







1、问题
我们从上一篇文章中可以看出,简单的线性模型造成了最终欠拟合(高偏差)的状态。要解决此情况就要使用高阶非线性曲线函数。
2、解决
1、如何发现高偏差/方差的情况:

因为目前还没有利用lamda,给定的特征也是固定的,所以采用第二种方式
2、构造多项式特征
多项式特征即为加入了多次方的x,然后使用theta判定每个次幂的权重,最终拟合出方程
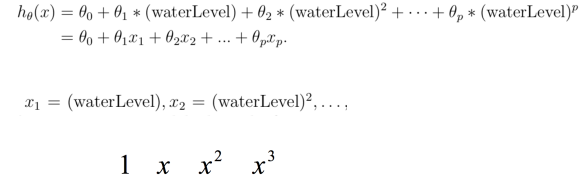
#构造多项式特征
def poly_feature(X,power):
for i in range(2,power+1):
X = np.insert(X,X.shape[1],np.power(X[:,1],i),axis=1)
return X
从二次方到6次方的值不断插入到X的最后一列
3、特征归一化
因为使用了多次幂,所以难免使得一些值过大或过小,归一化使其值停留在[-1,1]之间,使得快速学习
#特征归一化
#计算平均值与方差
def get_mean_std(X):
means = np.mean(X,axis=0)
stds = np.std(X,axis=0)
return means,stds
#归一化处理
def feature_normalize(X,means,stds):
X[:,1:] = (X[:,1:]-means[1:])/stds[1:]
return X
4、生成使用多次幂最终的theta_fit
power = 6
X_train_poly = poly_feature(X_train,power)
X_val_poly = poly_feature(X_val,power)
X_test_poly = poly_feature(X_test,power)
train_means,train_stds = get_mean_std(X_train_poly)
val_means,val_stds = get_mean_std(X_val_poly)
train_means,train_stds = get_mean_std(X_train_poly)
X_train_normal = feature_normalize(X_train_poly,train_means,train_stds)
X_val_normal = feature_normalize(X_val_poly,train_means,train_stds)
X_test_normal = feature_normalize(X_test_poly,train_means,train_stds)
theta_fit = train_model(X_train_normal,y_train,lamda=0)
- 不明白的一点是,为何xx和val、test的归一化全都用trainning的means与stds
5、使用theta_fit对多项式拟合,然后输出图像:
theta_fit = train_model(X_train_normal,y_train,lamda=0)
def plot_poly_fit():
plot_data(X_train,y_train)
x = np.linspace(-60,60,100)
xx = x.reshape(100,1)
# print(x)
xx = np.insert(xx,0,values=1,axis=1)
xx = poly_feature(xx,power)
xx = feature_normalize(xx,train_means,train_stds)#为何xx和val、test的归一化全都用train的means与stds
plt.plot(x,xx@theta_fit,'r--')
# plt.show()
plot_poly_fit()
结果:
可以看出,其对训练集数据拟合的非常好,几近于100%
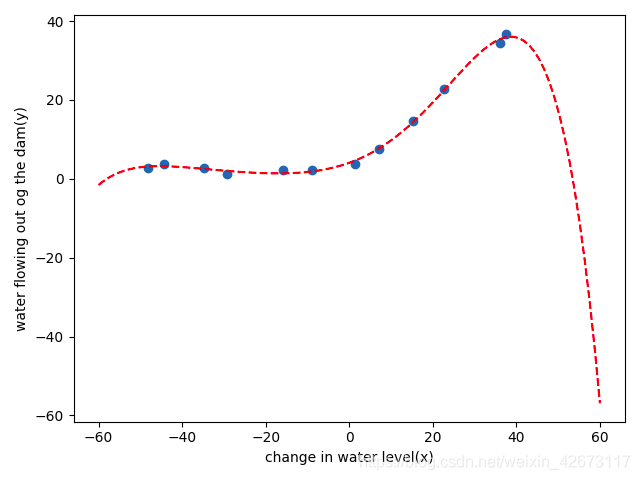
6、使用lamda=0与lamda=10分别训练模型,然后对trainning_cost与val_cost分别作图输出,查看代价情况
plot_learnning_curve(X_train_normal,y_train,X_val_normal,y_val,lamda=0)#过拟合
#高方差、过拟合,使用正则化方式进行解决即使用不同的lamda进行更正,lamda过小容易发生过拟合,过大容易发生欠拟合
plot_learnning_curve(X_train_normal,y_train,X_val_normal,y_val,lamda=10)#欠拟合
结果:
lamda=0:
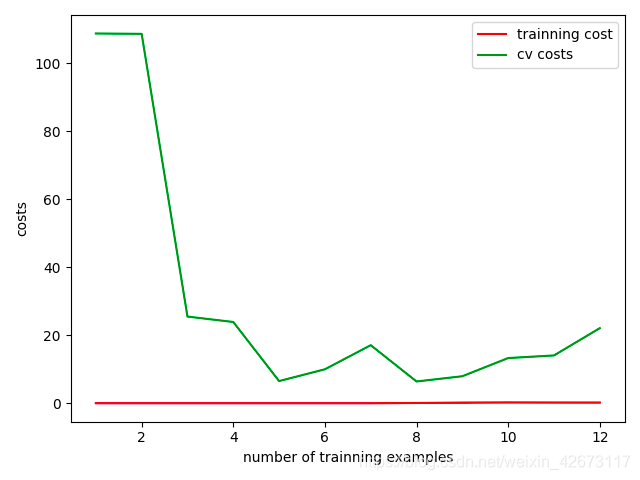
lamda=10
可以看出,一个trainning维持在0,cv不断波动且较大,为过拟合
另外一个=10 的二者均较大,为欠拟合
7、多个lamda选取输出:
#选择最优lamda解决问题
lamdas = [0,0.001,0.003,0.01,0.03,0.1,0.3,1,3,10]
train_cost = []
cv_cost = []
for lamda in lamdas:
res = train_model(X_train_normal,y_train,lamda)
tc = reg_cost(res,X_train_normal,y_train,lamda=0)#为啥lamda还是0?
cv = reg_cost(res,X_val_normal,y_val,lamda=0)
train_cost.append(tc)
cv_cost.append(cv)
plt.plot(lamdas,train_cost,label='train_cost')
plt.plot(lamdas,cv_cost,label='cv_cost')
plt.legend
plt.show()
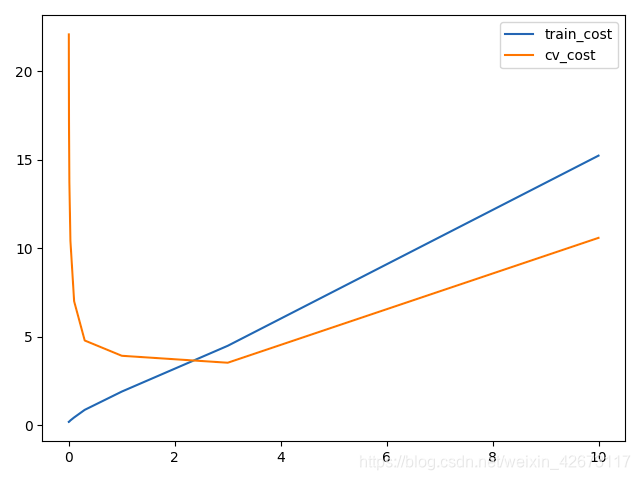
选取cv_cost较小的点进行输出
print(lamdas[np.argmin(cv_cost)])
结果为3














 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









