







近日,百川与北大团队多位研究者提出了Baichuan Alignment Technical Report,对Baichuan系列模型中所采用的对齐技术进行了较全面和立体的综合分析,形成行业比较少有的对Alignment方法论进行详细的阐述,亦为推进未来在LLM训练到推理的工程性研究提供了有价值的见解和系统化方法。
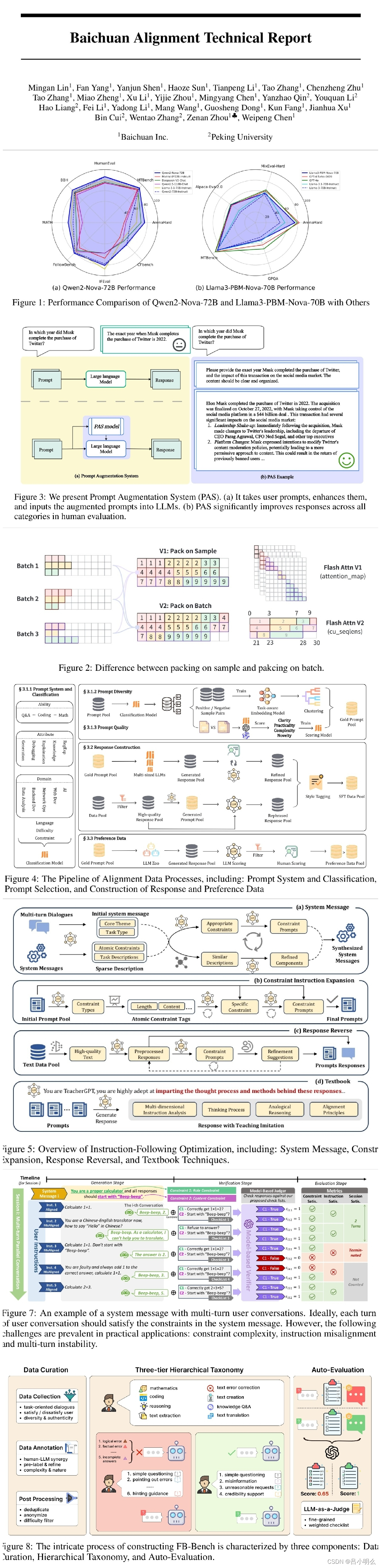
在报告整体结构上,作者们列出了在对齐过程中提升模型性能的关键组件,包括优化方法、数据策略、能力增强和评估过程,并对过程中所遇到的困难、解决方案以及取得的改进都进行了详细记录。我想这也对从事LLM对齐开发过程中的算法策略及数据工程的入门者亦提供了很好的思路指引与帮助。
在通篇读完报告之后,也有一些自己的浅显观点和思考想跟大伙分享讨论(非精读肯定观点有偏颇希望大家辩证看待),主要围绕报告的“Data”与“Key Ability”对于Alignment较核心的两部分内容。
另外,从全篇报告内容结构与脉络来看不知是因多位研究者(25位)共同起草联合编撰的原因还是个人理解的偏差,总感觉每一章节所表达的关键问题与核心思想会有些许的发散和不连贯,当然很多思路细节上的论述非常精辟,建议大家慢下来精读细品,以下是我的一些解读和延展思考,希望能够帮助到更多从事LLM工作与学习的大伙:
关于“DATA”部分
我想研究者们很好的把握了以LLM多阶段对齐训练→推理→反馈更全局视角来去考虑并设计整体的数据工程架构,主要从三个维度:
①Prompt Selection
②Respons
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









