









分享个顶会顶刊热门方向:多模态自监督学习。是真挺热的,简单看了几篇研究,不是一区TOP就是CCF-A。比如AAAI 2025的Mentor系统、顶刊IEEE IOTJ的SketchTriplet方法(下文都会细说)...
另外还有LeCun谢赛宁的新作,验证了SSL在多模态任务中超越CLIP的潜力。非常建议对多模态自监督学习感兴趣,且有论文需求的同学研读。我这边也打包好了最前沿的11篇成果,基本都有代码,无偿分享!掌握这些idea顶会顶刊中稿率up!
最后再分享一些多模态自监督学习近期比较热门的子方向:跨模态对比学习、模态生成式预训练、时序多模态对齐、多模态与大模型结合...没思路的同学可以深入挖掘一下。
全部论文+开源代码需要的同学看文末
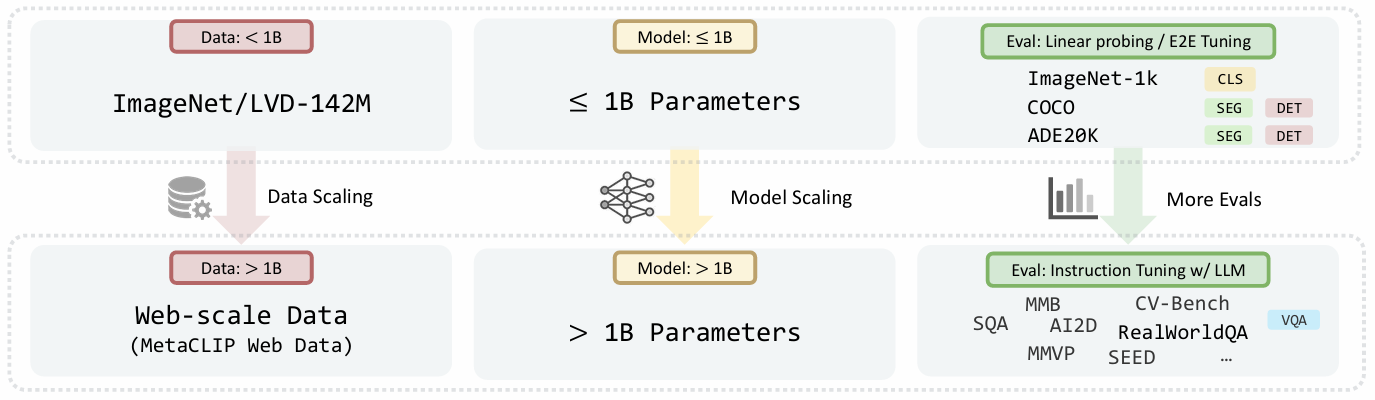
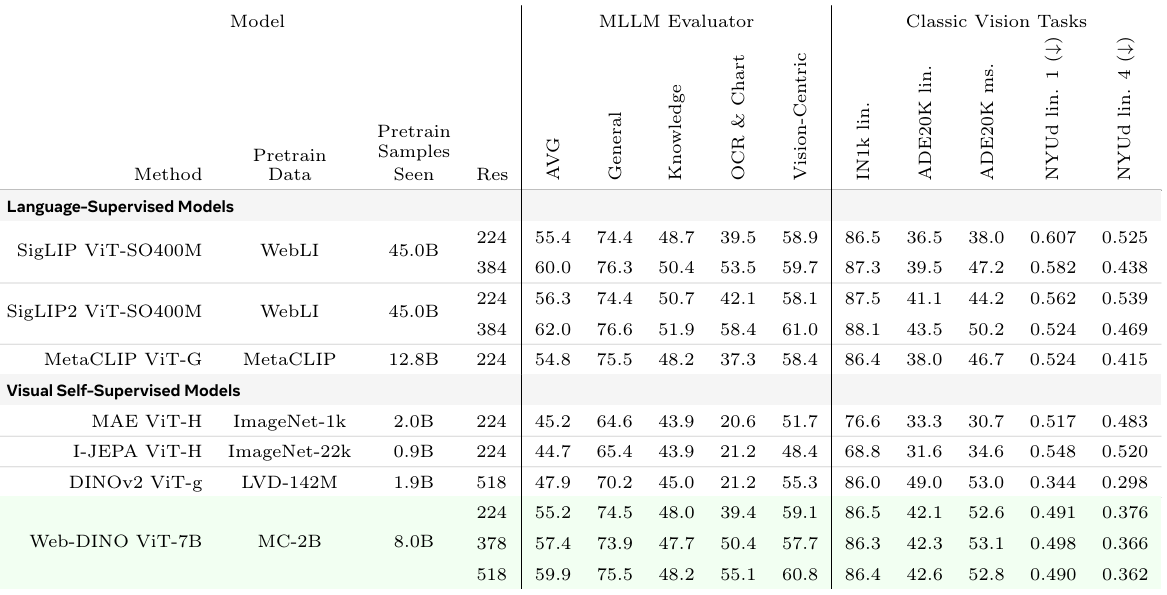
