









Transformer现在还能怎么做创新?不妨考虑结合特征融合。这种思路意在利用Transformer的自注意力机制和特征融合技术的优势,以提高模型的性能、降低计算成本以及增强模型的泛化能力。
比如斯坦福最近的新作Fusion-Vital,一种新颖的视频-射频(RGB-RF)融合Transformer,采用了Transformer-based fusion strategies和cross-attention机制来对齐和融合多模态特征,有效地捕捉微观生理标志,预测误差降低了83.4%。
该成果也收录于顶会AAAI中,另外还有CVPR 2024 的MiKASA,在处理复杂的视点依赖描述时,实现了显著的性能提升。可见特征融合+Transformer在各大顶会上的热门程度。
为方便论文er了解前沿,本文整理了这方向12篇最新的论文,有开源代码的都放上了,需要的同学可无偿获取~
全部论文+开源代码需要的同学看文末
Global-correlated 3D-decoupling Transformer for Clothed Avatar Reconstruction
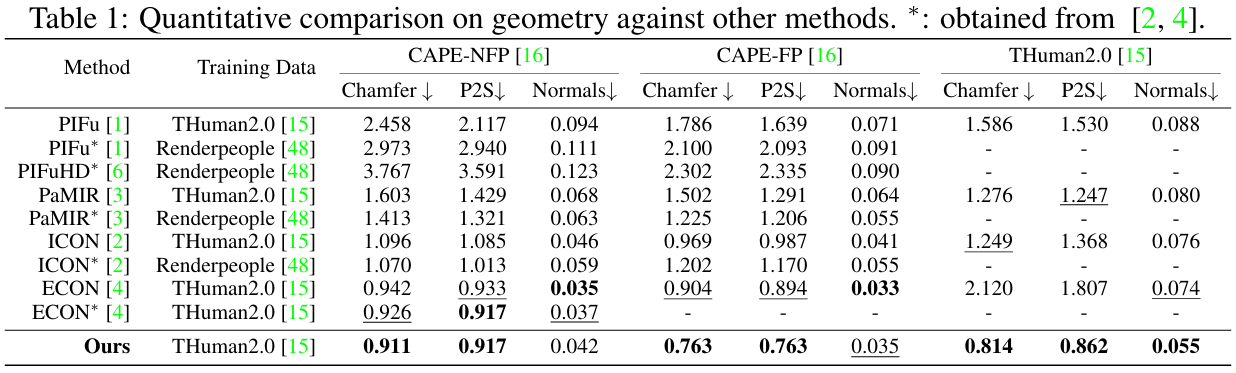
