







参考文档:详解Transformer
1、开局来一张Transformer的整体结构图
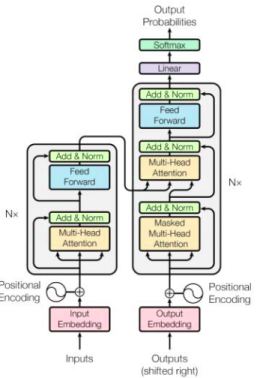
2、结构图每步分析
1、Encoder
1、Input Embedding
就是对输入的数据进行向量化编码,可能是one-hot等等
2、Positional Encoding
主要目的是对输入数据的位置有一个确定的前后关系
因为在Self-Attention中,没有考虑到前后位置关系,而是直接从总体进行学习的,因此此处需要加一个可以前后位置关系的表示,在论文中使用的是以下方法:
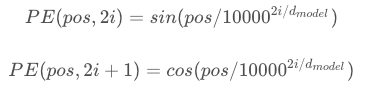
(1)使用了偶数位置用sin,奇数位置用cos的方式表示了位置的前后关系
(2)然后将位置向量与编码进行相加,得到完整的编码

3、然后向量就输入进了Encoder层
encoder层其实长这样:

简单点说就是一个Self-Attention,一个Feed Forward(前向传播)
(1)首先介绍一下Self-Attention
self-attention,其思想和attention类似,但是self-attention是Transformer用来将其他相关单词的“理解”转换成我们正在处理的单词的一种思路
The animal didn’t cross the street because it was too tired
这里的it到底代表的是animal还是street呢,对于我们来说能很简单的判断出来,但是对于机器来说,是很难判断的,self-attention就能够让机器把it和animal联系起来,接下来我们看下详细的处理过程。
————————————————
版权声明:本文为CSDN博主「爱编程真是太好了」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012526436/article/details/86295971
Self-Attention与Multi-Head Attention详见李宏毅篇
这给我们留下了一个小的挑战,前馈神经网络没法输入8个矩阵呀,这该怎么办呢?所以我们需要一种方式,把8个矩阵降为1个,首先,我们把8个矩阵连在一起,这样会得到一个大的矩阵,再随机初始化一个矩阵和这个组合好的矩阵相乘,最后得到一个最终的矩阵。

multi-headed attention的全部流程:

4、进入了Add&Norm层,即Layer normalization层
在transformer中,每一个子层(self-attetion,ffnn)之后都会接一个残缺模块,并且有一个Layer normalization
首先理解一下BN层(Batch Normalization)
BN的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。
BN的具体做法就是对每一小批数据,在批这个方向上做归一化。如下图所示:
可以看到,右半边求均值是沿着数据 batch_size的方向进行的
公式:

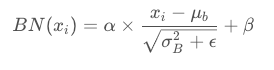
然后解释一下Layer Normalization:

公式:
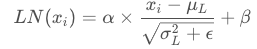
很容易可以看出,与BN层按批次进行不同,其就是在样本上进行计算均值和方差。
5、将数据传入前向传播网络即可
6、Encoder叠加:

2、DeCoder
可以看出,其实Decoder中也是很多Attention与Normalization,只不过是在第一层有了一个Mask,所以着重讲一下Mask这一项关键技术
1、Mask技术:
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
Mask分为两种,一种是Padding Mask,一种是Sequence mask
Padding Mask
因为输入的句子长短不一的问题,我们需要给输入的数据进行合理的编码,使其长度一致,因此,我们在较短的句子末尾加0,使得他们的长度一样。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
(self-attention中,Q和K在点积之后,需要先经过mask再进行softmax,因此,对于要屏蔽的部分,mask之后的输出需要为负无穷,这样softmax之后输出才为0。)
Sequence mask
Sequence mask主要是为了让Decoder不能看见未来的信息,只能由此时刻之前的时刻的信息来进行分析
为什么需要Mask?
比如我们要翻译I Love you now

S是开始符,E是结束符
如果没有Mask,采用与Encoder相同的多头注意力机制,其效果如下:

所有的单词都会为生成YOU提供信息
但是在生成这个单词的时候,我们是没有后面的 You,NOW的信息的
因此就会出现在训练的时候可以看到YOU NOW的情况,在生成的时候看不到,效果就不好,因此在预测的时候将其隐藏起来即可
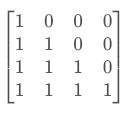
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。















 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