Scaling Language-Free Visual Representation Learning
方法:论文通过大规模数据训练视觉自监督学习模型,并与语言监督的CLIP模型对比。发现视觉SSL在多模态任务上性能可达或超CLIP,尤其在OCR和图表理解任务中。这表明在大数据和大模型支持下,纯视觉自监督学习能为多模态任务提供强大视觉表示。
创新点:
-
用大量网络数据训练SSL模型,多模态任务表现好,部分超过CLIP。
-
视觉SSL模型参数超10亿,大数据训练后性能提升,多模态应用强。
-
用文本多的图像数据训练,视觉SSL在OCR等任务表现更好,数据很关键。
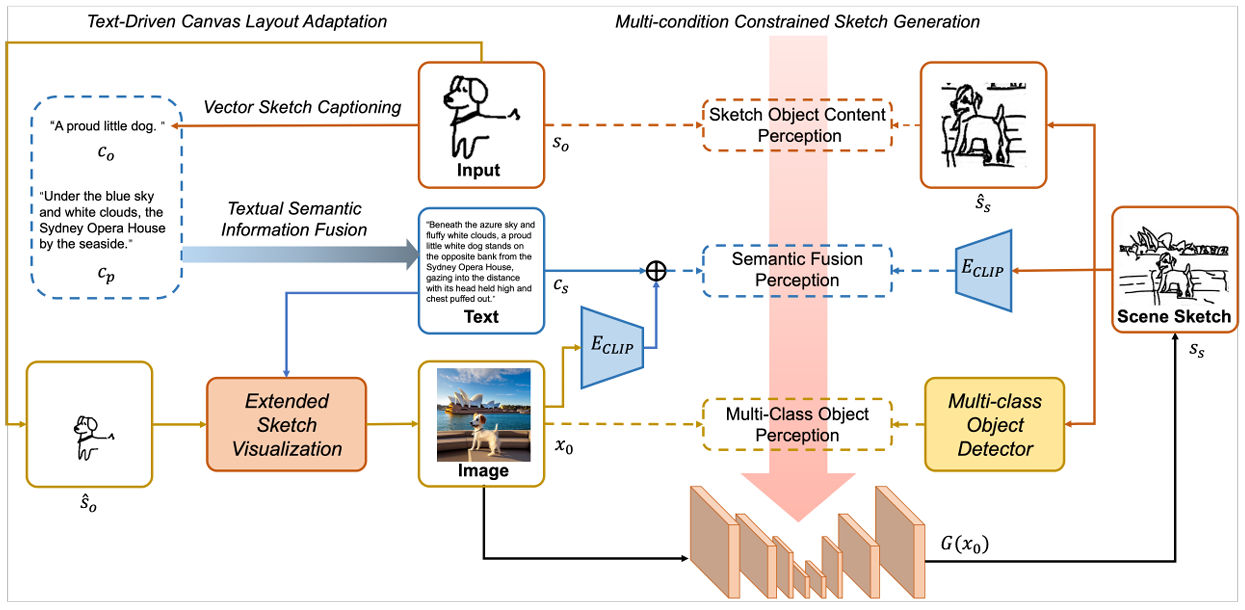
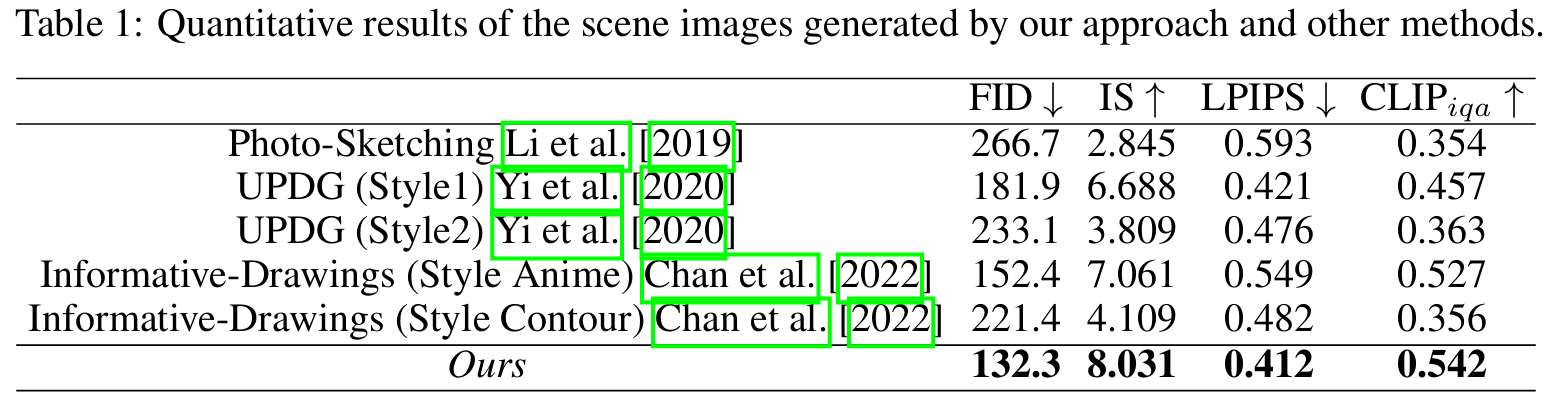