方法:论文旨在通过单张图像重建3D穿着人类模型,提出了一种基于Transformer的全局相关3D解耦方法(GTA),结合空间查询与先验增强查询的混合先验融合策略,显著提升了几何与纹理重建的精度,并通过在CAPE和THuman2.0数据集上的实验验证了其优越性。
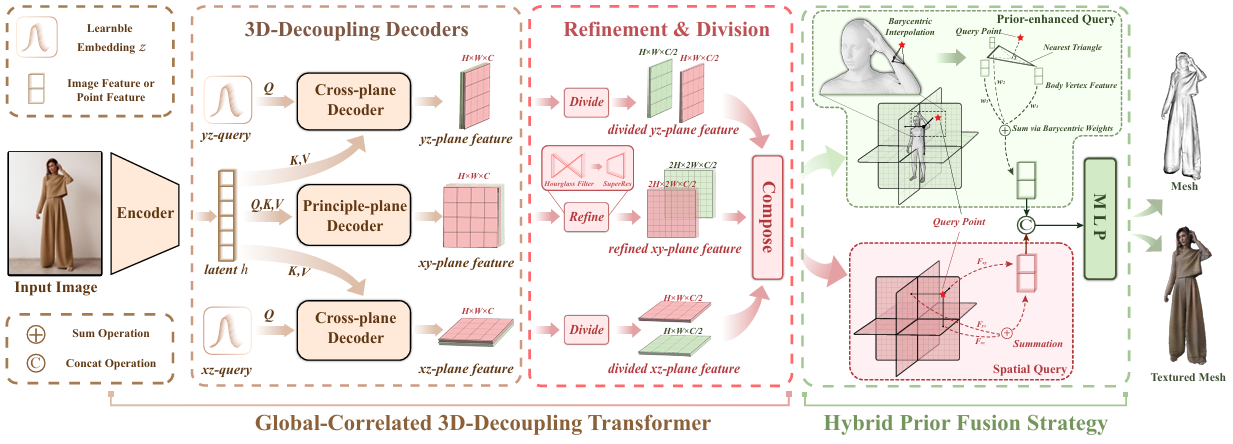
创新点:
-
创新性地应用于单目人像重建任务,通过有效解耦三平面特征,大幅提升从2D图像重建穿衣人像的能力。
-
结合空间查询(SQ)和先验增强查询(PQ)的优点,优化几何性能并保持纹理质量。
-
使用隐函数表达空间几何场,包括占用场和颜色场,通过引入人类体型先验知识,改善了在挑战性姿态下的几何重建质量和准确性。
Relating CNN-Transformer Fusion Network for Change Detection
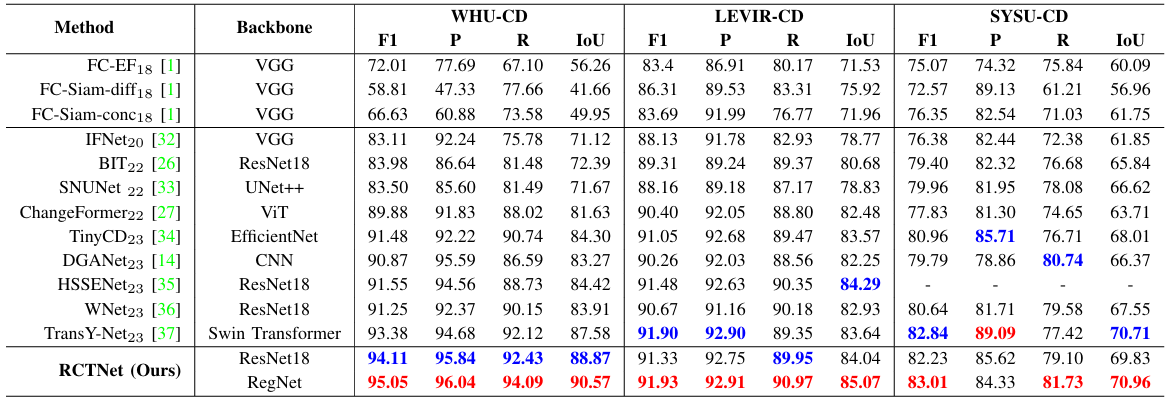
方法:论文提出了一种名为RCTNet的深度学习方法,结合了卷积神经网络和Transformer的优点,利用高效的特征提取与融合策略,显著提升了检测精度,并在多个数据集上验证了其相较于现有方法的优越性,同时保持了计算效率。
