







1、seq2seq简介
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。如下图所,输入的中文长度为4,输出的英文长度为2。
在网络结构中,输入一个中文序列,然后输出它对应的中文翻译,输出的部分的结果预测后面,根据上面的例子,也就是先输出“machine”,将"machine"作为下一次的输入,接着输出"learning",这样就能输出任意长的序列。
机器翻译、人机对话、聊天机器人等等,这些都是应用在当今社会都或多或少的运用到了我们这里所说的Seq2Seq。

参考文档:seq2seq模型概述
2、目标函数数学表达
我们要找到一个需要优化的目标函数,即损失函数
因为是翻译模型,所以我们会有很多对翻译语句组合<x,y>,即翻译的句子和目标结果
要做到优化,则需要使用概率,将得到正确结果的概率最大就是我们想要的结果,即P(Y
|X):在给定输入集X的情况下,我们得到我们想要的目标结果Y的可能性,其展开就是其中每一个小子集概率相乘,p(y1|x1)*P(y2|x2)…,让其最大
当子项很多的时候,每个概率很小的话,这个值非常小,所以我们需要对其取对数log,就变成了相加的形式:
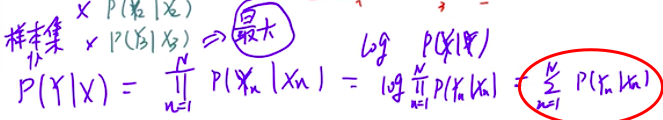
因此需要对P(yn|xn)的和求最大值,因为要做成损失函数所以取负数

接下来的问题就是如何求这个条件概率,就是怎么计算给出输入得到正确输出的概率
3、预测概率表达
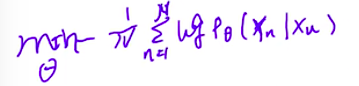

根据全概率公式:
我们可以计算出在已知Ai的情况下,B的概率
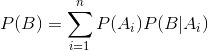
因此,上面的P(Y|X)可以进行递归展开:
例如,我们一直我翻译成I,求是翻译成am的概率:
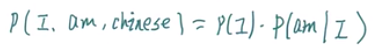
翻译I,am,Chinese的概率:
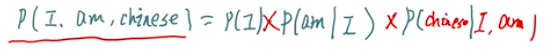
下一步就是这三个P咋计算
那么问题就是当我们知道了x,求得y1,y2,y3的概率
所以:
我们知道在进入解码之前要编码,所以我是中国人这句话是先要编码成为一个序列的
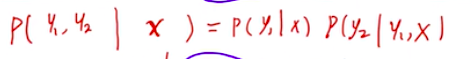
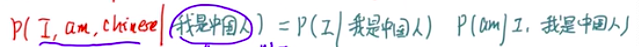
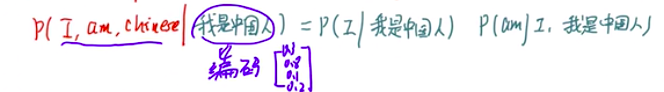
RNN神经网络中,输入的概率怎么计算?
即P(y1)、P(y2)。。。怎么计算
3、预测概率求法
在得到了各个y的值之后,经过一个线性层,会是和词典表里面的一个对应,例如:
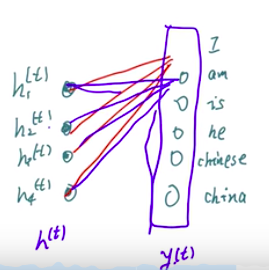
然后经过激活,把范围局限在0-1范围之内:
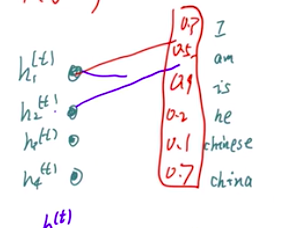
然后再经过一个softmax函数,进行归一化,就得到了各个预测的概率
4、Encoder网络结构
我们编码阶段是一个RNN结构,通过x和h不断向后传递得到hT:
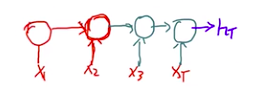
hT相当于包含了整个句子的所有信息
然后将hT进行变换,压缩到一个固定的长度,需要指定一下。
变换就是需要乘一个矩阵,比如50维变40维,就是乘一个50*40的矩阵(经过一个线性层)
得到固定维度之后,经过一个激活函数,得到C

使用tanh的目的:解决0中心问题,值有正有负,使用sigmoid函数,得到的值都是正的,有正有负梯度下降的速度就会比较快。
官方解释:Tanh函数是0均值的更加有利于提高训练效率,由于Sigmoid输出是在0-1之间,总是正数,在训练过程中参数的梯度值为同一符号,这样更新的时候容易出现zigzag现象,不容易到达最优值。
因为C保存的整个句子的信息,如果得到的hT是1500维的,变换成的C是500维的,则还需要进行一次变换,先进行一次全连接,然后进行一次激活
这样操作就会比较灵活
压缩使用的Word2vec算法














 1122
1122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









