa,'html.parser')
comment = log_page.select('pre')
###### pass search html data == 0 case :
if(len(comment) < 2):
continue
else:
cc = str(comment[1])
key_value = cc.split('Waive List:')[1].split('Error Pattern found')[0]
if (len(key_value) < 100):
fw.write("{}\n\n".format(key_value))
else:
fw.write("ERR MSG : \n")
if ("Offending" in key_value):
fw.write("Offending {}\n".format(key_value.split("Offending")[1].split("Offending")[0])) # line 1
elif ("UVM" in key_value):
fw.write("UVM{}\n\n".format(key_value.split("UVM")[1].split("UVM")[0])) # line 1
###### 定时的提取 html 网页中的内容 并写入 txt 中去
while True:
time_hm = time.strftime("%H:%M", time.localtime()) # 刷新
time_now = datetime.now().strftime("%Y-%m-%d.%H:%M:%S.%f")
if time_hm == "05:01": # 设置要执行的时间
job_1(ip0_page,"ip0_log",time_now)
job_2("ip0_log",time_now)
job_1(ip1_page,"ip1_log",time_now)
job_2("ip1_log",time_now)
job_1(ip2_page,"ip2_log",time_now)
job_2("ip2_log",time_now)
time.sleep(120) # 停止执行120秒,防止反复运行程序。
elif time_hm == "09:01":
job_1(ip0_page,"ip0_log",time_now)
job_2("ip0_log",time_now)
job_1(ip1_page,"ip1_log",time_now)
job_2("ip1_log",time_now)
job_1(ip2_page,"ip2_log",time_now)
job_2("ip2_log",time_now)
time.sleep(120)
elif time_hm == "13:01":
job_1(ip0_page,"ip0_log",time_now)
job_2("ip0_log",time_now)
job_1(ip1_page,"ip1_log",time_now)
job_2("ip1_log",time_now)
job_1(ip2_page,"ip2_log",time_now)
job_2("ip2_log",time_now)
time.sleep(120)
elif time_hm == "17:04":
job_1(ip0_page,"ip0_log",time_now)
job_2("ip0_log",time_now)
job_1(ip1_page,"ip1_log",time_now)
job_2("ip1_log",time_now)
job_1(ip2_page,"ip2_log",time_now)
job_2("ip2_log",time_now)
time.sleep(120)
elif time_hm == "21:01":
job_1(ip0_page,"ip0_log",time_now)
job_2("ip0_log",time_now)
job_1(ip1_page,"ip1_log",time_now)
job_2("ip1_log",time_now)
job_1(ip2_page,"ip2_log",time_now)
job_2("ip2_log",time_now)
time.sleep(120)
elif time_hm == "01:01":
job_1(ip0_page,"ip0_log",time_now)
job_2("ip0_log",time_now)
job_1(ip1_page,"ip1_log",time_now)
job_2("ip1_log",time_now)
job_1(ip2_page,"ip2_log",time_now)
job_2("ip2_log",time_now)
time.sleep(120)
elif time_hm == "11:38":
job_1(ip0_page,"ip0_log",time_now)
job_2("ip0_log",time_now)
job_1(ip1_page,"ip1_log",time_now)
job_2("ip1_log",time_now)
job_1(ip2_page,"ip2_log",time_now)
job_2("ip2_log",time_now)
time.sleep(120)

















 8032
8032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











