










 AlexNet通过5个卷积层和3个全连接层实现图像特征提取与分类,使用ReLU激活函数避免梯度消失,maxpooling简化计算并保持精确性,LRN增强局部响应,数据增强策略提高模型泛化能力,Dropout防止过拟合。该模型在LSVRC-2012比赛中取得优异成绩,展示了深度学习在图像识别领域的突破。
AlexNet通过5个卷积层和3个全连接层实现图像特征提取与分类,使用ReLU激活函数避免梯度消失,maxpooling简化计算并保持精确性,LRN增强局部响应,数据增强策略提高模型泛化能力,Dropout防止过拟合。该模型在LSVRC-2012比赛中取得优异成绩,展示了深度学习在图像识别领域的突破。
来源:投稿 作者:cairuyi01
编辑:学姐
AlexNet在LSVRC-2012测试集中得到了36.7%的Top1 error和15.4%的Top5 error的成绩,成为了图像分类的冠军,是当时的最优性能。它的Top5 error抛离亚军超过10%,其经典之处值得我们⼀看再看,本⽂将围绕笔者在学习这篇论⽂后的笔记进⾏整理,希望能借此机会温故⽽知新。
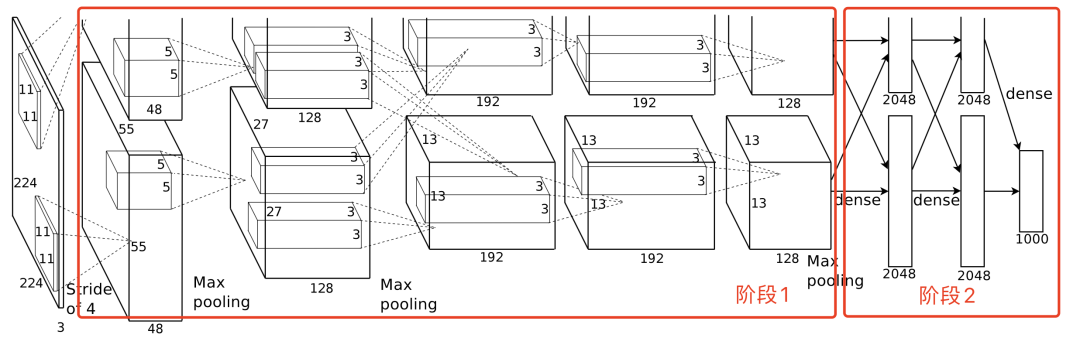
【图1】
AlexNet的网络结构如图1,摘取自原论文。
从这个结构来看,模型分成了两个阶段,已在图1中标记:
1)模型对输入的图像进行特征提取。
2)对提取的特征进行分类预测。
在第一阶段中,模型通过5个卷积层对图像进行特征的提取,其中,每个卷积层都会有ReLU的激活层,第1第2层会带有LRN层,第1第2第5带有maxpooling层。
在第二阶段中,模型会接收来自第一阶段的特征图,并通过3个全连接层进行分类,除了最后一层接入softmax进行分类外,另外两层均带有ReLU的激活层。
下面,笔者整理了AlexNet中的6个关键点:
note 1:卷积层是如何起到特征提取的作用
对照传统的计算机视觉中的特征提取方法,我们可以更好地理解这个问题。
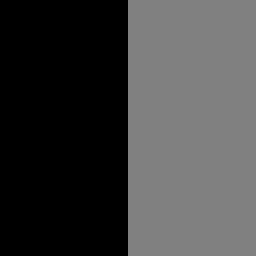
【图2】
我们可以通过一个特定的卷积核来提取图像中的特征。例如,图2中的黑色和灰色两个边缘形成了一条垂直的轮廓线,灰色轮廓线与左边的区域有很大的梯度变化,直观地理解为灰度值的变化很大;而灰色轮廓线与右边的区域没有梯度变化,值直观地理解为灰度值没有变化。反之,黑色轮廓线有相反的特征。

