







本文主要记录学习的spark的基础知识,了解和熟悉spark的基本概念、原理以及架构流程。
一、基础介绍
1、概念
简单的定义是一个通用的分布式数据计算引擎。
Spark构建一套流、批一体化、多元化的大数据处理体系。借鉴MapReduce的分而治之思想,保留分布式并行计算框架,将中间数据存储在内存中,提升运行速率,同时提供丰富的API接口以及优秀的数据模型和计算抽象,提升开发效率。
2、特点
其特点对比MapReduce:
快:基于内存的计算。实现高效的DAG执行引擎,可以基于内存高效处理数据。
易用:支持Java、Scala、Python等API,使用户快速构建不同的应用。
通用:提供统一的解决方案可以用于批处理、交互式查询、流处理、机器学习、图计算等。减少开发和维护成本。
兼容:可以方便的与其他开源产品进行融合。
3、对比Hadoop
| 对比 | Hadoop | Spark |
| 类型 | 分布式基础平台,包括计算、存储、调度等。 | 分布式计算引擎 |
| 场景 | 大规模数据集上的批处理。 | 迭代计算、交互式计算、流计算。 |
| 价格 | 对机器配置要求低 | 对机器内存要求高 |
| 编程范式 | Map+Reduce, API较为底层,算法适用性较差 | RDD组成DAG, API较为顶层,方便使用 |
| 数据存储 | 中间结果存储在HDFS上,存储IO消耗,延迟大 | 中间结果存储在内存中,降低IO消耗,延迟小 |
| 运行方式 | Task以进程的方式维护,任务启动慢。 | 以线程方式维护,任务启动快 |
4、运行模式
Local 单机运行, 适用于测试练习。
Standalone 独立集群运行,M/S 架构,多用于测试练习。
Standalone-HA 高可用运行,基于Zookeeper 的高可用,避免Master单点故障。可用于生产。
On Yarn 集群模式,基于YARN的资源管理,Spark只负责任务调度和计算。计算资源按需伸缩,集群资源利用率高,共享底层存储。可用于生产。
On Cloud 集群模式,运行在云服务器上。
5、提交模式
5.1 提交命令
./bin/spark-submit --class 类名 --master spark://ip app-jar [app-args]
--class 表示要执行程序的主类
--master 指定运行模式,包括 local , yarn 等
app-jar 打包好的jar工程
app-args 传给main方法的参数
其他
--executor-memory 1G 指定每个executor 的可用内存
--total-executor-cores 2 指定所有节点使用的cpu核数
--executor-cores 指定每个节点使用的cpu 核数
5.2 不同运行模式下的提交命令
以官方提供的案例为参考
Local 模式:
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] /usr/local/spark/examples/jars/spark-examples_2.12-3.3.2.jar 10
