






转自公众号:计算机视觉之路头条 | 自动驾驶还是要看Waymo----CVPR2020mp.weixin.qq.com
原文链接:

Waymo在CVPR2020做了一个题目为:Machine Learning for Autonomous Driving at Scale的报告,翻译过来就是大数据在自动驾驶中的应用。
其中大数据体现在: 超过2000万英里的真实驾驶的数据,150亿英里的模拟驾驶数据。
在自动驾驶方向的应用,waymo主要提了4个大方向: end-to-end predict,ViDAR: deep structure from motion,传感器合成:SurfelGAN,多任务学习。
一、end-to-end predict
在之前的文章,博主也介绍过两篇end-to-end predict的文章,来自Uber ATG,大家可以参考历史文章:faf(fast and furious),intentNet。waymo介绍了自产的4篇文章:
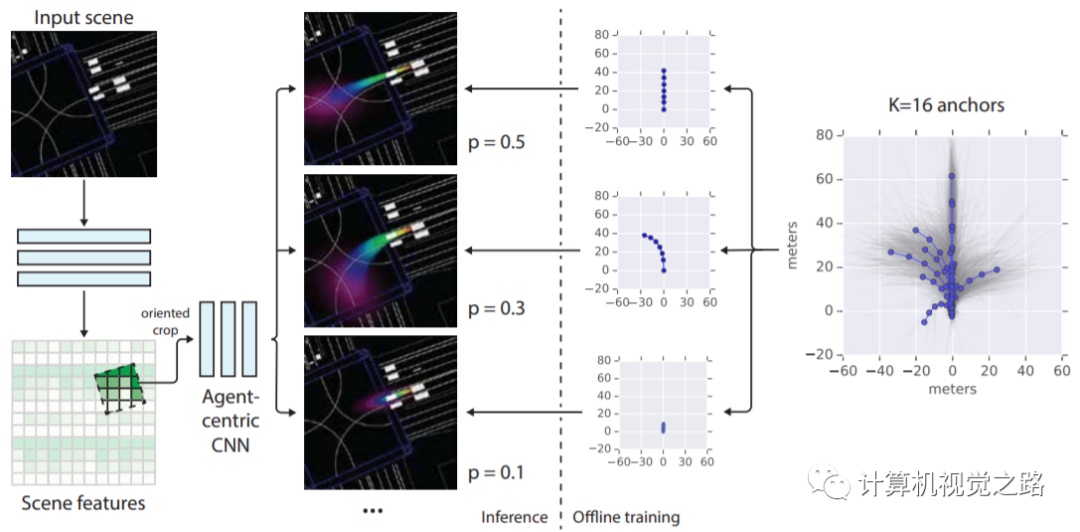
1,MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction整个方法是在BEV视角下对不同的目标做特征提取以及状态分析,对场景中的每一个目标,crop一个以该目标为中心的特定区域,然后在k个预定义的anchor上预测该目标轨迹,并给出轨迹的不确定性。具体流程如下图所示。
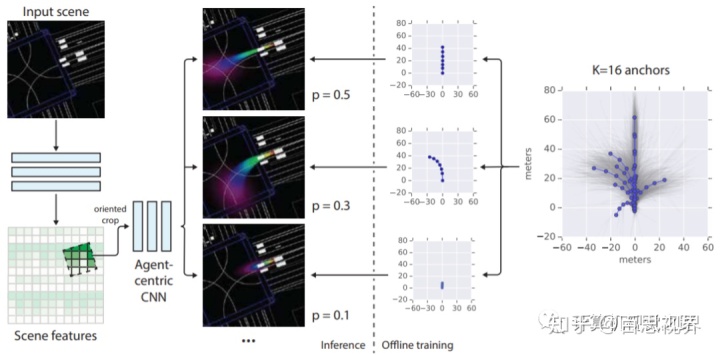
2,STINet: Spatio-Temporal-Interactive Network for Pedestrian Detection and Trajectory Prediction这篇文章专门用来做行人的end-to-end的预测,作者提出了一个两阶段的网络,第一阶段实现时序上的目标检测,即:获得历史目标检测框和当前帧检测框,第二阶段通过行人间的相互关系建立graph,进一步提高预测的准确度。具体方法流程如下图所示。
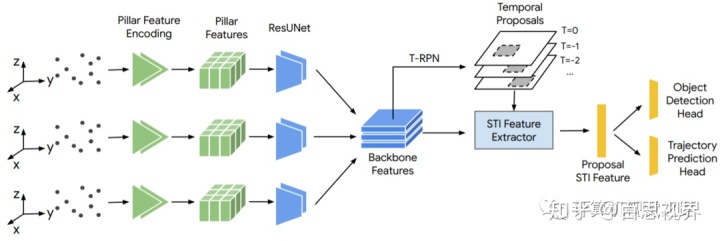
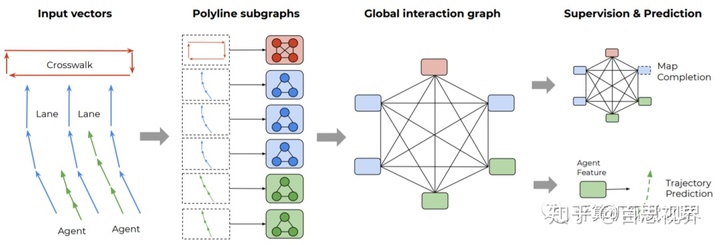