【图3】
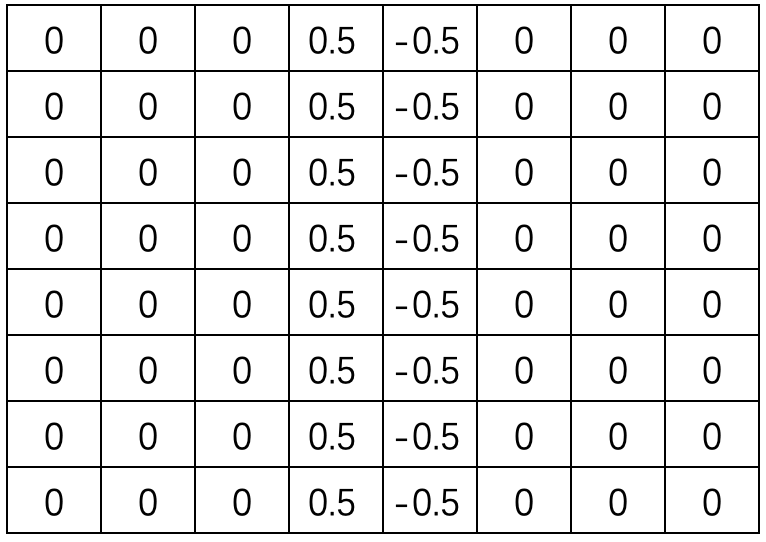
【图4】
借助这些特征,我们就可以设计一个卷积核把特征识别出来。如图3所示,左边是图2图像的灰度值矩阵,后面是拉普拉斯算子的卷积核,通过这个个卷积核与图像进行卷积计算,我们可以得到了一张特征图图4。

【图5】
在AlexNet中,这个特征的提取不需要人为设计和操作,由模型在训练的过程中自行寻找和纠正。它能设计出很多卷积核来识别人眼关注不到的特征。这种开放性给予了模型极大的灵活性和创造力,能识别和提取出意想不到的,具备后续分类可行性的特征。图5是论文中AlexNet第一个卷积层的卷积核的可视化效果。
note 2:maxpooling为什么能兼顾简化计算量和精确性
maxpooling让输出的特征图仅为输入特征图尺寸的1/4(1/2*1/2),这为后续的卷积操作或全连接层操作提供了尺寸更小的特征图,从而大大简化了计算量。
这会不会影响精确性呢?我们来看:
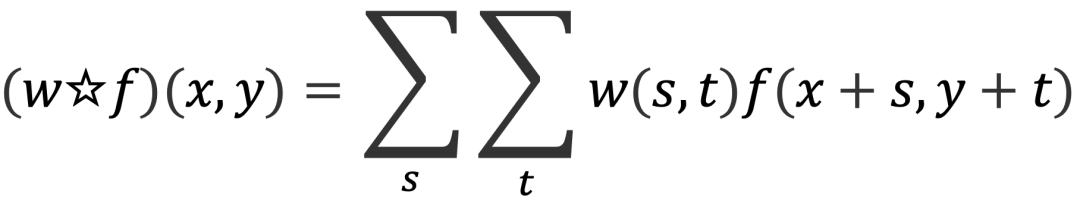
【式1】
式1是相关(correlation)的操作运算。w是核,f是图像,相关运算后的新坐标点上的值等于核上每一个值分别与图像上对应坐标上的值进行乘积,再把每一个乘积的结果相加到一起。通过这个式子,我们可以得到一个结论,用一核与图像进行相关运算,相似度越高,那么响应度越高,计算得到的结果值越大。
卷积与相关运算的区别在于是否把核进行180度旋转,所以,如果卷积核与图像的相似度越高,特征图上得到的值就越大,此时,maxpooling取临近的最大值池化缩小特征图,是能够压缩数据量的同时保留必要的信息量的。
此外,AlexNet在设计maxpooling时采取的卷积核是3*3,而步长是2,这使得池化时相邻像素之间的关系也被保留了下来,尽可能地保留了特征图的信息量。
note 3:Local Response Normalization(LRN)是如何起作用的
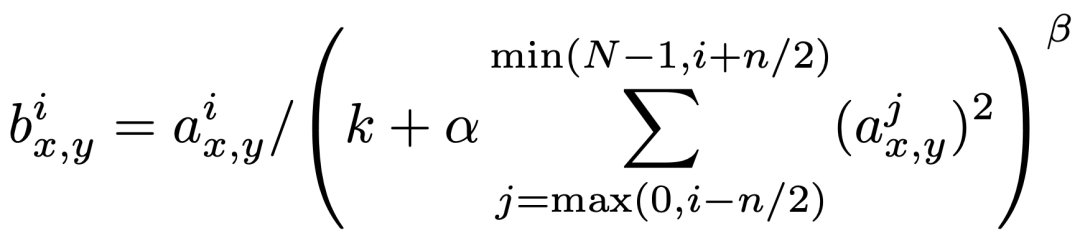
【式2】
