






1. Anchor

可以根据实际任务,修改anchor预设的大小和scale ,也就是说stride + anchor ratio + anchor scales都可以调整,选择不同stride确定了feature map的大小,stride就是说下采样的比例,4就是256*256变成64*64,ratio确定了纵横比和尺度。

2. IoU loss与focal loss
- IoU loss:用来计算pred box与ground true之间的差异,用来边界框损失函数的计算;
- focal loss:用来平衡正负样本不均衡的问题,由RetinaNet提出使用与One-Step目标检测算法上的一个技巧
IOU的进化史可以分为Smooth L1 loss、iou loss、giou loss、diou loss、ciou loss, α-iou
具体那个IOU可以查一下
focal loss 出资retinanet,计算流程如下:


focal loss也有一些问题,如果让模型过多关注 难分样本 会引发一些问题,比如样本中的离群点(outliers),已经收敛的模型可能会因为这些离群点还是被判别错误,总而言之,我们不应该过多关注易分样本,但也不应该过多关注难分样本;

focal loss变体 :
- Equalized Focal Loss:Equalized Focal Loss for Dense Long-Tailed Object Detection

就是说focal对于所有的类都一样,而这里认为存在不同类别的正负样本不均衡性的问题,意思就是,对于长尾数据集中的长尾数据来说,正样本更少了,意思是正负样本就更不均衡了,所以需要r变大点,对稀少样本的负样本加以抑制,所以rb就是focal中的r,多了一个rvj就是说对于不同的类别设置的不同,对于稀少样本rvj更大

这里借鉴一篇其他论文的思想,用正负样本的梯度累计来做,对于正负样本均衡的gj就大,对于稀少的样本gj就小,为了满足,我们把限制到[0,1]范围内。超参数s用来缩放EFL中的的上限。
但是这又带来了新的问题,对于相同的,γ越大,loss越小。这导致了当我们想要更加关注一个类别的训练的时候,我们不得不牺牲掉其loss在整个训练过程中的贡献。这导致了稀少类别无法取得更好的效果。也就是说,原本的稀少样本的loss,因为更大的r,确实对于负样本抑制了,但是同时正样本也更小了,整体稀少样本对于loss的贡献更小了,这有肯定不行
所以就有前面这一坨,可以看到r越大,那么EFL对于稀少类别的loss的贡献显著增加了。
- cyclical focal loss:提出一种新颖的cyclical focal loss,并证明它是比交叉熵 softmax 损失或focal loss更通用的损失函数,为平衡、不平衡或长尾数据集提供了卓越的性能。
虽然已经发现focal loss损失在具有不平衡类数据的任务中是有益的,但它通常会在使用更平衡的数据集进行训练时降低性能。因此,对于大多数应用来说,focal loss 并不能很好地替代 cross-entropysoftmax 损失。
核心一段话,就是说开始和后期对于简单样本加权,中期开始着重训练困难样本,


看起来很扯,就是把focal中的剪换成加,那这样做的意义在于 看图

意义在于如下:

意思就是说根据这个循环学习的原理来说,刚开始你这个模型还不太行的时候,就是要靠这个简单的样本来优化,到训练中期才是利用困难样本去提高模型的泛化性。当困难样本学的差不多了,学的很牛了,最后再去学习这个简单样本,更深层次的挖掘一些信息。
所以最后的公式就是


可以看到ei是当前的epoch,en是总共的,fc大于1,开始和结束时,3的值很大,也就是hc的loss比重更大,更注重简单样本,中期lc的比重更大,注重困难样本。
- GHM(gradient harmonizing mechanism) :paper Gradient Harmonized Single-stage Detector
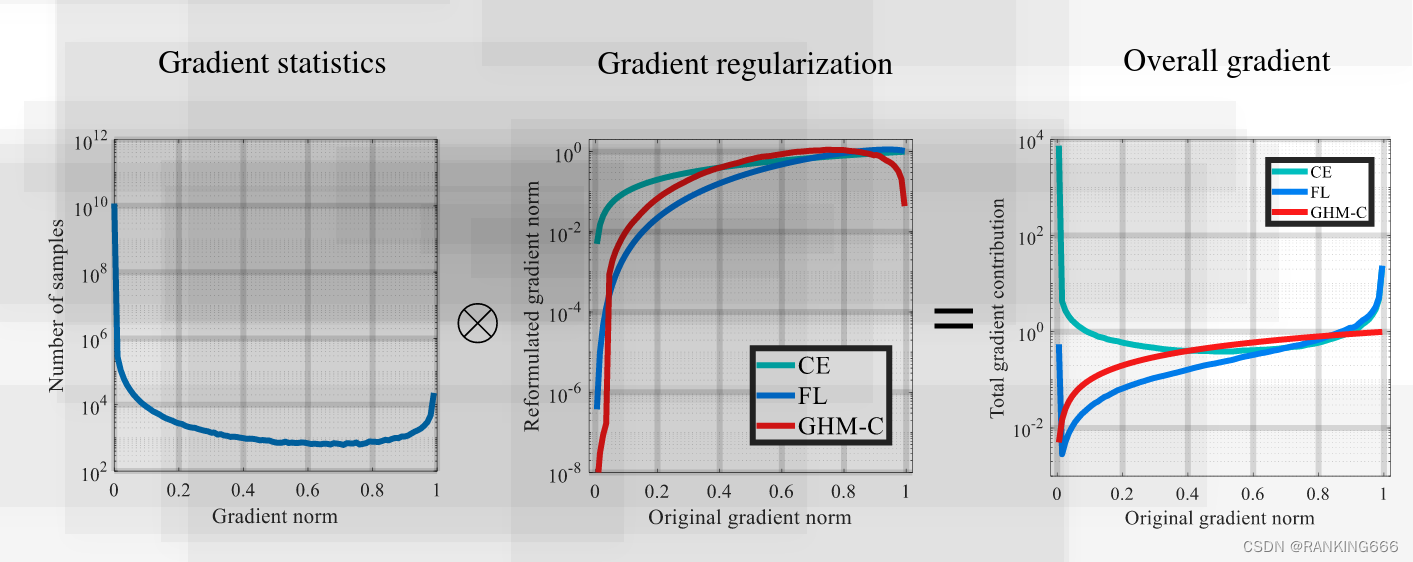
核心图,首先文章的出发点意思是Focal Loss是从置信度p的角度入手衰减loss,而GHM是一定范围置信度p的样本数量的角度衰减loss。什么意思?
看第一个图:我们确实不应该过多关注易分样本,但是特别难分的样本(outliers,离群点)也不该关注。也就是最困难的样本 
3. 样本不平衡问题:
ATSS: Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
这篇文章就是首先探讨了一下anchor base和anchor free的区别,经过一系列实验证明,主要是在于正负样本的选择策略差异导致的。
首先,作者拿retinanet和focos两种检测模型作为对比,尽可能的消除两者的差异