SketchTriplet: Self-Supervised Scenarized Sketch-Text-Image Triplet Generation
方法:论文提出了一种多模态自监督学习方法,将单物体草图扩展为场景草图。通过提取草图的语义信息、调整布局,并结合文本和图像的多模态约束进行生成,最终同时生成了语义一致的“文本-草图-图像”三元组数据集。
创新点:
-
提出向量草图描述方法,从单物体草图提取语义并扩展为场景描述。
-
设计了文本驱动的画布布局调整模块,用于调整单物体草图的布局,使其更适合场景草图的生成。
-
利用多模态感知约束生成场景草图,实现了从单物体草图到场景草图的自监督生成。
MENTOR: Multi-level Self-supervised Learning for Multimodal Recommendation
方法:论文提出了一种名为MENTOR的多模态推荐方法,它通过多级自监督学习任务对齐不同模态的特征,同时保留重要的历史交互信息。该方法从异构、同构图提取多模态特征,并通过多级跨模态对齐任务优化特征分布,还设计了可选的通用特征增强任务来提升模型的鲁棒性。
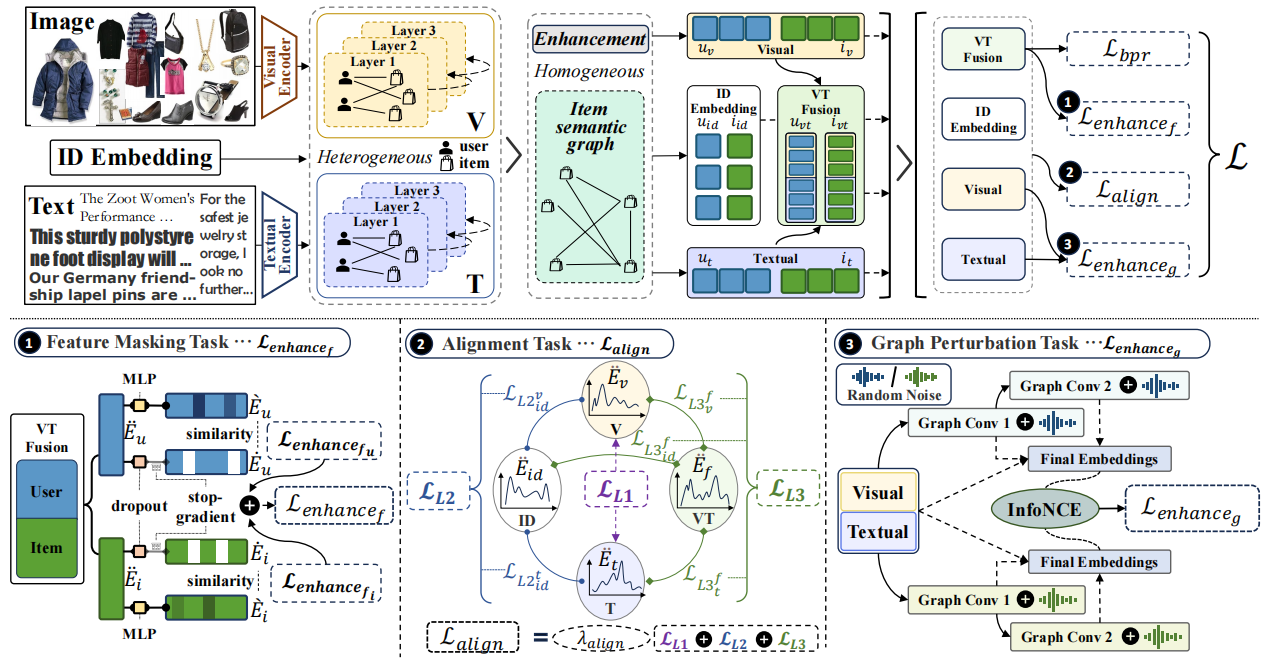
创新点:
-
提出多级自监督学习任务,对齐多模态特征并保留交互信息。
-
设计了一个可选的通用特征增强任务,进一步提升了模型的性能。
-
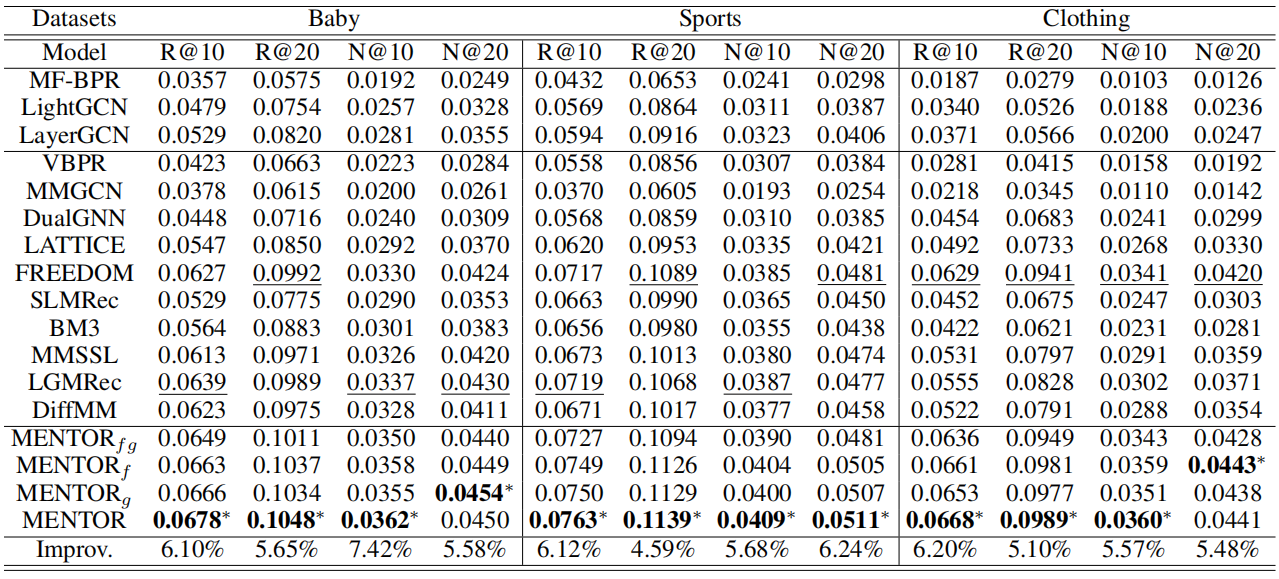
实验验证了MENTOR在整体和组件层面的有效性,证明了其在多模态推荐领域的优越性能。
ARNet: Self-Supervised FG-SBIR with Unified Sample Feature Alignment and Multi-Scale Token Recycling