3,VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized RepresentationVectorNet是一个分层的图神经网络用矢量表示各个道路组件的空间局部性,然后对所有组件之间的高级交互进行建模。通过对矢量化的高清(HD)地图和目标轨迹进行操作,避免了有损渲染和计算密集型ConvNet编码的步骤。为进一步增强VectorNet在学习上下文特征方面的能力,提出了一种新的辅助任务来恢复基于上下文的随机屏蔽映射实体和目标轨迹。具体方法流程如下图所示。
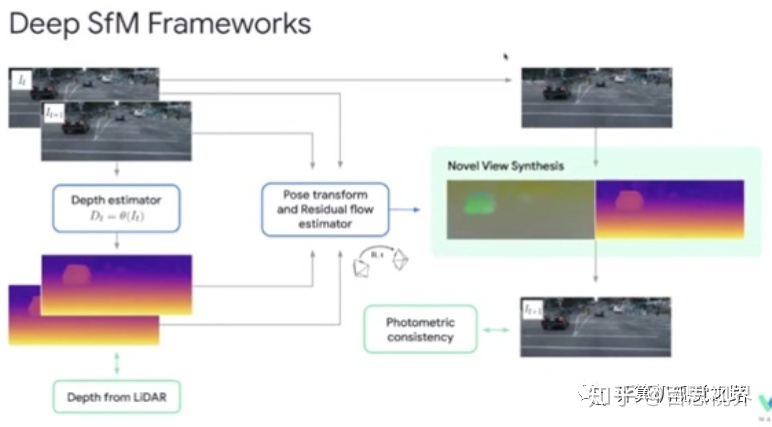
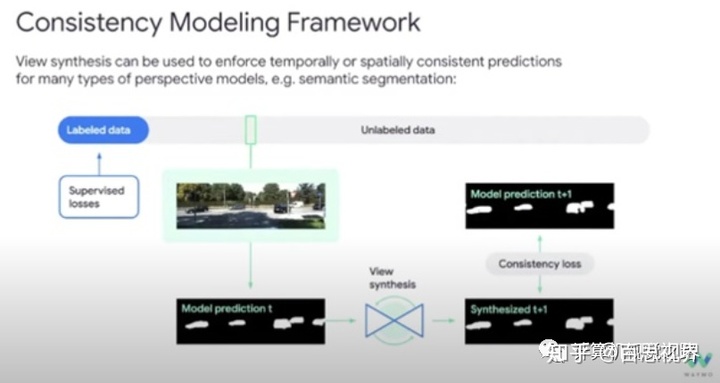
二、ViDAR
这方面没找到相关论文,仅放2张图作为参考:
三、传感器合成:SurelGAN
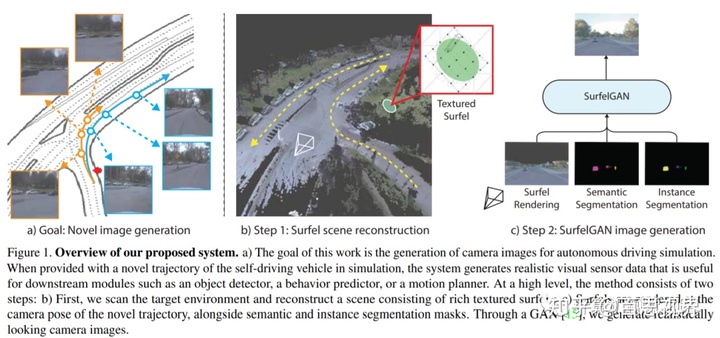
模拟仿真对自动驾驶相关技术的演进、减少测试成本有很大帮助,而且,精确模拟车辆传感器(如摄像机、激光雷达或雷达)至关重要。然而,目前的传感器模拟器利用游戏引擎,如虚幻或统一,需要手动创建环境、对象和材料属性。这种方法的可扩展性有限,在没有大量额外工作的情况下,无法生成真实的相机、激光雷达和雷达数据近似值。SurfelGAN则是根据有限的lidar和camera数据生成真实场景的样本。该方法利用纹理映射曲面从初始的车辆路径或路径集有效地重建场景,保留了丰富的物体三维几何和外观信息以及场景条件。然后利用SurfelGAN网络重建真实的摄像机图像,以获得场景中自动驾驶车辆和运动物体的新位置和方向。具体方法流程如下图所示。
四、多任务学习:Taskology
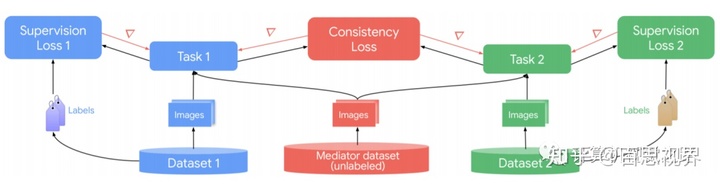
大家都知道,多任务训练对提高各个任务的性能,但是对标注数据要求比较严格,需要大量的多任务标注数据。而本文是显式地利用任务之间的已知关系,使用标记较少的数据来提高便可提高各个任务的性能。我们发现通过使用从物理、几何和逻辑导出的一致性约束来建立任务的内在关系,模型集合可以在没有共享组件的情况下进行训练,仅通过一致性约束作为监督(对等监督)进行交互。一致性约束强制执行任务之间的结构优先级,这使它们能够相互一致地进行训练,从而提高整体性能。将单个任务视为模块(与它们的实现无关)可以减少工程开销,从而将多个任务的集体培训降到最低。此外,集体训练可以分布在多个计算节点之间,这进一步有利于大规模训练。具体方法流程如下图所示。















 3400
3400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