主要是一些tricks上的差异
这样二者之间的gap只有0.8了,而这0.8的gap可能来自于两点:
1. 就是正负样本选择的差异
2. Regression的方式不同,一个基于anchor,一个基于point。
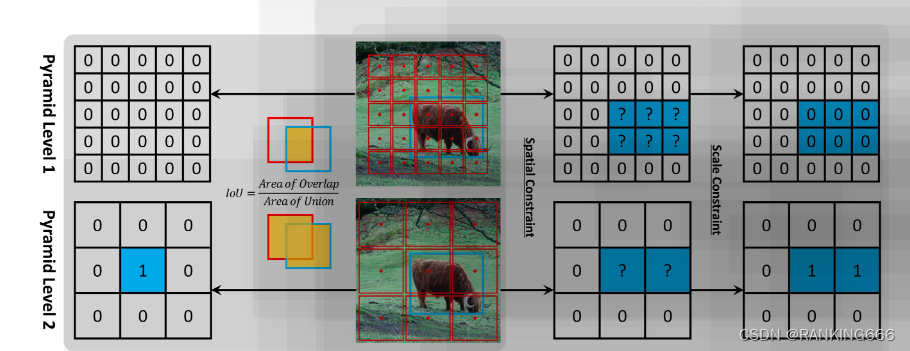
retinanet其回归的基点是anchor,首先要判定哪些anchor是正样本,哪些anchor是负样本,然后在正样本anchor的基础上再做位置的回归。而判定anchor是否是正样本,是通过计算anchor和groundtruth的IoU来完成的,这样做的缺陷很明显,anchor是正样本还是负样本非常受限于anchor的设计,比如第一行RetinaNet中可以看到,蓝色的groundtruth包含了6个anchors,但是受限于anchor的大小,他们的IoU没有达到阈值要求,因此这些anchor都被判定成了负样本,显然这样是不太合理的。
而对于FCOS,作为center-base的方式,是通过判定feature上的每个点是否落入到groundtruth中来判定正负样本的,很显然这样就摆脱了类似于anchor这种受限于hard-craft的缺陷, 这也是FCOS效果优于RetinaNet的原因:基于center的方式,能够更有效的选取更多的正样本(不过其实这个点在FCOS的论文中也有提到过)。

对于回归来说,retinanet通过回归框,而fcos通过回归中心点到边的距离
于是乎,作者又做了一些交叉验证

发现相同的正负样本定义下的RetinaNet和FCOS性能几乎一样,不同的定义方法性能差异较大,而回归初始状态对性能影响不大。所以,基本可以确定正负样本的确定方法是影响性能的重要一环。
atss的具体流程为
 侵删
侵删
这样就是anchor base也考虑到了中心点
UMOP: Progressive Hard-case Mining across PyramidLevels for Object Detection
之前的平衡正负样本的方法都是旨在如何定义正样本的出发点去解决正负样本的不平衡情况,不论是Focal Loss还是ATSS都是巧妙的设计定义了正样本的选择,那么当针对不同层级上的正负样本不平衡情况,也就是说基于FPN不同的层存在正负样本不平衡的问题
作者通过实验证明FPN的性能在一定程度上受到特征层级之间不平衡问题的限制。

可以看到不同的FPN层,正负样本不一致。不同层级的标签分布不同,每个模型的P7在训练过程中更有可能获得正样本;作者认为固定超参数设置的Focal loss不能同时对所有金字塔级别进行良好的权衡。
为缓解Level Imbalance影响,本文提出一种UMOP(Unified Multi-level Optimization Paradigm),它包含两个成分:
- 基于不同层级目标重采样考量,对每个层级特征添加独立分类损失进行监督
- 提出一种跨金字塔层级的难例挖掘损失,且不会引入额外的层级相关设置

具体公式细节: https://www.zhihu.com/people/li-hong-58-80
Progressive Hard-case Mining across Pyramid Levels in Object Detection论文阅读_Laughing-q的博客-CSDN博客
后续还有更牛的simOTA,YOLOX深度解析(二)-simOTA详解 - 知乎














 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