式2是从原文中摘取的Local Response Normalization的公式。其中,b是输出的特征图的值,a是输入特征图的值,i是当前的通道,j是相邻的通道。
我们简单地理解,输出数据(等式左边的结果值)与当前输入数据(等式右边的分子)以及当前输入数据和它附近通道的数据(等式右边的分母)有关系。举例说,输入值A数值大,输入值B数值小,那么A/(A+B)>B/(A+B),这就起到了响应压制的作用。这一操作保证了高响应的值特别突出。
note 4:ReLU激活函数的好处
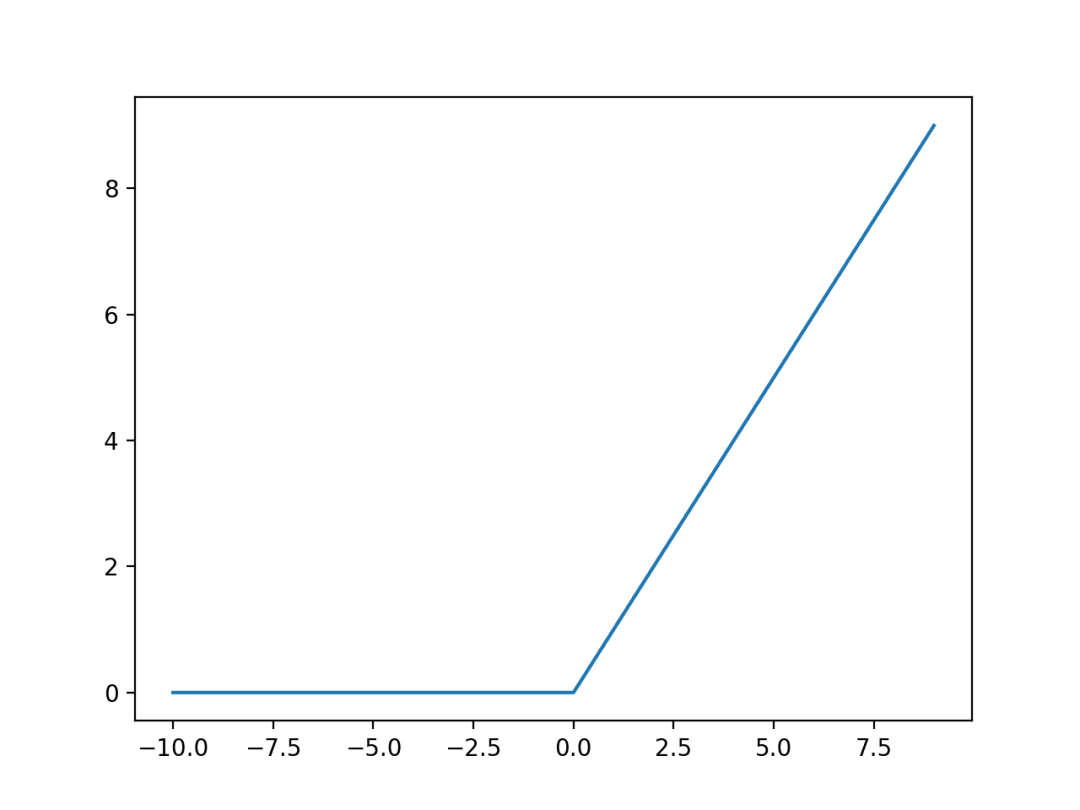
【图6】
从图6中我们可以看到ReLU的函数图像,在x大于0的部分梯度等于1。与sigma的函数相比,它不会出现x的取值越大梯度越小的饱和情况,从而保障了梯度在反向传播时的性能。
note 5:Alexnet使用的数据增强技术

【图7】
在训练时,Alexnet会把训练集中的图片调整为256*256的尺寸。之后,分别从左上角,右上角,左下角,右下角以及中间裁剪出224*224的图片,以一变五地增加了训练集中的数据量,如图7。
此外,这五张图之间的关系类似于图像中的物件被平移了。由此扩充的数据集也有利于提取图像特征时的平移不变性。
note 6:Dropout的注意事项
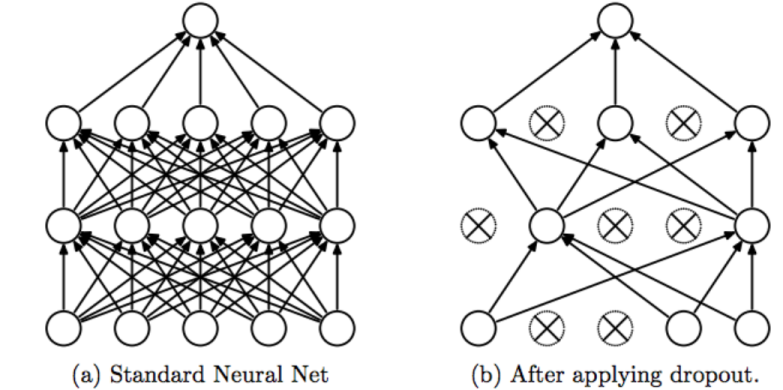
【图8】
图8中展示的是Dropout的操作,它在训练时,会在全连接层中随机使得某一定比例数量的神经元失活,比如论文中是使得50%的神经元失活。值得注意的是,Dropout在做分类预测时,它的处理方式与训练时是不同的。依然以前文谈及的训练时50%的神经元失活作为例子,Dropout在预测时所有的神经元都是激活状态的,但权重值会乘以0.5,以作为补偿。
以上是笔者在学习AlexNet后整理的笔记,这六点中的前四点可以视为AlexNet模型设计的一些特点,而后两点则为作者训练AlexNet所使用到的一些技巧。希望也能为你理解AlexNet带来帮助和启发。
关注下方《学姐带你玩AI》🚀🚀🚀
CV/NLP顶会必读论文PDF原文资料包
回复“CVPR”或者“ACL”免费领取
码字不易,欢迎大家点赞评论收藏!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