方法:论文提出了一种名为ARNet的FG-SBIR方法,通过多模态自监督学习实现草图与图像特征对齐。其主要方法包括:双权重共享网络优化特征一致性,对比损失函数优化样本内外特征分布,以及多尺度令牌回收模块提升特征表示能力。
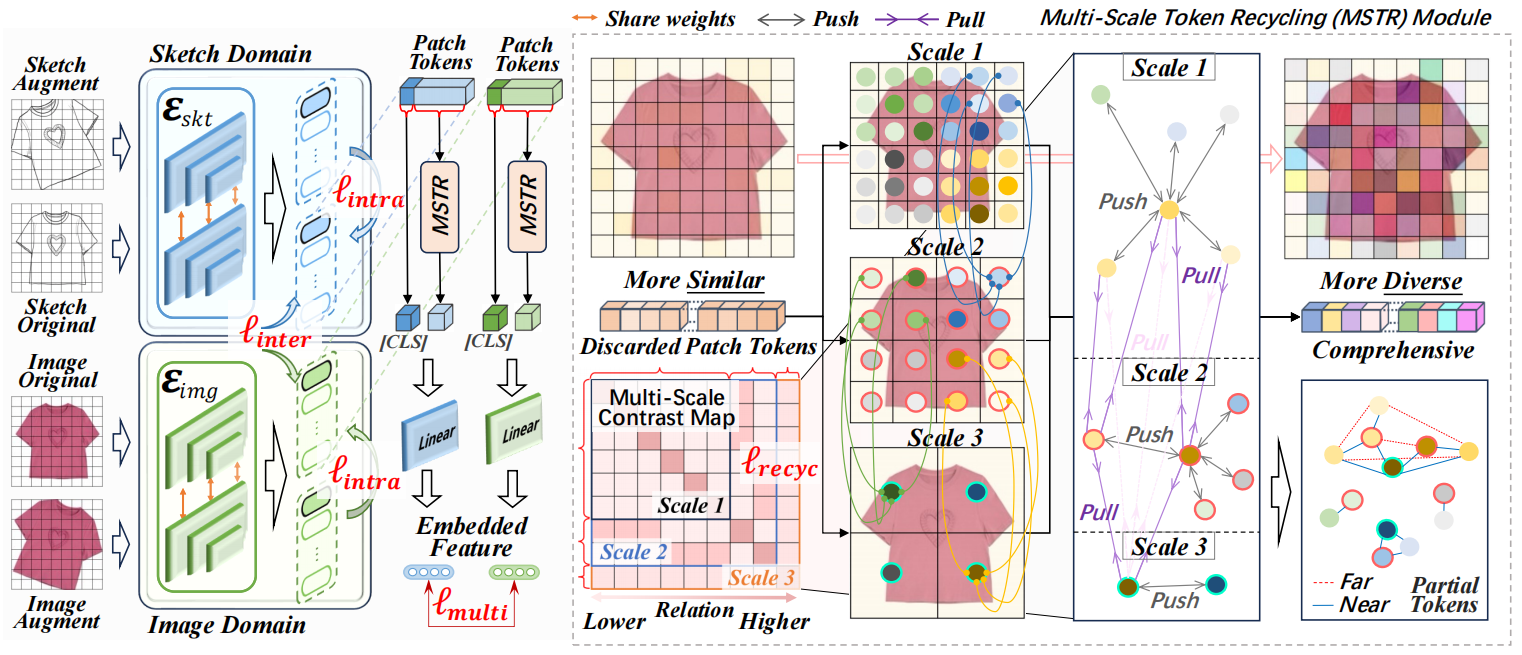
创新点:
-
通过双权重共享网络优化草图和图像域内的特征对齐,增强特征一致性,有效缓解模型学习饱和问题。
-
引入基于对比损失的目标优化函数,同时优化样本内和样本间的特征分布,提升模型的特征对齐能力。
-
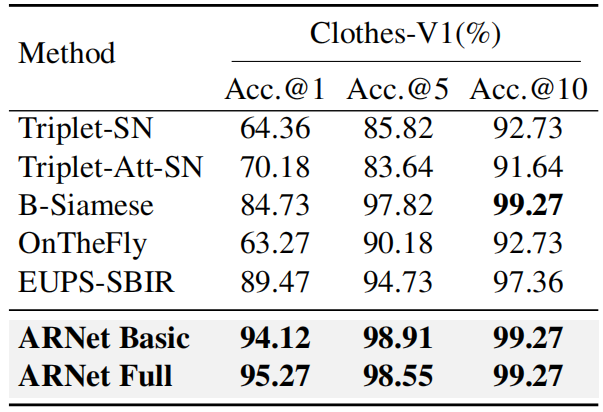
提出MSTR模块,通过回收被丢弃的Patch Tokens并利用多尺度对比学习过滤相似特征,保留独特特征,增强模型的特征表示能力和检索性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









