










来源:投稿 作者:顾相欢
编辑:学姐
AAAI-2022|定制对话的人设和知识背景
原文标题:
Call for Customized Conversation: Customized Conversation Grounding Persona and Knowledge
原文链接:
https://arxiv.org/abs/2112.08619
一、Introduction
人类在对话时,考虑到的除了知识信息,还与人设信息有关。比如你向一个素食主义者推荐餐厅的时候,总归不会说哪家炸鸡店好吃。根据这一点,在人机对话中结合先验知识和人设信息是非常重要的。
(下图第二种回答是不是比第一种更自然?)

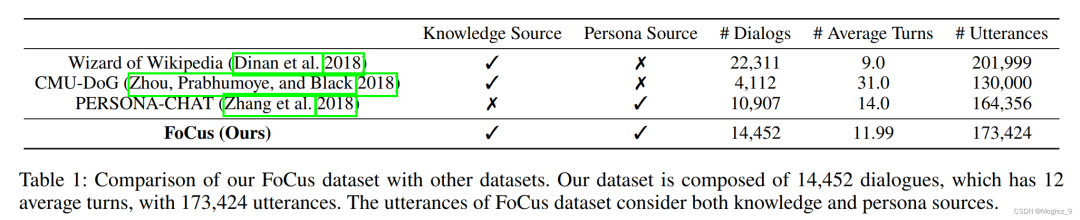
二、FoCus Dataset
在本项目中,作者构建了一个新的数据集,叫做FoCus。
将对话的情景设定为谈论一些地标,与其相关的知识有地标的历史、艺术设计、建筑结构、作用、旅游业和地质信息。会话代理就要根据人设来告知用户不同方面的地标信息。

1、Dataset Creation
地标信息来自于维基百科上5316个页面,每个页面内容超过8000字,涵盖了历史、旅游、建筑等多方面信息。同时,数据集中还包含27170个有关于人设的语句,这些语句中含有地标的关键词。
在创建人设时,我们先用五个句子描述角色的背景。随后在给定的维基百科页面上提取关键字,结合关键字创作角色语句。
在创建对话集时,标注者以人机交替角色的形式进行多轮对话,回答时要标记他们用了有关于人设或是知识的句子。而且我们发现,来自单人建立的数据质量更高,因为提出问题的人比其他人更清楚自己要得到怎样的回答。
2、Dataset Analysis
机器说的语句(141.13)比人类说的语句 (40.94)要长的多,因为它用到了很多专业知识。
机器语句可以被分为三类:告知、确认、建议。“告知”只有知识信息,没有人设信息。“确认”复述了用户的偏好并表达赞同。“建议”提出了用户可能喜欢的额外信息。
三、Model
本对话模型由检索模块和对话模块构成,检索模块根据问题寻找相应的知识信息,对话模块根据知识信息、人设信息和过去的对话生成回复。
检索模块计算问题与可能的知识信息之间的TF-IDF分数,将范围缩小到维基百科的五个段落之间。
对话模块由上下文相关、人设预测、知识信息预测和语言建模组成。它先生成当前对话轮次的上下文相关表示,然后模型在给定上下文相关表示的情况下学习使用哪个人设语句和知识信息。

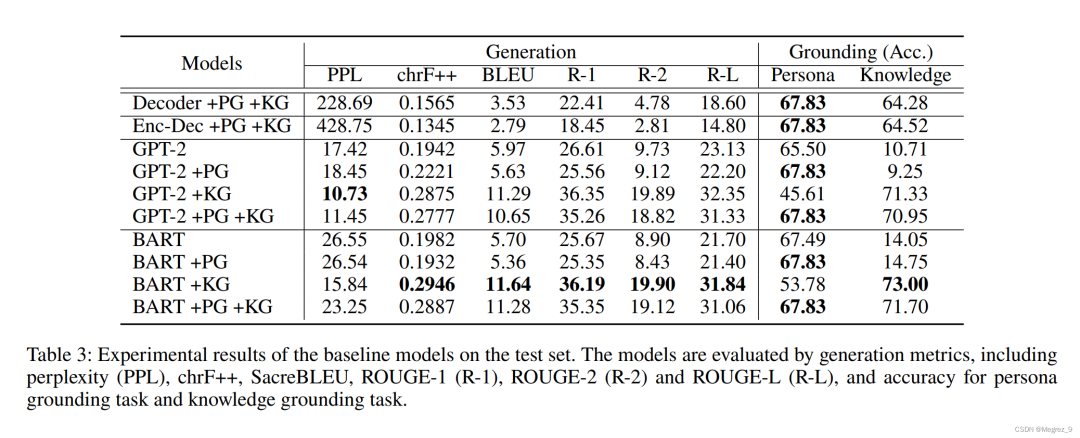
四、Experiments
使用到的Baseline语言模型有:transfromer decoder、transfromer encoder-decoder、GPT-2\BART。
自动评估指标:ppl、BLUE、ROUGE-1-F、ROUGE-2-F,准确率Acc
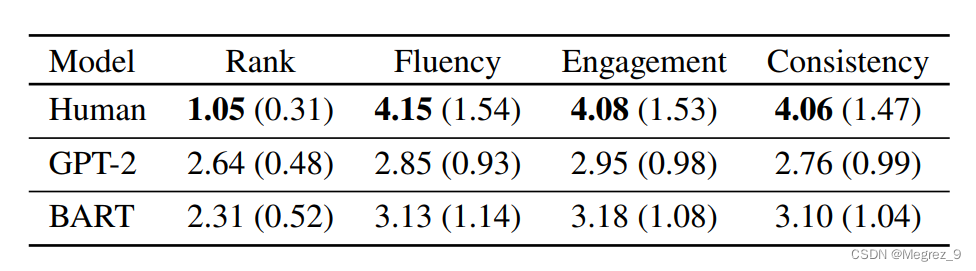
人工评估指标:
五、Conclusion
本文介绍的数据集能够结合人设信息和维基百科页面中的知识信息,它的表达更自然也更难被机器模仿。FoCus数据集可以帮助构建更多更像人类的智能体,使用该数据集训练的模型可以在未来使对话代理更有吸引力,同时有更渊博的知识。
关注下方《学姐带你玩AI》🚀🚀🚀
带你了解更多人工智能前沿资讯
论文解读视频代码数据集回复“500”免费领
码字不易,欢迎大家点赞评论收藏!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









