







一、题目
设想你是工厂的生产主管,你有一些芯片在两次测试中的测试结果。对于这两次测试,你想决定是否芯片要被接受或抛弃
数据集:ex2data2.txt
2、解题
1、导入数据
data = pd.read_csv(path,names=['test 1','test 2','Accepted'])
print(data.head())
使用data.head() 查看数据是否正确,表头是否添加
2、可视化数据
#数据可视化
fig,ax = plt.subplots()
ax.scatter(data[data['Accepted']==0]['test 1'],data[data['Accepted']==0]['test 2'],c='r',marker='x')
ax.scatter(data['test 1'][data['Accepted']==1],data['test 2'][data['Accepted']==1],c='b',marker='o')
ax.plot()
plt.show()
将内部点全部分为通过和未通过两部分使用不同的方式绘制在散点图上
可以看出数据大致是线性不可分的情况
3、特征映射(*与线性可分不同,需要更高的维度进行计算)
需要将x1,x2生成更高次幂的数据,然后再进行计算
def feature_mapping(x1,x2,power):
dic = {}
#通过双重循环,设置映射集
for i in np.arange(power+1):#0~power
for j in np.arange(i+1):
#将生成的映射放到dic中,对每个dic起一个名字 F**
dic['F{}{}'.format(i-j,j)]=np.power(x1,i-j)*np.power(x2,j)
return pd.DataFrame(dic)#转成DataFream格式
#测试
x1 = data['test 1']
# print('x1=',x1)
x2 = data['test 2']
# print('x2=',x2)
dic = feature_mapping(x1,x2,6)
# print(dic.head())
4、构造数据集(注意数据集是从特征映射的集合中取值)
X = dic
X = X.values
print(X.shape)
y = data.iloc[:,-1]
y = y.values
y = y.reshape(len(y),1)
5、构造代价函数(注意,增加了正则化项)
代价函数公式:
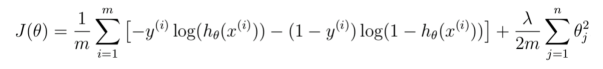
Lamda 越小,越易过拟合
Lamda越大,越易欠拟合
#创建sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))
#代价函数,与之前的相比,加入了正则化项
def costFunction(X,y,theta,lamda):
A = sigmoid(X@theta)
first = y*np.log(A)
second = (1-y)*np.log(1-A)
reg = np.sum(np.power(theta[1:],2))/(lamda*(2*len(X))) #正则化项
return -np.sum(first+second)/len(X)+reg
#测试代价函数
theta = np.zeros((28,1))
lamda = 1
cost_init = costFunction(X,y,theta,lamda)
print(cost_init)
6、构造梯度下降函数:
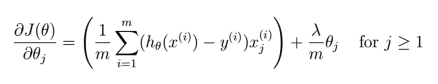
由于函数在正常函数之后加入了正则化项,所以梯度下降函数也要做出相应的改动
def gradientDescent(X, y, alpha, theta, iters, lamda):
costs = []
for i in range(iters):
# 插入正则化项:
reg = theta[1:] * (lamda / len(X))
# 因为reg是(27,1)而theta是(28,1)所以要在第一行插入(0)
reg = np.insert(reg, 0, values=0, axis=0) # 注意语法
A = sigmoid(X @ theta)
theta = theta - (X.T @ (sigmoid(X @ theta) - y))*alpha / len(X) - reg
cost = costFunction(X, y, theta, lamda)
costs.append(cost)
if i % 10000 == 0:
print(cost)
return costs, theta
计算得出theta数值和对应的代价函数序列
查看计算结果:
#梯度下降
theta = np.zeros((28,1))
alpha = 0.001
iters = 200000
lamda = 0.001
costs,theta_final = gradientDescent(X,y,alpha,theta,iters,lamda)
print(theta_final)
初始这只theta维度和X行维度相同,alpha以及lamda为0.001,迭代200000次计算得出最终结果
7、将结果以及数据一起展示出来:
x = np.linspace(-1.2,1.2,200)#在-1.2-1.2之间生成200个点
xx,yy = np.meshgrid(x,x) #将xx,yy定义为200*200的网格
z = feature_mapping(xx.ravel(),yy.ravel(),6).values #将xx,yy中的数据转为一位数组,并将xx,yy进行映射
zz = z@theta_final #映射之后进行计算曲线
zz = zz.reshape(xx.shape)#维度更新
fig,ax = plt.subplots()
ax.scatter(data[data['Accepted']==0]['test 1'],data[data['Accepted']==0]['test 2'],c='r',marker='x')