Standalone 模式
spark-submit --class org.apache.spark.examples.SparkPi --master spark://m01:7077 ./examples/jars/spark-examples_2.12-3.3.2.jar 10
Standalone-HA 模式
spark-submit --class org.apache.spark.examples.SparkPi --master spark://m01:7077,m02:7077 ./examples/jars/spark-examples_2.12-3.3.2.jar 10
On yarn 模式
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.12-3.3.2.jar 10
二、核心组件
核心组成
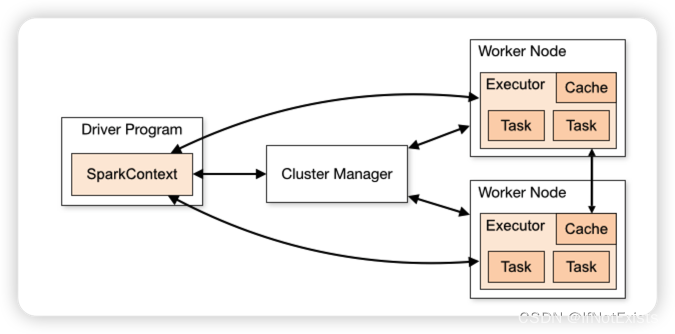
1、Driver
驱动器节点,主要用于执行Spark任务的main方法,即创建SparkContext对象,由SparkContext 和ClusterManager资源管理器通信,进行资源申请、任务分配和监控 以及程序执行完后关闭。
功能包括:
将用户程序转化成任务Job。
在Executor之间调度任务。
跟踪Executor的执行情况。
通过UI展示运行情况。
2、Executor
运行在Worker上的一个jvm进程。负责在Spark作业中运行具体的任务,任务间独立。Spark应用启动时Executor节点被同时启动,始终伴随着整个Spark应用的生命周期存在。如果出现故障或崩溃,Spark应用可以被调度到其他Executor继续执行。
功能包括:
负责运行组成Spark应用的任务,并将结果返回给Driver。
通过自身的块管理器,为用户程序提供内存存储。
3、Cluster Manager
集群管理器,存在Master进程中,用于资源调度和分配,并进行集群监控,根据部署模式的不同,可以分为Local、Standalone、Yarn等
4、Worker
运行APP应用的节点,独立部署环境中,用于并行处理数据和计算(类似Yarn的NodeManager)。
5、ApplicationMaster
用于向资源调度器申请执行任务的资源容器,运行用户自己的任务,监控任务执行状态,处理异常情况。是ResourceManager 和Driver 之间的解耦角色。
三、核心模块
核心模块(生态)
说明:图片来源互联网
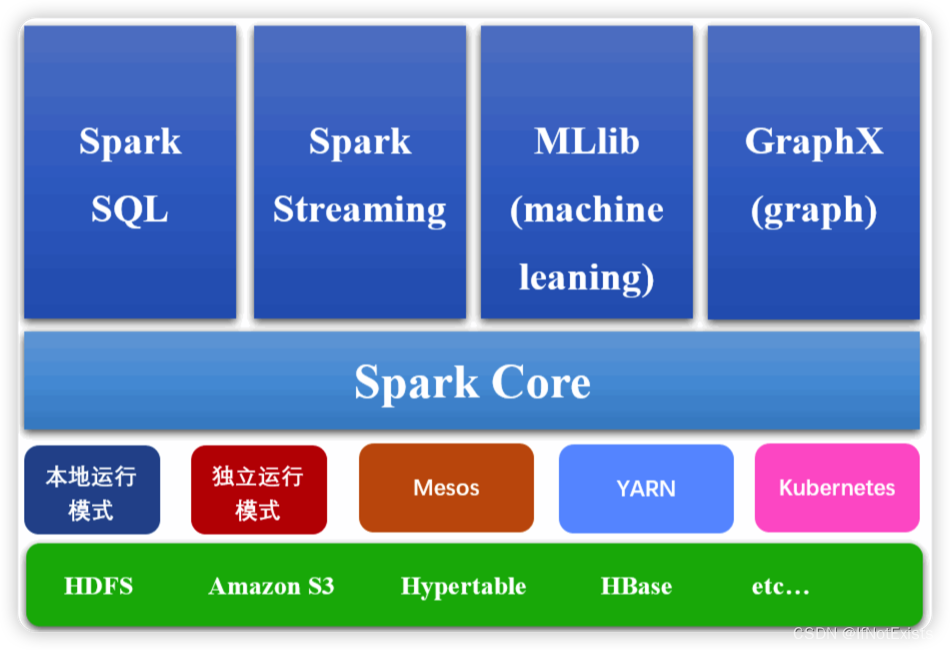
1、Spark Core
分布式大数据处理框架,实现Spark的基本功能,包括RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
特性:
提供了多种运行模式,可以使用第三方资源调度框架如YARN处理任务。
提供DAG的分布式并行框架,提供内存机制支持多次迭代计算或数据共享,减少迭代计算间数据共享的开销。
引入RDD抽象,分布在一组节点中的只读数据对象弹性集合。如果部分丢失可以通过重建等方式保障高容错性。