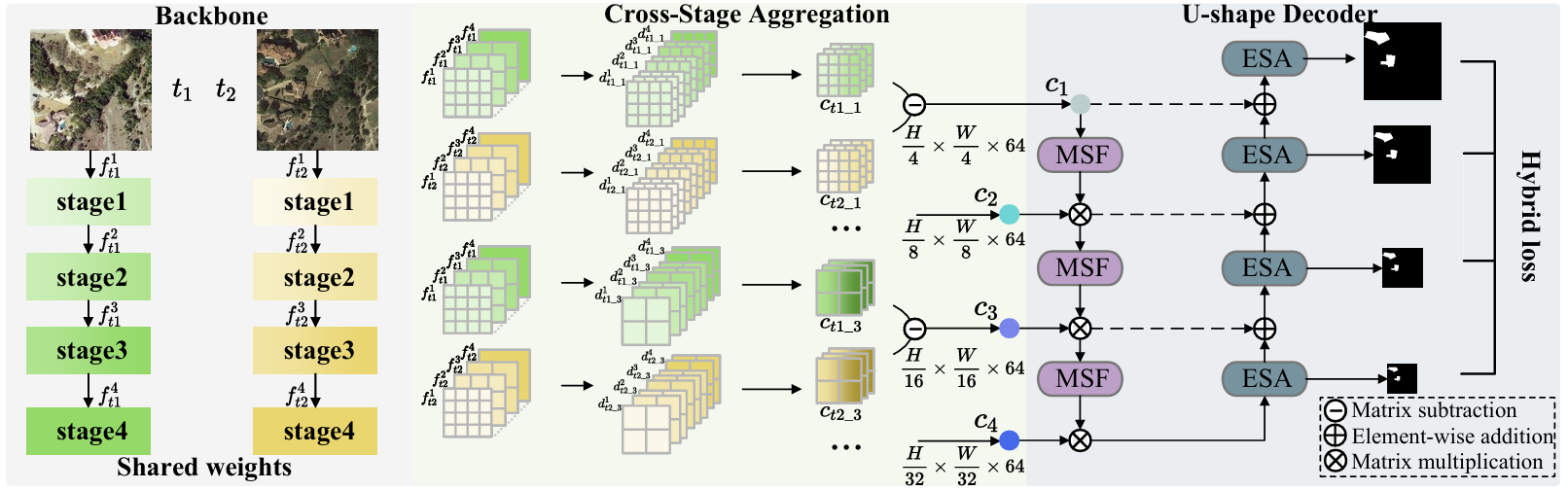
创新点:
-
CSA模块通过并行分支处理来自不同阶段的特征图,实现特征的无缝融合。
-
MSF模块在解码器中引入多尺度特征提取机制,进一步提升了特征表达能力。
-
ESA模块利用变压器机制,将全局语义关系引入解码器的每一层。
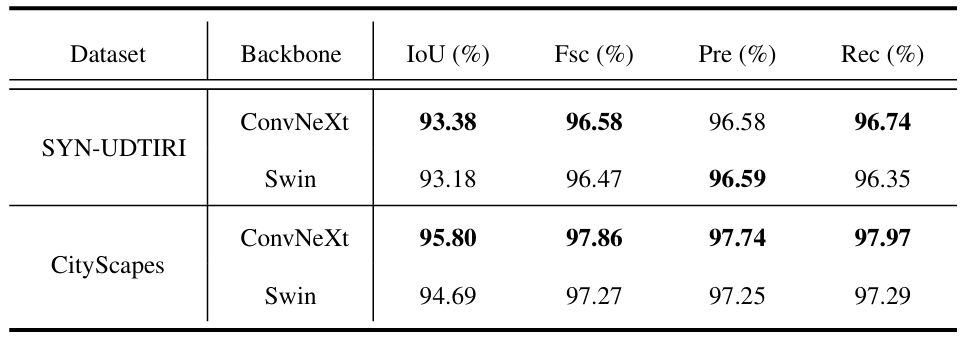
RoadFormer: Duplex Transformer for RGB-Normal Semantic Road Scene Parsing
方法:本文引入了RoadFormer,一种新颖的双工Transformer架构,通过异构特征的自注意力融合和重校准,在语义道路解析中实现卓越性能,特别是在检测道路缺陷方面,并通过创建SYN-UDTIRI数据集填补了现有研究中的数据融合研究空白。
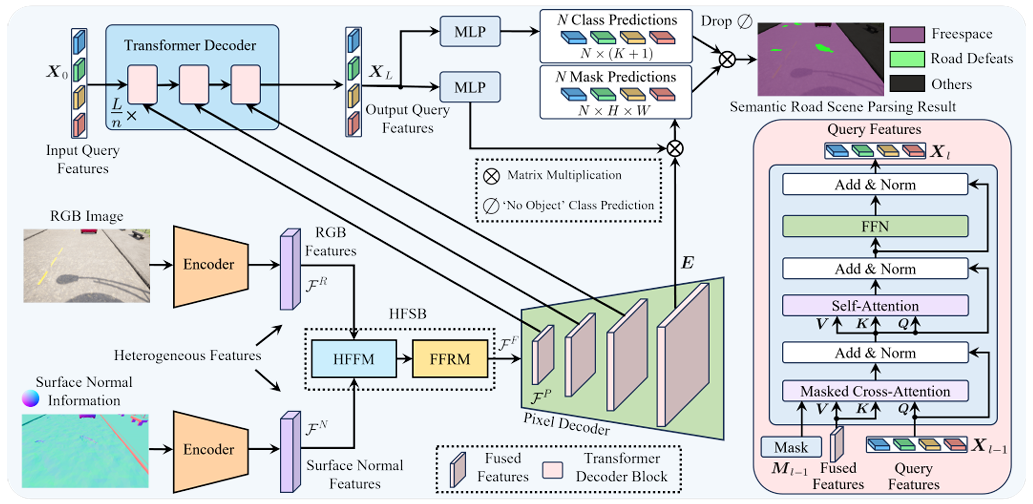
创新点:
-
RoadFormer引入了一种新颖的双工Transformer架构,用于道路场景解析。该架构包含一个异构特征协同块(HFSB),利用自注意力机制改进特征融合和重校准。
-
创建了一个名为SYN-UDTIRI的大规模、多源合成数据集,专门用于包含道路缺陷的场景理解。
