






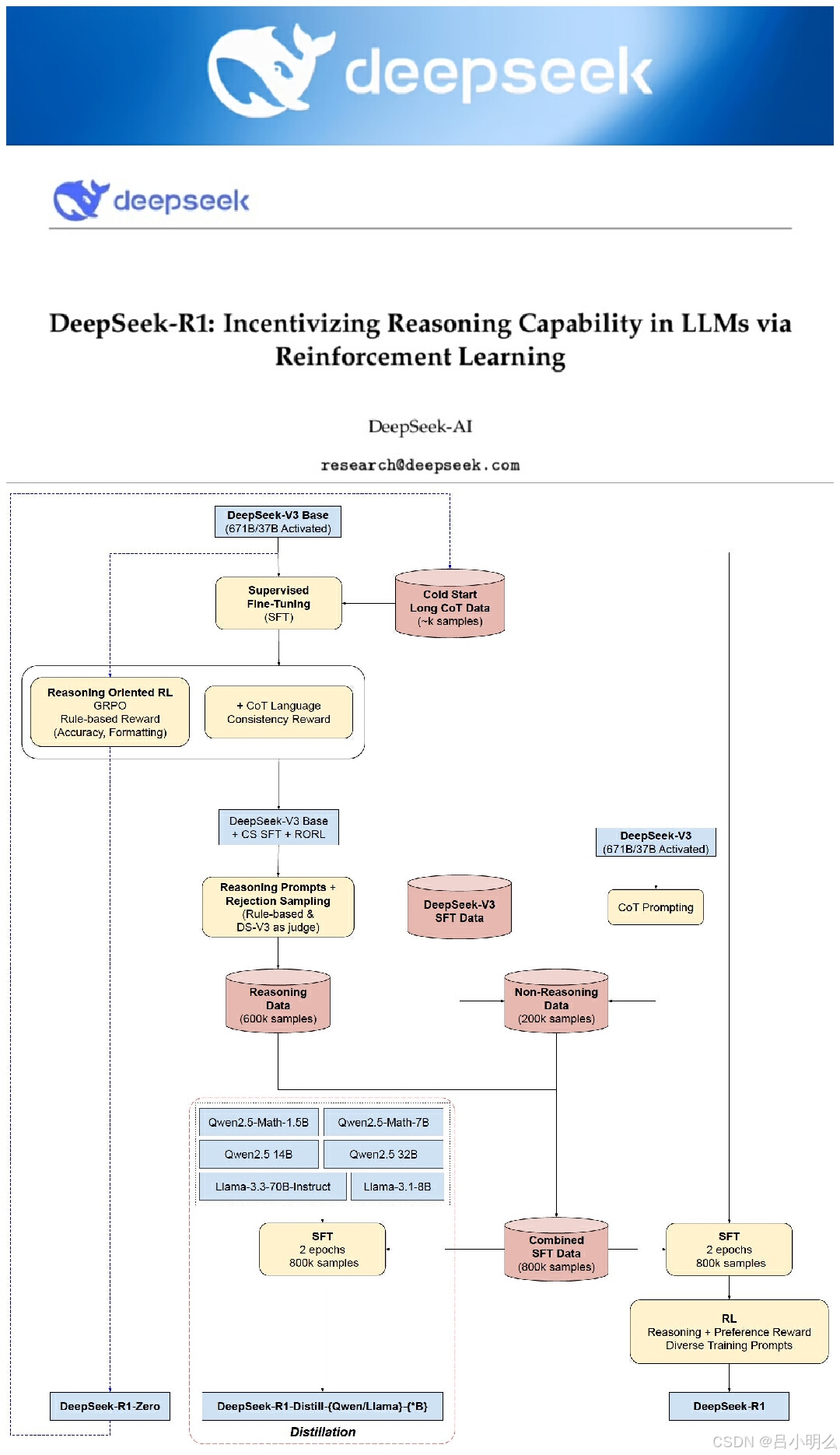
自上一篇读完论文胡思乱想有感而发后,看到国内外各种群、社区以及这里留言大家讨论有关DeepSeek-R1-zero(R1是前后带了小sft的)这种纯RL而没有采用任何sft,prm,mcts就实现类o1 scaling law下的不管是效果还是其中技术路线的诸多困惑、惊讶、质疑甚至是争论,我想再补充跟大家分享一下我的观点和看法:
首先zero是没有sft并从“0”开始rl的,按照paper中的说法实现了所谓的“自进化”,但大家要知道其中的rl过程中是进行了CoT template奖励遵循的,是的,是reward而不是sft(且是orm而不是prm),但本质上两者间是否有着某种数学等价的联系呢?这块要留给后续的理论证明了,不过我个人直觉上判断大概率是等价的,因为reward也是另一种形式的监督嘛,但等价并不等于等效,这点尤为重要,因为这也意味着后续在整个语言符号体系中rl过程所展现出来的那令人惊艳的潜力!即→“自强化”换“强监督”,不过这确实打破了传统sft的监督形式,为我们开辟出了test-time scaling law下的另一条更清爽的蹊径。
而接下来我想又会引发另一个问题或思考:“这种CoT template”是否是得当的呢?它会不会使得模型在rl过程中陷入局部最优呢?或者说在更大数据分布尺度下是否也会造成论文中关于rpm所提及到“Reward Hacking”呢?
我想是否会造成Reward Hacking也许要从模型所遵循的某种语义熵着手去尝试论证,而局部最优我想是大概率的,不过也许需要跳出当下这种慢思考·长链推理模式下的test-time scaling law来看待这一情况并尝试做出更广阔的探索。
想到这里,也突然有一个灵感,最开始想到R1-zero如果没有CoT template去reward,而只有orm呢?那肯定不行,那如果只进行部分CoT template reward,后面的阶段撤掉由着rl自由发挥,即在模型隐参数空间形成了一定的CoT模式,在接下来的训练阶段尝试让模型部分遵从CoT并且做一些更长链的扩展或探索机制(如kimi k1.5的Partial Rollouts),如果可以不花费太多资源的情况下explore命中了orm呢?当然前提这种CoT下的慢思考是一个足够完备、通用、值得遵循的思考模式。
另外,好友也对r1这种orm咩有解决“过度思考”提出一些质疑,我想这也是我们未来对训练过程以及数据采样分布上值得深挖的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