2、Spark Streaming
对实时数据流进行高吞吐、高容错的流式处理系统。提供对实时数据进行流式计算的组件以及操作数据的API, 并支持将结果保存在外部文件系统或数据库中。
特性:
动态负载均衡。
快速故障恢复机制。
流、批处理和交互分析一体化。
3、Spark SQL
用来操作结构化数据的程序封装包,使用SQL操作数据。
4、Spark MLlib
提供常见的机器学习ML功能的程序库,包括分类、回归、聚类、协同过滤等,还提供模型评估、数据导入等额外的支持功能。
5、GraphX
用于图计算的API, 性能良好,拥有丰富的功能和运算符,能在海量数据上自如的运行复杂的图算法。
四、核心概念
1、Job
用户程序一个完整的处理流程。由Action算子触发,后续介绍原理时会详细讲解。
2、Stage
一个Job 可以被分割成多个Stage, Stage之间是串行的。后续在介绍原理时会详细讲解Stage的划分逻辑。
3、Task
一个Stage包含一个或多个Task, 也是任务处理的最小单元。
4、Partition
分区,一个完整的数据源会被切分成多个分区方便发送到不同的Executor上执行。
5、RDD
弹性的分布式数据集,是Spark基本的数据抽象,代表不可变的、可分区的、其元素可并行计算的集合。
其中:
弹性:包括 存储的弹性、容错的弹性、计算的弹性、调度的弹性、分片的弹性。
分布式:数据存储在分布式大数据集群的不同节点。
数据集:封装了计算逻辑,但不保存数据。
数据抽象:抽象类,需要子类具体实现。
不可变:封装的计算逻辑不可以改变,如果需要改变则需重新生成RDD,在新的RDD中实现新的计算逻辑。
并行计算:由于数据是分区的,所以支持并行计算。
6、并行度
包括资源的并行度 和 任务的并行度。
其中:
资源的并行度由节点数(Executor)和CPU数决定;
任务的并行度由Task数量和Partition 决定,默task 数 和 partition数相等。
7、DAG
有向无环图,为了解决MapReduce 框架的局限性。
五、任务流程
图片来源于互联网
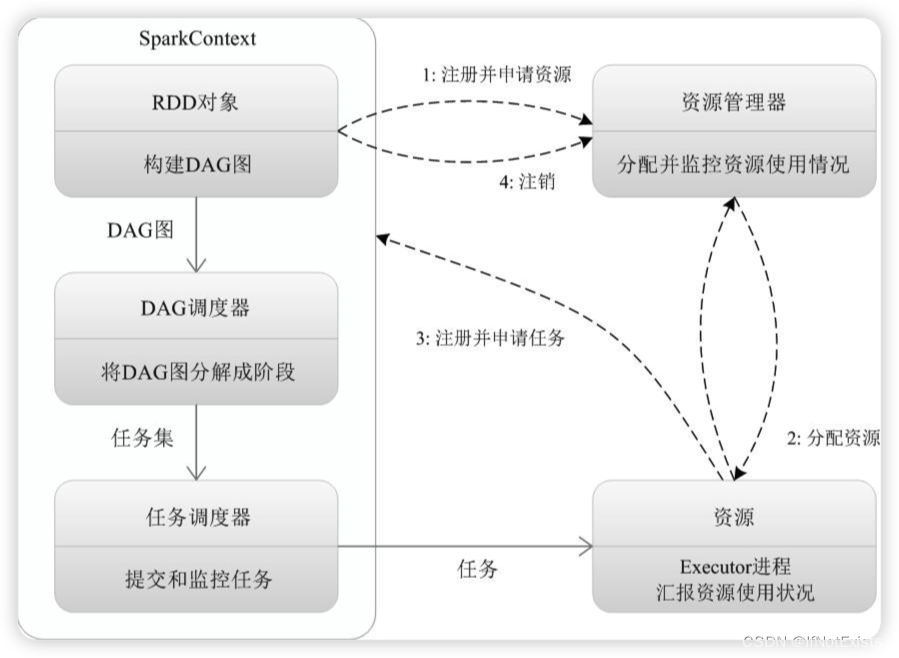
说明:
1、SparkContext 向资源管理器注册并申请资源运行Executor。
2.1、资源管理器分配Executor,并启动。
2.2、Executor 发送心跳至资源管理器。
3.1、SparkContext构建DAG图。
3.2、DAGScheduler 将DAG分解成Stage,并把每个Stage上的TaskSet发送给TaskScheduler。
3.3、Executor 向SparkContext 申请task。
3.4、TaskScheduler将Task 发送给Executor运行。
3.5、同时SparkContext 将代码发放给Executor。
4、Task 在Executor 上运行,待结束后释放资源。














 3659
3659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