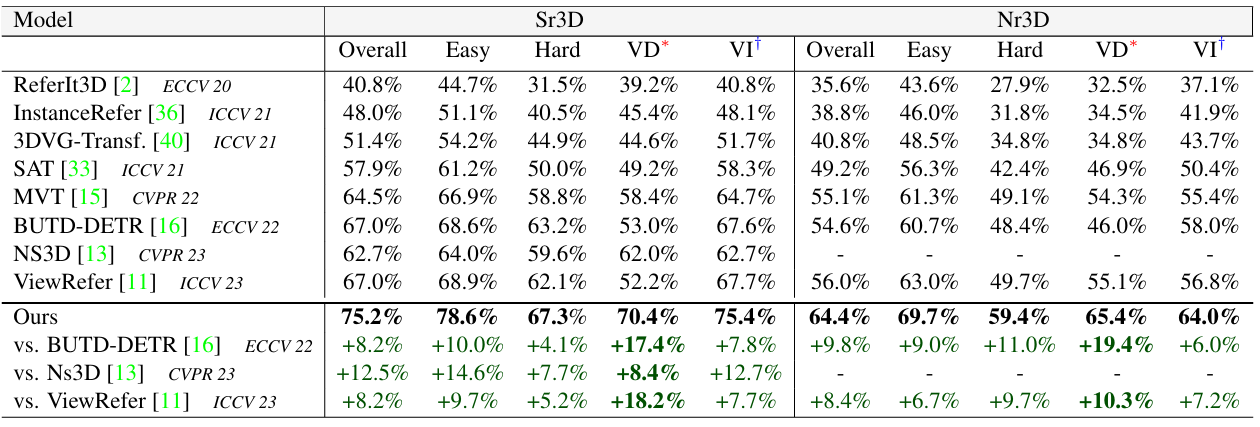
MiKASA: Multi-Key-Anchor & Scene-Aware Transformer for 3D Visual Grounding
方法:研究介绍了MiKASA Transformer模型,通过整合场景感知对象编码器和多锚点技术,显著提升了3D视觉定位中对象识别和空间理解的能力,填补了现有模型在解释性和识别精度上的不足,并在Referit3D挑战中表现出色。
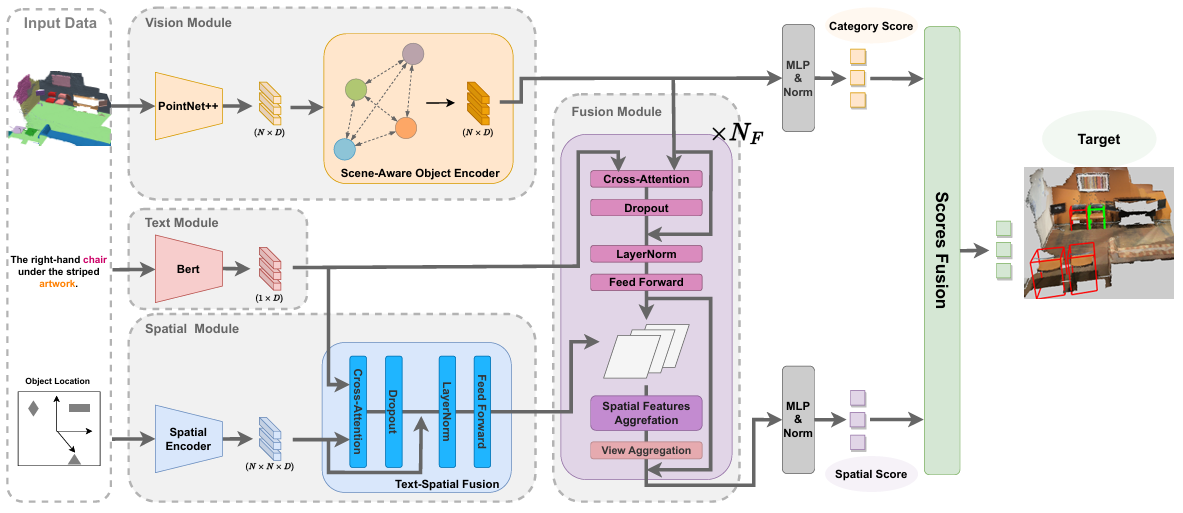
创新点:
-
通过集成场景信息来改进对象分类能力,该编码器不仅考虑单个对象的特性,还结合其周围对象的信息,提高了模型在对象识别中的准确性。
-
本技术通过重新定义目标对象的相对坐标,增强了空间理解能力。
-
该架构利用后期融合策略分别处理数据的不同方面,从而提高模型的准确性和可解释性。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“变形特征”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