ax.scatter(data[data['Accepted']==1]['test 1'],data['test 2'][data['Accepted']==1],c='b',marker='o')
plt.contour(xx,yy,zz,0)#绘制三维图像,xyz三个轴选择最内层
plt.show()
注意此图是xx、yy经过特征映射得到z之后运算得到zz得到一条线为边界线
结果:
总体代码:
# Python TR
# Time:2020/12/11 8:29 下午
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#导入数据
path = '/Users/fengxiaolin/Library/Containers/com.kingsoft.wpsoffice.mac/Data/Library/Application Support/Kingsoft/WPS Cloud Files/userdata/qing/filecache/唐荣的云文档/00000研究生/机器学习/课后题资料/02-logistic_regression/ex2data2.txt'
data = pd.read_csv(path,names=['test 1','test 2','Accepted'])
print(data.head())
#数据可视化
#特征映射
def feature_mapping(x1,x2,power):
dic = {}
#通过双重循环,设置映射集
for i in np.arange(power+1):#0~power
for j in np.arange(i+1):
#将生成的映射放到dic中,对每个dic起一个名字 F**
dic['F{}{}'.format(i-j,j)]=np.power(x1,i-j)*np.power(x2,j)
return pd.DataFrame(dic)#转成DataFream格式
#测试
x1 = data['test 1']
# print('x1=',x1)
x2 = data['test 2']
# print('x2=',x2)
dic = feature_mapping(x1,x2,6)
# print(dic.head())
#构造数据集
X = dic
X = X.values
print(X.shape)
y = data.iloc[:,-1]
y = y.values
y = y.reshape(len(y),1)
#创建sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))
#代价函数,与之前的相比,加入了正则化项
def costFunction(X,y,theta,lamda):
A = sigmoid(X@theta)
first = y*np.log(A)
second = (1-y)*np.log(1-A)
reg = np.sum(np.power(theta[1:],2))*(lamda/(2*len(X))) #正则化项
return -np.sum(first+second)/len(X)+reg
#测试代价函数
theta = np.zeros((28,1))
lamda = 1
cost_init = costFunction(X,y,theta,lamda)
# print(cost_init)
def gradientDescent(X, y, alpha, theta, iters, lamda):
costs = []
for i in range(iters):
# 插入正则化项:
reg = theta[1:] * (lamda / len(X))
# 因为reg是(27,1)而theta是(28,1)所以要在第一行插入(0)
reg = np.insert(reg, 0, values=0, axis=0) # 注意语法
A = sigmoid(X @ theta)
theta = theta - (X.T @ (sigmoid(X @ theta) - y))*alpha / len(X) - reg
cost = costFunction(X, y, theta, lamda)
costs.append(cost)
if i % 10000 == 0:
print(cost)
return costs, theta
#梯度下降
theta = np.zeros((28,1))
alpha = 0.001
iters = 200000
lamda = 0.001
costs,theta_final = gradientDescent(X,y,alpha,theta,iters,lamda)
print(theta_final)
x = np.linspace(-1.2,1.2,200)#在-1.2-1.2之间生成200个点
xx,yy = np.meshgrid(x,x) #将xx,yy定义为200*200的网格
z = feature_mapping(xx.ravel(),yy.ravel(),6).values #将xx,yy中的数据转为一位数组,并将xx,yy进行映射
zz = z@theta_final #映射之后进行计算曲线
zz = zz.reshape(xx.shape)#维度更新
fig,ax = plt.subplots()
ax.scatter(data[data['Accepted']==0]['test 1'],data[data['Accepted']==0]['test 2'],c='r',marker='x')
ax.scatter(data[data['Accepted']==1]['test 1'],data['test 2'][data['Accepted']==1],c='b',marker='o')
plt.contour(xx,yy,zz,0)#绘制三维图像,xyz三个轴选择最内层
plt.show()














 4529
4529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









